
00年|上交 x 帝国理工|AI Spark创始人|前微软&亚马逊产品经理|分享AI使用干货与商业化变现|wujingyisjtu@gmail.com
Joined May 2008
- Tweets 1,275
- Following 264
- Followers 11,716
- Likes 3,881
146 Photos and videos











整理一下这两周写的干货帖
manus实战案例:
1. 复刻爆款推文x.com/zesee/status/200390718…
2. 爬取结构化数据x.com/zesee/status/200425881…
3. manusbrower模式 收集小红书帖子数据 x.com/zesee/status/200742833…
提示词技巧:
1. 自用prompt技巧:x.com/zesee/status/200713425…
2. 不同模型得用不同prompt
x.com/zesee/status/200931320…
3. 让llm停止给情绪价值
x.com/zesee/status/200961867…
4. 提前复盘为什么某件事会失败
x.com/zesee/status/201020377…
VibeCoding实战分享:
1. 如何用boltnew像素级复刻网站
x.com/zesee/status/200809392…
2. 零帧起手一天做完一整个pitchdemo
x.com/zesee/status/200520142…

2025|自用 Prompt 技巧
⸻
1️⃣ 结构化思考链(不是“让它想”,而是“逼它自检”)
不用说一步步思考,而是用显式思考标签:
请在 <Reasoning> 中完成推理,
并在输出前进行一次自我校验。
作用只有一个:
强制 AI 检查逻辑断点,而不是顺着概率往下编。
📌 适合:复杂分析 / 策略判断 / 商业推演
⸻
2️⃣ 主动协作角色(给 AI「提问权」)
90% 的胡编,源于一个问题:
你没给够上下文,它又不敢问。
直接写进 Prompt:
如果信息不足,请先向我提出澄清问题,
在获得答案前不要做假设。
这一句,本质是把 AI 从
「算命模式」→「协作模式」
📌 适合:需求不清晰 / 产品设计 / 战略共创
⸻
3️⃣ RTF 框架(2025 仍然是最稳的万能公式)
R = Role|T = Task|F = Format
是降低模型理解歧义的最短路径。
直接可用模板:
你是一位资深数据科学家(Role),请分析这份市场数据并总结核心趋势(Task),请使用 Markdown 表格输出,包含「趋势名 / 影响程度 / 行动建议」三列(Format)。
📌 让模型知道「你是谁」「你要干嘛」「你要我怎么交付」。
19
47
233
