
Joined June 2023
- Tweets 67
- Following 462
- Followers 88
- Likes 292
7 Photos and videos






ZeroKPunk retweeted

1 Jan 2025
Lambda is working on a few blog post that will explain different consensus algorithms. From Raft and Paxos to Tendermint, Hotstuff and Simplex.
I highly recommend you read about Simplex. It's simple and clear.

10
4
97
10,902
ZeroKPunk retweeted

11 Sep 2024
a thoughtful post by the daimo team on what their ideal solution for indexing crypto data would be -- and why Reth ExExes might be the solution.
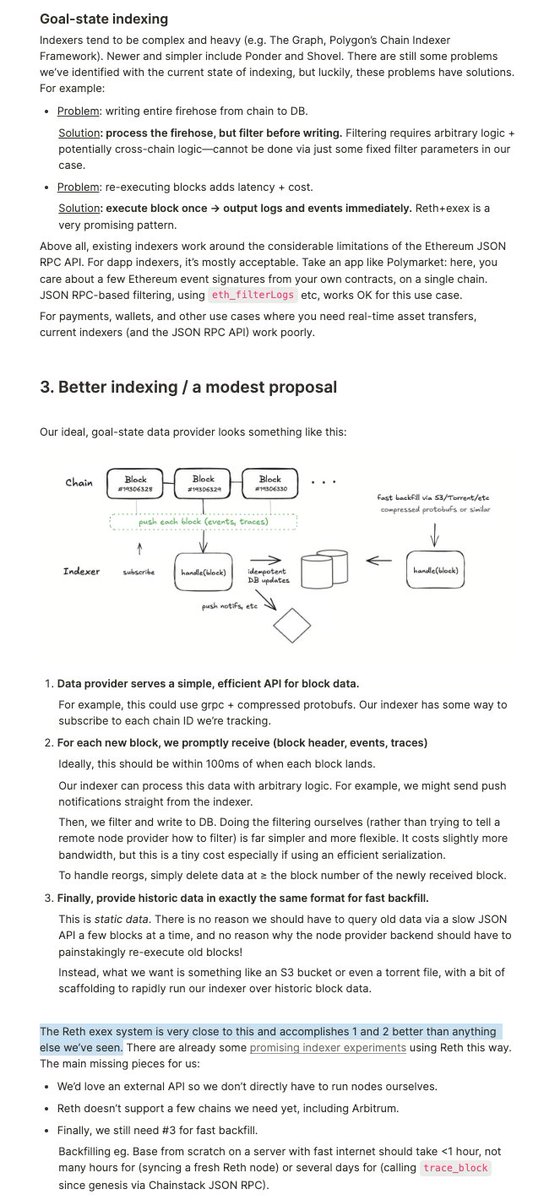

Indexing is key to great Ethereum apps. But it's harder than it should be!
Here's how we made ours work & what we'd like to see in the future: daimo.com/blog/posts/less-te…
5
12
125
26,815
ZeroKPunk retweeted

20 Aug 2024
TRUSTLESS ROLLUP INTEROPERABILITY
This article, co-authored with @_weidai, is meant to serve as a source of truth for builders and users interested in exploring trustless rollup interoperability.
1/10

