
Fair launch privacy since 2016 • ZK-powered shielded tx • No founders’ fee • Open, permissionless & community run • Classic ethos, modern roadmap • Reborn 2025
Joined October 2025
- Tweets 117
- Following 29
- Followers 184
- Likes 449
40 Photos and videos
















Pinned Tweet

23 Oct 2025
We’re back. Zclassic is the fair launch privacy chain no founders’ fee, just pure zk-tech and community.
Roadmap → zclassic.org • Join Telegram → t.me/zclassic_chat
#ZCL #Zclassic
11
10
48
5,699
Zclassic retweeted

Apr 5
THIS IS HOW A SENIOR ENGINEER ACTUALLY SCALES THEMSELVES WITH CLAUDE CODE
the biggest change with AI isn't coding faster. it's where you actually spend your time now.
more detailed prompts, more code review, more planning, less typing, etc.
here's the workflow:
this guy has been shipping code since the days of cgi and perl.
he uses a compound engineering plugin that runs 5 separate agents on every task.
one brainstorms, one plans the technical implementation, one executes, one reviews, one checks different verticals.
every step is documented in markdown files. it's slow and way more waiting. but the output quality is way higher because each agent is focused on one thing.
then the REAL multiplier is in git worktrees
if Claude Code made you 10x faster, worktrees multiplies that again depending on how many agents you can manage in parallel
his team runs 4-8 Claude Code sessions at the same time across different worktrees with each one working on a separate task.
the skill is managing multiple AI agents in parallel without losing track, that's the next evolution of engineering
133
88
1,307
158,895
Zclassic retweeted

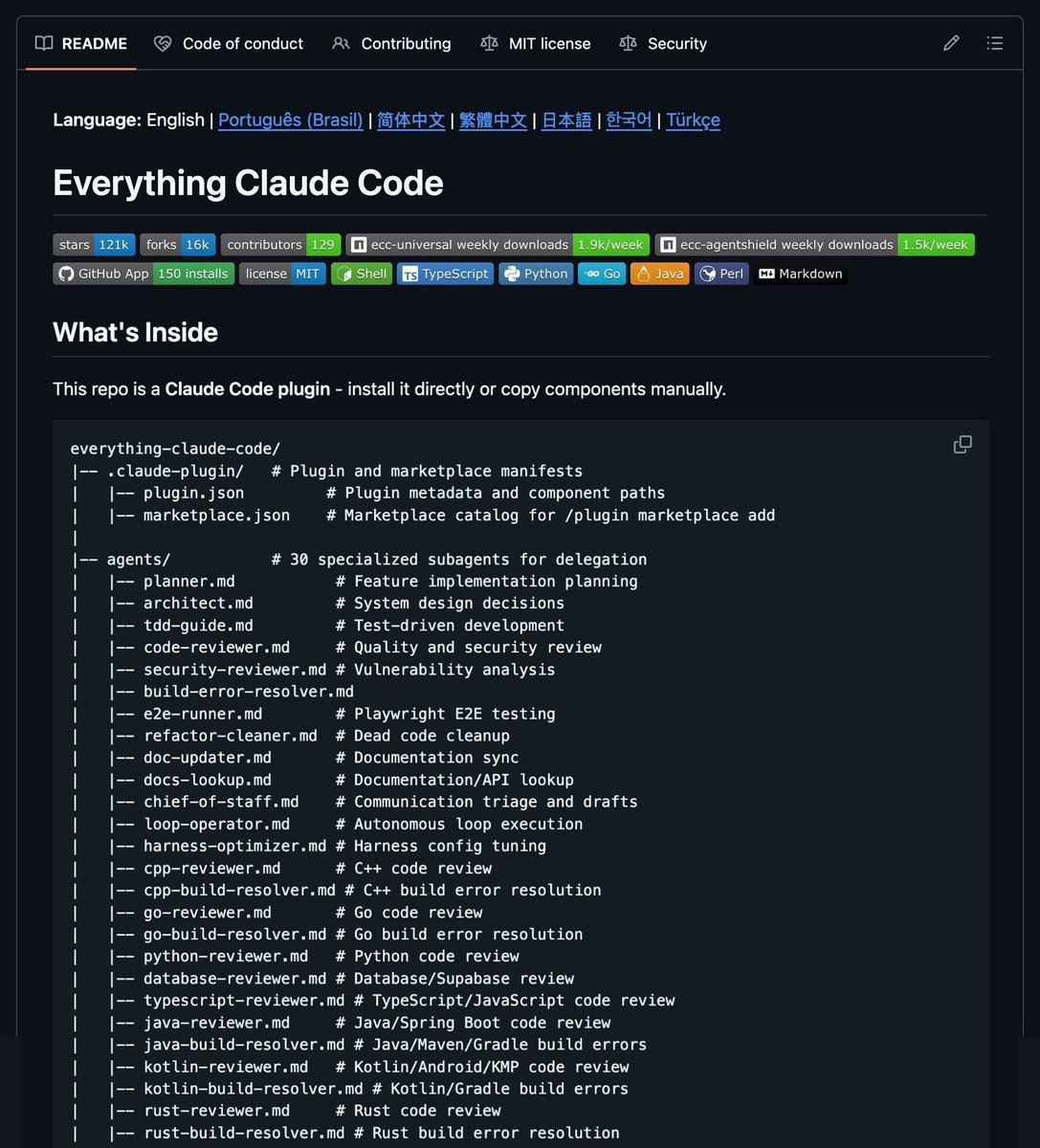
MOST COMPLETE CLAUDE CODE SETUP OPEN SOURCED
- 27 agents, 64 skills, 33 commands built-in AgentShield with 1,282 security tests
- Handles planning, code review, fixes, TDD, token optimization & more
- Works on Cursor, OpenCode, Codex CLI — one repo replaces weeks of setup, 100% free/open-source
Repo: github.com/affaan-m/everythi…
113
700
5,374
616,457