87,151
这个卡真的很好用,当时在英国用了一年多,也是很多海外矩阵号必备

5
4
525
Rachel🥥 retweeted

Jun 12
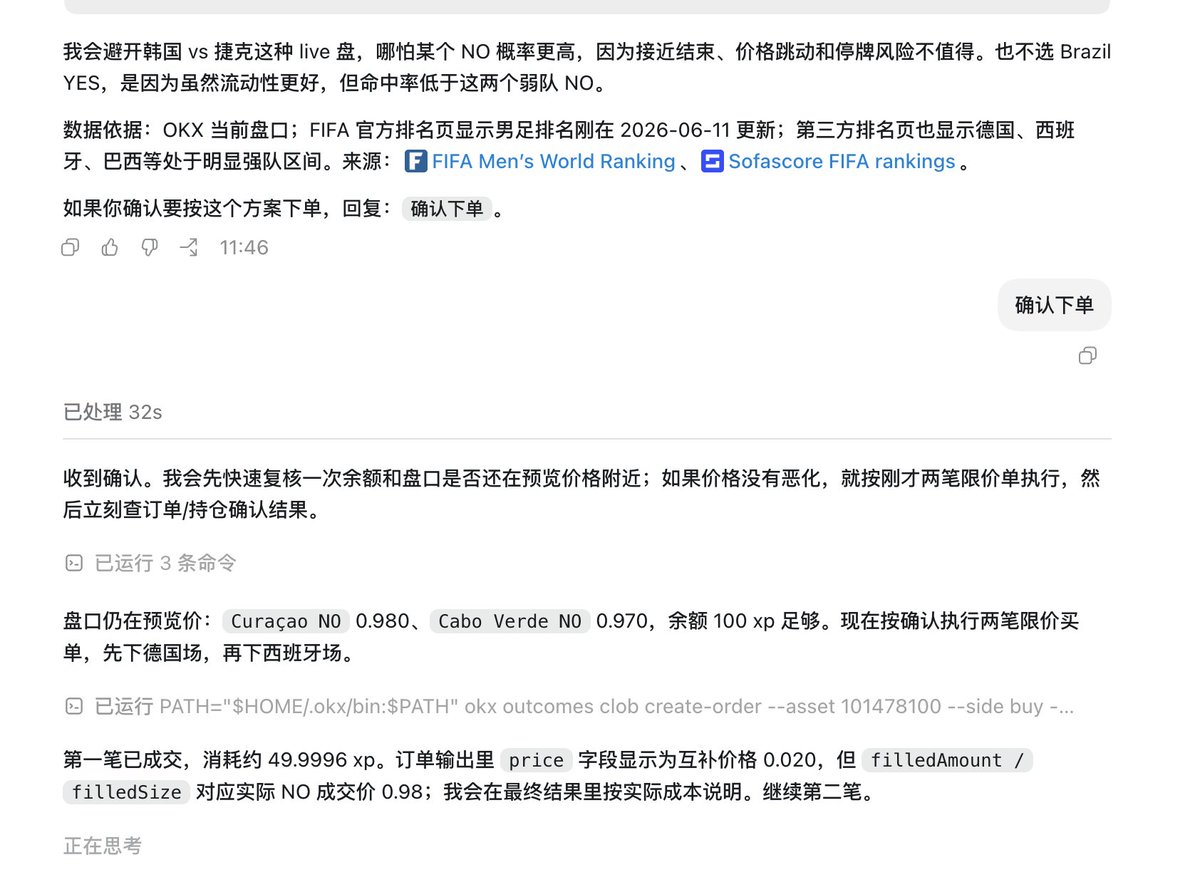
裸辞在家,在想怎么用AI帮我搞钱。然后看到了世界杯,我再试一下AI能否帮我预测中,但是我又不想花钱。
正好看到了这个OKX有这个世界杯预测活动,然后他们对Agent的支持也挺好,可以直接让AI去进行预测,于是我让Codex去玩一下,不知道他能我去瓜分多少BTC
codex帮我压力两场,德国和西班牙胜,可以说是相当保守了



36
9
42
9,787
这个dreaming的功能主要目的是帮助重度用户定期检查AI对用户本身的理解是否准确,以免影响到任务的效果。
需要定期清理AI的短期记忆,以免它固定住过去对用户的理解
4
2
681
Rachel🥥 retweeted

Jun 10
我是一个正在大学阶段不断摸索成长和副业路径的普通学生。曾经的我,脑子里总是有各种各样的想法,想做点能赚钱的事、想接一些有挑战的项目、想在平台上学习和成长,但这些想法大多停留在空想阶段。拖延像一层无形的网,把我困住,让执行力总是差那么一口气。每天刷刷信息、列列计划,感受感受fomo,却很少真正动手。结果就是焦虑越积越多,机会一次次溜走。
转机出现在大一升大二的那个暑假。我偶然接触到家教中介这个领域,发现通过平台撮合资源,确实有不错的盈利空间。为了不走弯路,我主动花钱向一位经验丰富的同行前辈学习整个流程,从找客户、匹配资源到交付闭环,一步步跟着他实操。起初,执行起来困难重重:很多事情不知道从哪里下手,面对实际操作时的各种细节,我总觉得“再准备一下”就好了,拖延的习惯像老朋友一样回来找我。
我很快意识到,对当时的我来说,单打独斗容易陷入死循环。于是我找了一个伙伴,一起推进这个项目。每天我们都遇到各种各样的问题,平台规则变化、客户需求调整、流程卡点、退费纠纷,但正因为有这些“麻烦”,我们被迫每天动手解决。忙碌取代了空想,执行力在一次次问题解决中被激活。那个暑假,我们最终赚到了小几万块钱。这不仅是我大学里的第一桶金,更重要的是,它让我第一次深刻感受到:
行动不是靠灵感爆发,而是靠把注意力放在自己能掌控的小步骤上,一点一点把事情推向现实。
有了这次经历,我后来在X平台上找到了一份实习。跟着一位优秀的领导Rachel姐学习,虽然她也是00后,也很年轻,但她教会了我很多关于问题解决的思维方式和实战心得,毫不保留地分享经验。这让我进一步强化了“遇到问题就直接上手解决”的意识,而不是先纠结完美计划。她的指导让我明白,成长往往来自真诚的互动和持续的输出。我在这里要真诚地感谢她(@Zesee ),因为这份真诚的分享,让我收获远超预期,非常推荐这位好领导!
