
Open-source distributed SQL Database
Joined February 2022
- Tweets 58
- Following 0
- Followers 278
- Likes 22
6 Photos and videos





Apr 30
YDB CLI now supports shell completion for bash and zsh.
When installing the CLI via the install script bit.ly/49nUOiT or updating the CLI, users will now be prompted to enable command completion.
Completion supports command tree, option names.
#distributedsql #ydbcli
5
2
96
Apr 20
A new post by @eivanov89 has arrived! Hot & fresh news about performance, tests and everything!
Apr 20

I’m excited to share a high-performance C TPC-C implementation for PostgreSQL — with a real-time terminal UI: watch tpmC, latency, and progress live. Built as part of ongoing YDB PostgreSQL compatibility work.
Thread 👇
1
85
Apr 18
We are glad to announce a new version of YDB Server 25.3.1.25. Binaries are available bit.ly/4dVoPtI
Please find the changelog here - bit.ly/4t0OaX7
Which feature do like the most? Your feedback is appreciated!
#distributedsql #ydb
1
1
4
215
YDBPlatform retweeted

Mar 24
io_uring easily beats AIO and gets faster with every kernel — until both suddenly get 30% slower.
Join a database developer’s unexpected journey into the Linux kernel and IOMMU.
medium.com/ydbtech/how-io-ur…
3
30
231
46,463
Feb 21
Starting with @linq2db v6.0.0, YDB is an official provider in linq2db/linq2db🚀
Backed by .Net YDB SDK, developers get type-safe LINQ with YDB support:
- generated YQL,
- type mapping,
- schema generation,
- Bulk Copy.
bit.ly/4tMId1r
3
107
9 Nov 2025
We would like to share amazing news: YDB toolkit now includes an adapter for DBT!
Check official DBT docs for more bit.ly/494xrM6
Consider reading YDB docs for quick how-tos bit.ly/3JtDeAy
Thanks @getdbt !
#distributedsql #bigdata
1
1
3
83
22 Jul 2025
Good news everyone!
We have released 🚀 YDB Server 25.1.2.7-rc – bit.ly/3IYowR6
Complete changelog is available in the docs section – bit.ly/4kOr69K
Which feature would you like to try first?
#ydb #distributedsql
2
5
193
30 Jun 2025
⚡️⚡️⚡️YDB Spark Connector v2 is released!
It is a production ready solution for working with YDB inside Apache Spark.
YDB Spark Connector supports parallel reading and writing to both row-oriented and column-oriented YDB tables.
Try out the new version! bit.ly/3G1DchC
1
9
137
18 Jun 2025
Our team have released YDB Server 24.4.4.12 - bit.ly/3FV1724
Full changelog is available on the web-site bit.ly/4jWBImv
Your feedback is appreciated!
2
7
132
15 May 2025
YDB core team contributor @eivanov89 has published new post in our blog about advantages one can gain from using YDB instead of sharding relational databases.
15 May 2025
Sharded Is Not Distributed: What You Should Know When PostgreSQL Is Not Enough
blog.ydb.tech/sharded-is-not…