become a generalist.
specialization makes you efficient. generalization makes you dangerous.
what it actually means:
• learn across domains → math, physics, software, economics, biology. patterns repeat across fields.
• connect ideas → innovation happens at the intersection, not inside silos.
• adapt fast → when one field shifts, you don’t collapse, you pivot.
• see systems → specialists see parts, generalists see the whole
• build end-to-end → from idea → design → implementation → delivery
the world rewards specialists in stable environments.
it rewards generalists when things are changing.
right now, everything is changing.
don’t just go deep.
go wide, then stack depth where it matters.

207
983
5,181
259,794
Zclassic retweeted

Apr 4
🚨 do you understand what andrej karpathy just quietly published..
karpathy.. founding team at openai, former head of AI at tesla.. just said something that breaks the entire software industry in one paragraph..
in the LLM agent era.. there's less need to share specific code or apps.. instead you share the IDEA.. and the other person's agent customises and builds it for their specific needs..
let me show you why this is the most important thing posted online today..
the entire software industry is built on one assumption: building software is hard.. that's why you pay $49/month for notion.. $99/month for salesforce.. $299/month for whatever SaaS is sitting in your company's tab right now.. the scarcity of building = the value of the product.. it's been that way since 1995..
karpathy invented "vibe coding" in 2025.. the idea that you stop writing code and start describing what you want.. tools like cursor, claude code, and openclaw turned that into reality.. you talk to your computer.. it builds.. it ships.. it runs your workflows while you sleep..
and now he's saying even THAT is the old way..
now you don't share the app.. you share the IDEA FILE.. a document describing what you want to build and why.. and every person's AI agent reads it.. builds their own custom version.. tuned to their exact needs.. for free.. in minutes..
the scarcity of building just hit zero.
every SaaS company built for "normal users" is now competing against a blank text file and an agent with 4 hours to spare..
the winners of the next decade won't be the best builders..
they'll be the best thinkers.. the people who know what to build, why it matters, and how it should feel..
that's how paradigm shifts actually arrive.
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
94
203
1,863
536,030
Zclassic retweeted
Apr 4
SOMEONE VIBE CODED A TOOL THAT FINDS BUSINESSES, READS THEIR REVIEWS, AND WRITES COLD EMAILS BASED ON THEIR OWN CUSTOMERS' COMPLAINTS
this is insane. you type in any business type and pick a city.
it scrapes every matching business off Google Maps with 30 data fields.
then it visits their actual websites and pulls verified emails, phone numbers, and every social media profile they have
scraped live, not from some outdated database like other tools
then the AI reads up to 50 of their Google reviews and finds their exact pain points
"clients complain photos don't show the real size of properties" or "listings take too long to sell"
then you tell it what YOUR business does. it cross-references your offer with their specific problems and generates a fully personalized cold email for each business.
send it in 2 clicks. one by one and not bulk so it lands in the primary inbox
and all of those leads land on a GPS-mapped CRM where you can draw sales territories, optimize driving routes, track your team's activity in real time, and transcribe voice notes after meetings.
works in 200 countries and with any business type. if they're on Google Maps you can find them
this is the most complete lead gen tool i've ever seen
AND he vibe coded the whole thing with Claude Code in 2 weeks
179
390
5,904
597,514
Zclassic retweeted

Mar 23
This is BIG. It puts the spotlight back where it belongs: real utility. And that’s exactly where Zclassic wins.
New policy frameworks like Arizona’s SB1649 are shifting crypto away from hype and toward measurable value: transparency, fairness, real-world use. That’s a direct tailwind for projects built right from day one.
Zclassic fits perfectly:
No founder tax → fair distribution
Proven privacy tech (zk-SNARKs) → real financial freedom
Low supply → scarcity matters
Pure PoW → no insiders, no control
While most coins chase narratives, Zclassic already is one: fair, private, decentralized money.
This is how serious capital and real users start paying attention. To fundamentals.
No lobbying needed. No compromises. Just a protocol that stands on its own.
Zclassic is not noise. It’s what crypto was meant to be.
5
5
17
467

Zclassic retweeted
Mar 16
If you are looking for a diamond handed privacy coin, study Zclassic $ZCL
Over 80% supply has not moved for 1 year
And so much has been developed and new updates coming soon...

2
6
13
674
Zclassic retweeted
11 Dec 2025
No man should work for what another man can print - $ZCL Zclassic

6
14
490
Zclassic retweeted

18 Dec 2025

7
12
506

4 Dec 2025
Already done. It’s called #Zclassic $ZCL.
Same core tech as early #Zcash, but with 0 premine, 0 founders’ reward, 0 dev tax just pure PoW and a fair launch.
If you want “tech to the people”, it literally already exists.
4 Dec 2025

Can someone fork Zcash?
If the tech is good, we can use it. But the extremely predatory distribution and premine is not acceptable.
Tech to the people, with a fair launch!
1
6
17
558
26 Nov 2025
When you go down that rabbit hole you understand that you want to be holding the no vc, no pre-sale, community version, and that's #ZClassic $ZCL
24 Nov 2025

Balaji just exposed what's missing from crypto.
And he's NOT just talking about better tech.
He revealed that despite $2T in market cap, crypto has failed at its ONE ideological promise.
Here's what 99% of crypto missed: 🧵

4
6
17
460
26 Nov 2025
If you believe crypto should be fair, open, and community run… don’t just watch. Join us. t.me/zclassic_chat #ZClassic $ZCL $ZEC $ZEN #PrivacyMatters
3
7
13
339
24 Nov 2025
Movements are built by contributors, not spectators.
If you’re a developer looking for a fair launch chain with real history and zero politics #ZClassic is yours to help shape. #devs #vibecoding #OpenSource
3
13
375