最近,我又开始尝试一些新的小项目。一开始,我还是老样子:脑子里空想各种可能性,焦虑感不断堆积,总觉得“还没准备好”。但当我真正逼自己迈出第一步,哪怕只是做一个最小的原型或测试,焦虑反而慢慢消退了。
执行的过程本身成了最好的老师,它让我看到,把想法拆成可落地的小行动,身份就会悄然改变:从“想做的人”变成“正在做的人”。每完成一个小任务,都像在给自己投一票,证明“我就是那个能把事情做成的人”。
这些经历让我明白,拖延的根源往往不是懒惰,而是缺乏系统和身份认同。以前我总把重心放在“我要完成什么大目标”上,结果压力堆积、容易放弃。
现在,我学会把注意力放在“今天我能控制的小行动”上:把重要的事优先推进、与靠谱的人协同前进、通过日常的小习惯积累复利。执行不再是强迫自己,而是变成了自然而然的生活方式。思想终于落地到现实,我从一个想法很多但行动滞后的人,变成了能把想法转化为成果的人。
现在,我正式下定决心认真经营我的X账号。我要把这条成长之路走下去,以分享如何改善拖延、提升执行力为主线,持续输出实用经验和方法。希望通过这些内容,帮助更多像曾经的我一样被拖延困扰的朋友,一起突破瓶颈、建立属于自己的行动系统。
如果大家也正在为执行力和拖延烦恼,欢迎一起交流。行动起来,你会发现自己比想象中更有力量。让我们从今天的小步骤开始,一起把想法变成现实!
5
3
25
2,767
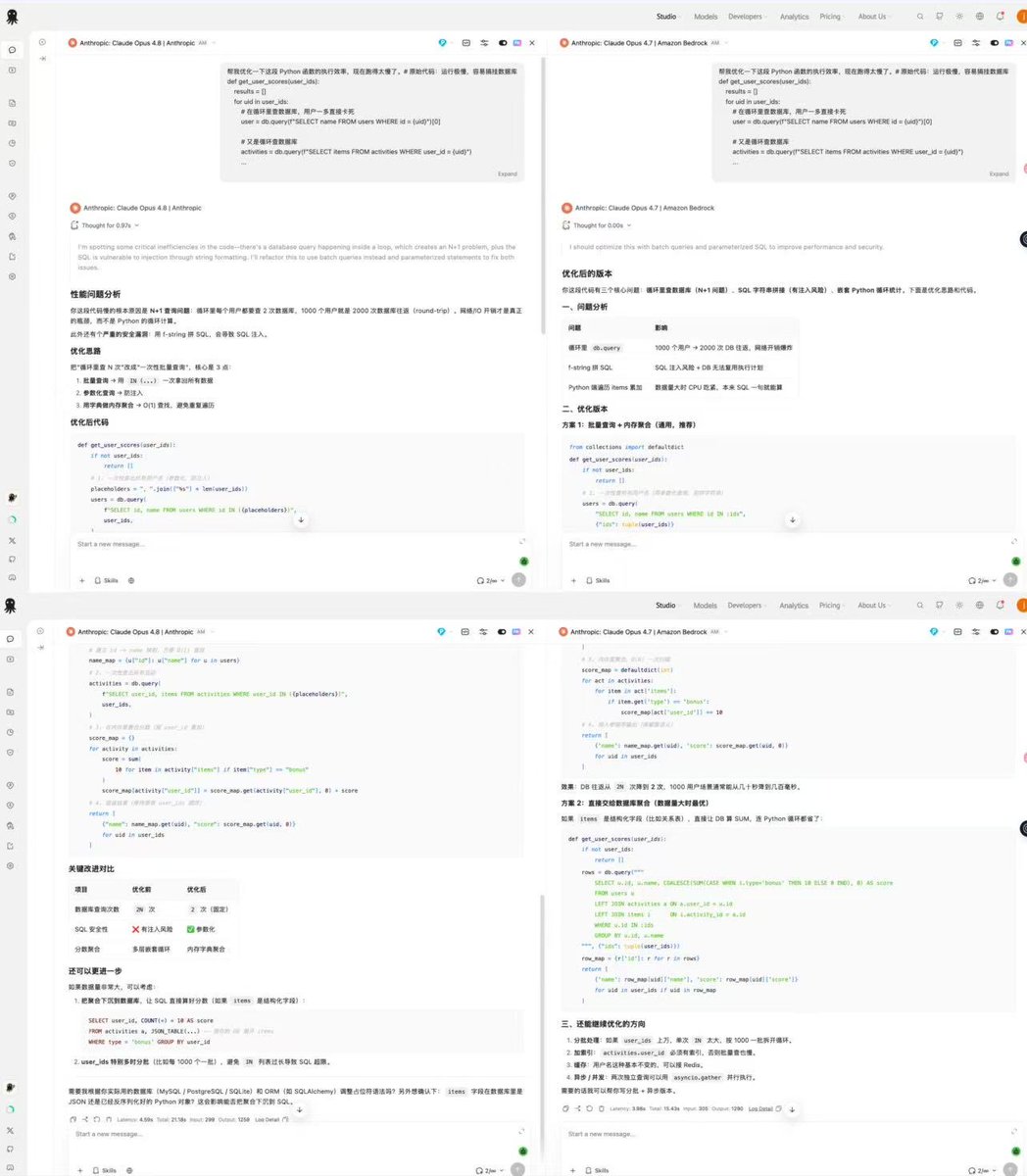
从技术架构的角度看,MemOS CLI 实际上是在为 Agent 时代构建一套标准化的记忆总线。
在当前的 AI 开发链路中,推理引擎和工具接口已经相对成熟,但持久化状态管理一直是一个痛点。
MemOS 通过一行命令将记忆操作标准化,其精妙之处在于它不仅提供了存储,还通过初始化脚本为 Agent 注入了行为模式。