5
17
102
20,334
ZeroKPunk retweeted

5 Aug 2024
How why we rewrote Circom in Rust 🦀
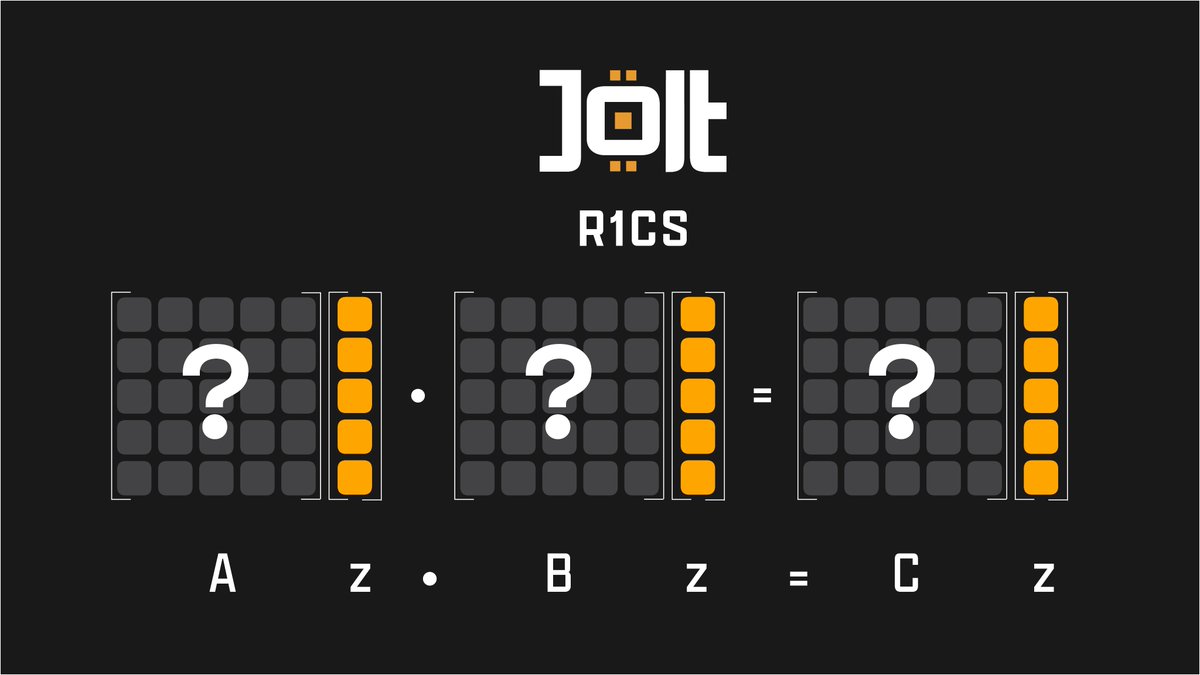
Jolt uses R1CS to constrain a subset of the VM's functionality to ensure that the virtual CPU's fetch-decode-execute loop is constrained to the RISC-V spec.
For example, we must ensure the 32-bit ELF row decodes correctly. Each 32-bit RV32I R-type instruction decodes to a tuple (rd, opcode, rs1, rs2). Jolt uses the unpacked versions of each of these in other constraints, so we'll need to constrain
instruction = rd || opcode || rs1 || rs2
In total we have around 30 individual constraints of similar format.
Constraints are expressed as a combination of degree-1 polynomials Az * Bz - Cz = 0. For example we might want to express that 4 8-bit field elements [Q_0, Q_1, Q_2, Q_3] pack into a 32-bit field element R, based on a condition S. In other words:
if (S) R == Q_0 || Q_1 || Q_2 || Q_3
In R1CS format:
Az = S
Bz = Q_0 2^8 * Q_1 2^16 * Q_2 2^24 * Q_3
Cz = R
Our full constraint: S * (Q_0 2^8 * Q_1 2^16 * Q_2 2^24 * Q_3 ) - R == 0
If S is one, R must be Q_0 || Q_1 || Q_2 || Q_3. We describe this state as the circuit being "satisfied".
Back to Jolt. Jolt is a multilinear SNARK so we'll need a multilinear prover. We started with Srinath Setty's Spartan as it was the fastest implemented multilinear SNARK. We started by using Circom to express all of the constraints described above.
But it was too slow! Jolt has 30 constraints per cycle of the CPU. At 2^24 steps the total number of constraints blows up to 2^29. The A, B, C matrices have dimensions:
- COLS = NUM_CYCLES * NUM_INPUTS
- ROWS = NUM_CYCLES * NUM_CONSTRAINTS
So the prover costs are increasing as a square of NUM_CYCLES... alarming.
@moodlezoup likes to say the only real optimization tool is taking advantage of repeated structure. Here we have 2^24 repeats of exactly the same fairly small computation. But we were outsourcing the load to Circom's libraries and improperly amortizing costs across these repeated cycles. To take full advantage of the structure, we knew we'd have to vertically integrate Circom.
Circom fundamentally performs two discrete functions for us:
1. DSL for describing linear combinations over the input variables
2. Computation of the witness z
Simple Symbolic DSL
For Jolt we defined a JoltIn enum of all the inputs to the circuit, then defined std::ops::{Add, Subtract, Multiply} over the enum and i64 constants. These aggregate into a LinearCombination struct which stores a vector of Term: (i64, JoltIn).
- JoltIn::A JoltIn::B -> LinearCombination = [(1, JoltIn::A), (1, JoltIn::B)]
- 12i64 * JoltIn::A -> LinearCombination = [(12, JoltIn::A)]
- 10i64 * LinearCombination - 12 -> LinearCombination = [(120, JoltIn::A), (-12, JoltIn::Constant)]
You can view this arithmetic as symbolic arithmetic in the variables JoltIn.
Now we can define constraints in natural language.
let packed == JoltIn::Q_0 2^8 * JoltIn::Q_1 2^16 * JoltIn::Q_2 2^24 JoltIn::Q_3;
cs.constrain_eq(packed, JoltIn::R);
Witness Computation
We can now compute the witness vector 'z' directly, using the relevant linear combinations.
let lc = vec![(120, JoltIn::A), (-12, JoltIn::Constant)];
let z_i = 120*JoltIn::A - 12;
By vertically integrating all of this logic we were able to take full advantage of the structure, accelerating key bottlenecks and increasing the readability of our constraint system (~100 LOC).
5
13
98
8,903
ZeroKPunk retweeted