1
4
176
YDBPlatform retweeted
12 Apr 2024
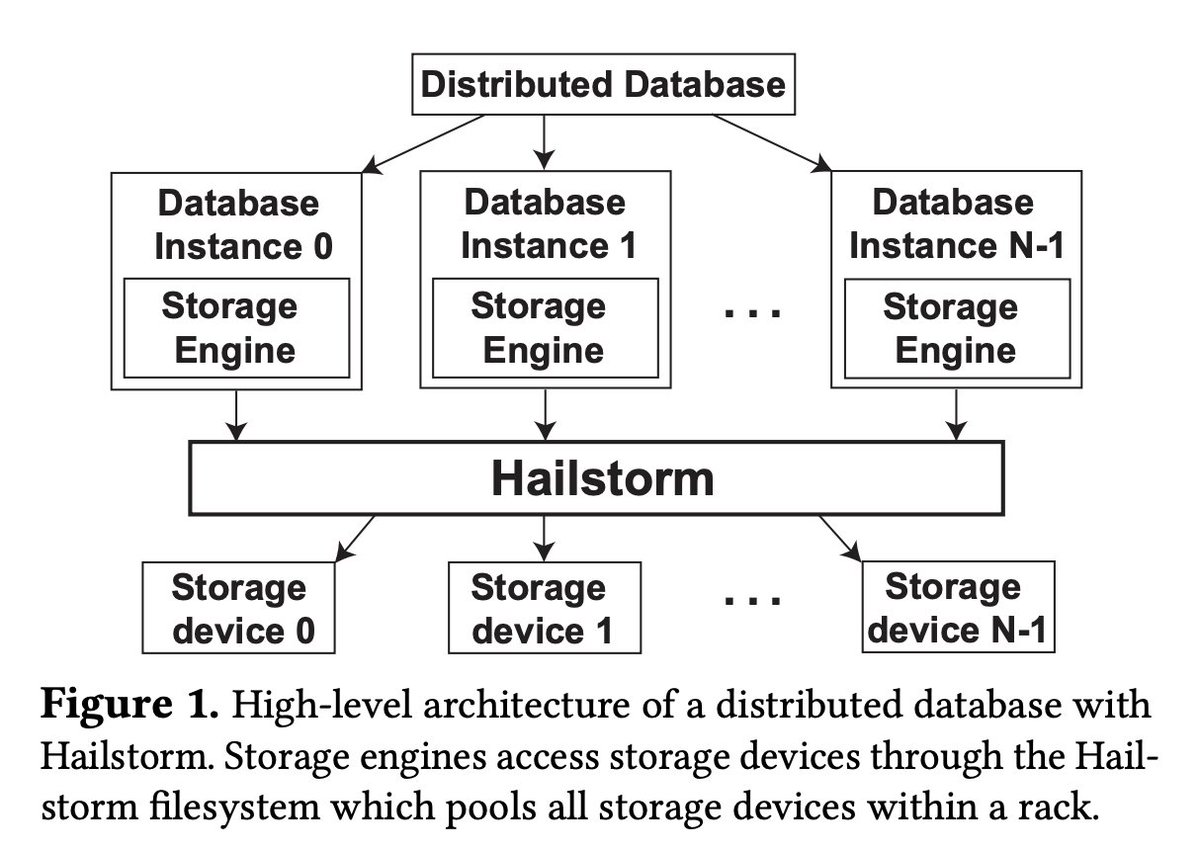
That's a very well-written paper from 2020 focusing on decoupling storage and compute in a distributed database. In their approach, they are very close to YDB. In YDB, the "Database layer" is built on top of distributed storage, which is somewhat similar to Hailstorm, because YDB fully disaggregates compute and storage - the main goal of Hailstorm. I would like to highlight some key differences between Hailstorm and YDB ⬇️
12 Apr 2024

Turns out people *are* in fact still thinking about distributed filesystems.
eecg.toronto.edu/~ashvin/pub…

3
18
177
40,063
YDBPlatform retweeted
31 Mar 2024
A very nice and informative post on secondary indexes in distributed databases. The only drawback is missing @YDBPlatform. YDB has an interesting approach with indexes: it offers a choice to its applications supporting both synchronous secondary indexes (similar to YugabyteDB, CockroachDB and TiDB, all mentioned in the post) as well as asynchronous secondary indexes. The consistency / performance tradeoff between these two options is described in the post in depth.
28 Mar 2024

✍️ Wrote a new database post!
This one is about the different ways that distributed databases handle secondary indexes.
@FranckPachot got me thinking about this topic a few weeks back after I wrote a piece on DynamoDB secondary indexes for @RocksetCloud.
Basically, distributed databases want to shard your data onto different machines. They use a shard key / function to determine which machine holds a given record.
But what happens when you have secondary indexes and queries that don't use your shard key?
Basically use the following flowchart:
First, does the database reshard items into new shards for secondary indexes?
- If yes, is resharding done synchronously during writes?
- If yes, then you have Yugabyte, Spanner, TiDB, etc.
- If no, then you have DynamoDB GSIs or Rockset
- If it's not resharded, are queries allow to span multiple shards?
- If yes, then you have MongoDB, Vitess, Cassandra, Elasticsearch
- If no, then you have DynamoDB LSIs
Walked through the benefits and drawbacks of each as well.
Let me know where I'm wrong!
2
1
4
1,924
YDBPlatform retweeted
19 Mar 2024
I'm thrilled to share with you an article "When Postgres is not enough: performance evaluation of PostgreSQL vs. Distributed DBMSs". Dive into an empirical study of @PostgreSQL, @CockroachDB and @YDBPlatform with the TPC-C benchmark and explore the intriguing trade-offs between reliability and performance in Postgres.
blog.ydb.tech/when-postgres-…
3
18
93
20,077
YDBPlatform retweeted
10 Jan 2024
In my latest post, I share my experience with #Java 21 virtual threads. I successfully transitioned the TPC-C benchmark from @CMUDB to virtual threads and encountered practical examples of deadlocks. Additionally, I shortly discuss fundamental aspects of sync/async programming and highlight the benefits of virtual threads.
Explore the details in the post: bit.ly/java-21-virtual-threa…
4
11
1,606
12 Jan 2024
📖 What's new in YDB documentation in December 2023: blog.ydb.tech/whats-new-in-y…
2
7
257
9 Oct 2023
💬 We’re launching a new communication platform for YDB community, a Discord server! Welcome: discord.com/invite/vnhG5akD
1
1
5
431
4 Oct 2023
We are excited to announce that next week YDB will be participating in #TechWeekSingapore. We will be happy to see you and answer all of your questions at G90 exhibition booth on 11-12th October. Grab complimentary tickets: gevme.com/CEA23/?promo=Exhib…
2
7
436