这种让 AI 养成事前检索、事后记录习惯的做法,本质上是在通过基础设施的演进来模拟人类的职业素养,从而实现更高级别的自主性。
16
30
2,848
很多产品都在做AI帮自己做交易的可能性,或许还值得继续探索;
但如果让AI能做到大亏的时候已经清仓的提醒,就是实用性超高的AI赚钱的案例
Jun 8

这波美股回调前,AI 提醒我减仓,少亏了 3 万美金
很多时候,赚钱不是因为你知道了什么秘密,
而是你比别人更少漏掉关键信息,更早看到风险变化
这波美股下跌前,我的 AI 提前给我敲了警钟
它没有预测到了市场下跌,也不是替我自动交易
它只是帮我做了一件很简单但很有用的事:
把我可能会忽略的风险提示,及时推送到我面前
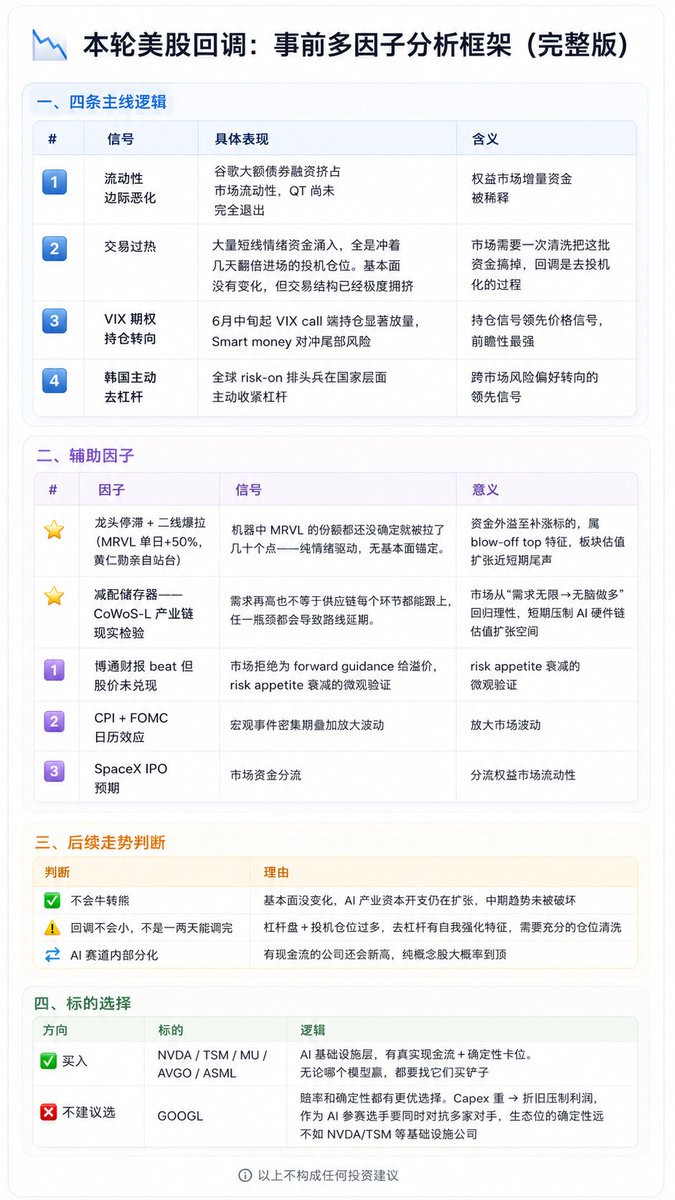
这次美股下跌前两天
Hermes 就把相关风险提醒的信息推给了我(参考图一)
也就是总结了我常看的几个关键博主和社群,
在提醒短期风险,以及原因是什么
这些信号单独看,可能只是一个观点
但当它们同时出现,就值得重视
所以我当天就把杠杆仓位清掉了
现货仓位也降到了只有 20%的NOK和MRVL
后面市场真回调了
按我原来的仓位算,这次AI及时提醒帮我
多保住了大概 3 万美金
我也在几个群里提醒了朋友们短期风险
不是跌完以后才马后炮(参考图2)
还有一次是黄仁勋喊单 MRVL 那天
AI 也及时把这个消息推送给了我
我刚睡醒看到以后,就在 Hyperliquid 上开了仓位
当天直接拉了 50%
吃到了 35%
这件事让我更确定一件事:
AI 最容易帮普通人赚钱的地方,不一定是直接交易
而是优化信息源
我其实一直在用 Hermes 处理市场信息源
只不过之前更多是在看加密市场
最近加密行情不太好,我才开始把美股 AI 这条线上接上
我让它每天会从几个层面帮我
监控信息 分析市场并写研报推送给我
1.宏观和资金面
比如 BTC、ETH、DXY、合约 OI、链上资金流