25 May 2024
My advisor Alessandro Chiesa released a book, together with Eylon Yogev!
It covers *all* there is to know to build SNARGs and STARKs in the (pure) random oracle model, with explicit bounds and parameter-setting guidance.
Available (with source code!) at snargsbook.org 🧵

3
39
169
15,114

21 Jul 2024
Let’s start a prediction on @Polymarket , how many of them will work in the AI or Crypto in the next 5 years :)
21 Jul 2024

Congratulations to the US Math team beating China and claiming #1 in the world in IMO

1
343
6 Jul 2024
That is so called Gas Abstraction on ethereum L2 bro
6 Jul 2024

Our team is developing a new solution that enables gas-free stablecoin transfers. In other words, transfers can be made without paying any gas tokens, with the fees being entirely covered by the stablecoins themselves.
161
ZeroKPunk retweeted

2 Jul 2024
🥁New paper🥁
The Sum-Check Protocol over Fields of Small Characteristic, Joint with @SuccinctJT, links below.
Paper: eprint.iacr.org/2024/1046
Blog: Sumcheck and Open-Binius: hackmd.io/@suyash67/B1npBL_L…
Code: Smallfield-super-sumcheck: github.com/ingonyama-zk/smal…


2
19
105
11,403
ZeroKPunk retweeted

2 Jun 2024
Why aren’t more DeFi protocols using ZK co processors?
It seems like you could implement more complex pricing functions and better risk management with lower gas costs.
36
6
108
37,735
ZeroKPunk retweeted

21 May 2024
We just verified 100k bitcoin blocks using nova on optimism:
optimistic.etherscan.io/tx/0…
Total costs (c6i.4xlarge instance txs): 27,55$ 😎
Repo: github.com/dmpierre/sonobe-b…
cc @arnaucube
6
17
80
9,721
ZeroKPunk retweeted

16 May 2024
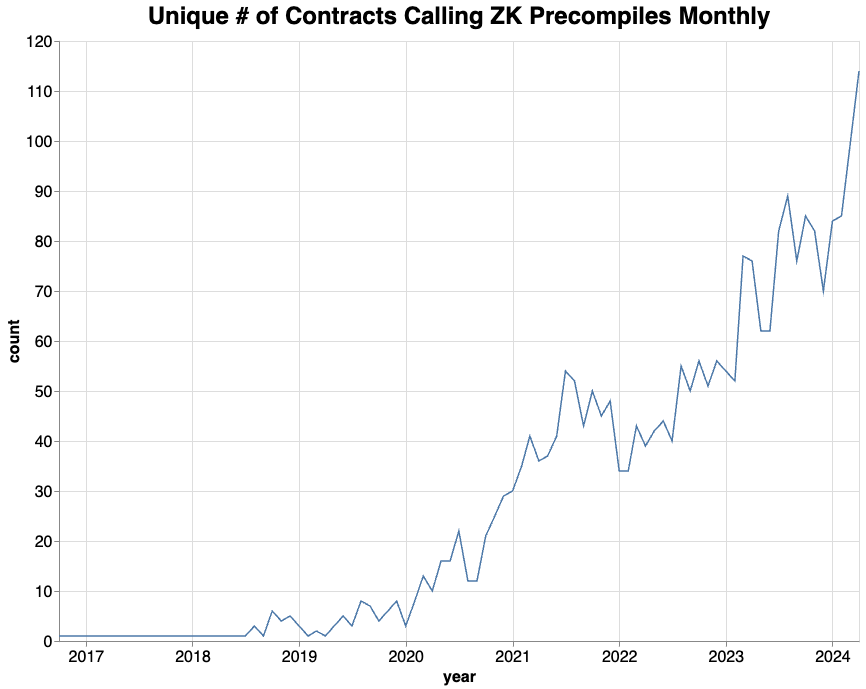
Zero knowledge tech is making rapid progress in the crypto world. You can look onchain to see who's using ZK.
Since Ethereum's launch, the # of unique contracts on mainnet Ethereum calling ZK related precompiles every month has grown steadily.
Let's dig in to the data!
6
35
195
45,291
ZeroKPunk retweeted