2.重要新闻
比如监管、机构资金、AI 科技、半导体供应链、美股 AI 链情绪
3.高信号信息源
比如我长期关注的博主、社群讨论、关键推文和市场观点
4.GitHub / AI Builders
用来判断 AI 行业真实开发者注意力正在往哪里流
5.Crypto 链上叙事
比如金狗/银狗、CA 证据、社区传播质量和叙事承载力
它不是把一堆信息原封不动丢给我
而是帮我过滤、归类、提炼重点
如果多个信息源都在提示同一个风险
它会把这个信号放到日报里
很多人都在说用 AI 交易
我也看过不少 AI Trading 的案例
总结下来,我觉得 AI 直接替你做交易非常难
但帮你优化信息源,其实很容易
现在信息源真的太多了
X、微信群、Telegram、研报、新闻、链上数据
每个地方都可能有重要信息
人不可能一直盯着所有渠道
尤其是微信群,消息太多,刷得太快
很多关键内容非常容易被忽略
你也没有足够精力一个个回头翻
这就是 Agent 真正有价值的地方
你不用它帮你拍板做投资决策
而是让它帮你过滤噪音、提炼重点,把分散的信息源连接起来
所以我现在越来越觉得:
普通人用 AI 优化投资交易的第一步,不是自动交易
而是先让 AI 帮你建立一个更强的信息系统
让它帮你看更多关键信息
更少漏掉风险变化
这才是 AI 在投资里最容易落地的用法
后面我会分享我具体是怎么用AI抓取的这些信息源
欢迎大家关注


10
1
13
1,661
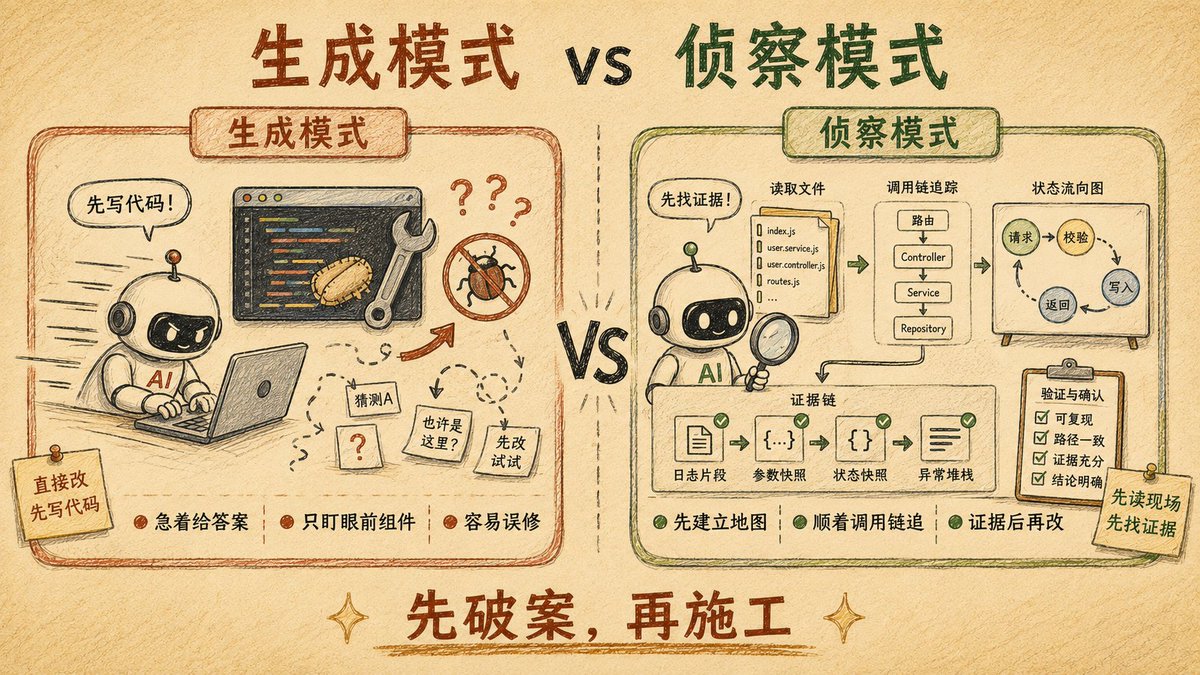
真正的 AI Native,不只是把 AI 塞进旧流程里让它帮人类省一点时间;而是从一开始就重新设计整个流程,让 AI 成为默认参与者。

5
1
4
1,660

开源一个抖音合规自检 skill
最近很多朋友都在做抖音视频,但发习惯推特之后,经常违规,所以我做了一个skill