29 Apr 2024
What if… verifying the execution of pairings inside SNARKs can be done much faster than already known?
@AndrijaNovakov6 and @LiamEagen have just published a paper on this!
Let’s explore this below 🧵
1/13

3
27
139
38,274


8 Apr 2024
🫡🫡🫡
8 Apr 2024

Now, we are providing the GPU version of rapidsnark from @identhree by leveraging the ICICLE lib from @Ingo_zk to the ZK community, the proof generation time of Plonky2 recursion circuit is now from 41.757s to 8.443s, if you want to know more:
orbiter-finance.medium.com/g…
1
373
ZeroKPunk retweeted
4 Mar 2024
Say hello to STIR 🥣!
STIR is an IOPP for RS which, compared to FRI, has shorter arguments (~2x) and a faster verifier (~1.2x) that performs fewer hashes (~2x).
Joint work with Gal Arnon, Alessandro Chiesa and Eylon Yogev.
ia.cr/2024/390 - gfenzi.io/papers/stir

14
43
201
46,581
ZeroKPunk retweeted
4 Mar 2024
NEW @paradigm RESEARCH! ⛽⛽⛽
Today is an incredibly exciting day as we finally publish our detailed data-driven research on how to think about the growth of Ethereum's gas limit in the coming years.
Read on & share feedback with us.
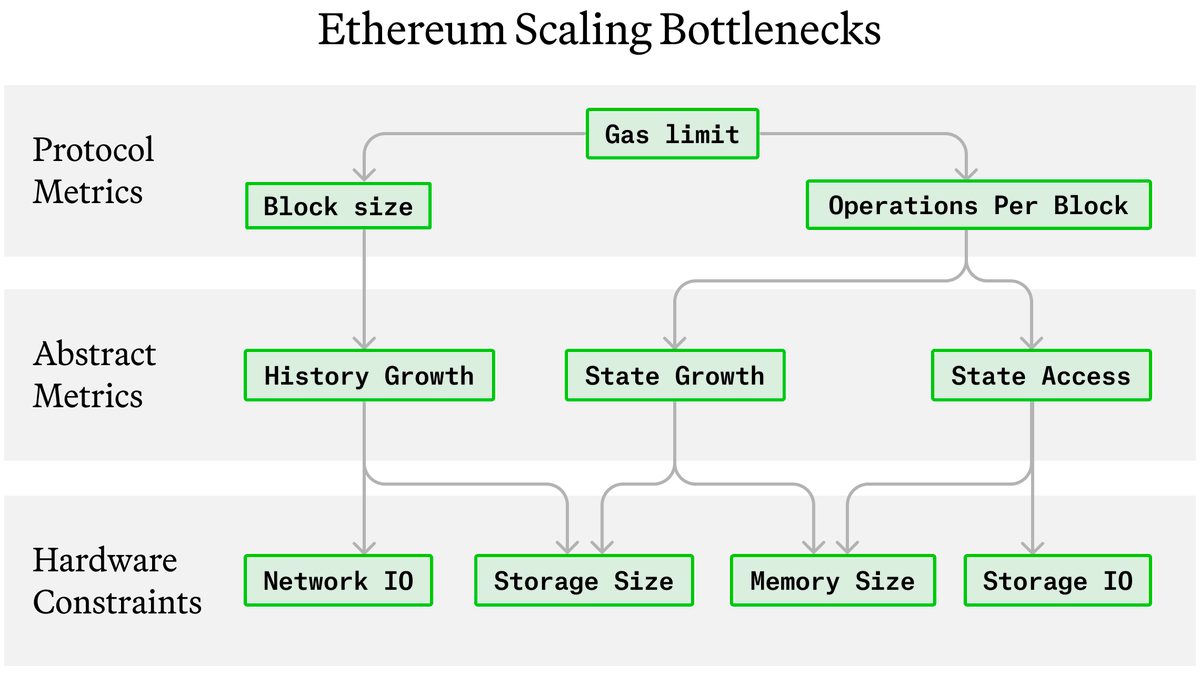
4 Mar 2024

new research from @paradigm: How to Raise the Gas Limit ⛽⛽
lots of people want to raise the gas limit, but so far most of the discourse has lacked detailed quantitative evidence
that ends today. we are making the scientific case for scaling Ethereum using ultra-high-res data
12
49
375
49,139