具体用法:丢进去口播稿或者画面描述,它会告诉你哪些地方会被预审驳回(引导外流、诱导下载),并给出可以直接替换的合规表达。
举个例子:这句话是让观众"去做某个动作",还是在说"我用了什么/这个东西是什么"?前者违规,后者合规。
跟不挂 skill 对比:通过率 100% vs 59%
github.com/Jingyi-Wu-Richael…
41
14
71
16,620
16GB 笔记本能跑多模态 AI 之后,真正该学的是任务分流
这两天 X 上 Gemma 4 12B 挺热,大家最容易记住的是那句,16GB 笔记本也能跑。
这句话当然很抓人,但如果只把它理解成「终于可以少花点 API 钱了」,我觉得反而看窄了。真正值得在意的是,AI 工作流开始从单一的云端调用,变成一套需要分工的系统了。
以前我们用 AI,默认动作很简单,把材料丢给一个最强模型,让它读、让它想、让它写。写文章是这样,读 PDF 是这样,分析截图也是这样。这个用法没问题,但它有一个隐性的浪费,所有任务都被当成同一种任务处理了。
但真实工作里不是这样的。
你让一个人做事,也不会把所有活都交给公司里最贵的专家。整理会议纪要、初筛素材、给图片打标签、把一堆文档按主题归类,这些事情更像助理工作。真正需要专家判断的,是最后那一步,哪些结论成立,哪些地方有风险,怎么写成能交付出去的版本。
Gemma 4 12B 这种能在本地机器上跑的多模态模型,最有价值的地方就在这里。它不一定要替代 Gemini、ChatGPT、Claude 这类云端强模型,它更适合接走工作流里那些反复发生、隐私敏感、但推理难度没那么高的部分。
比如你手里有一堆会议截图和客户反馈,不要上来就全部扔给云端模型让它总结战略洞察。更稳的做法是,先让本地模型做第一轮清洗,哪些图里有客户名字,哪些是无关闲聊,哪些包含需求,哪些可能要打码。等材料被切干净了,再把真正值得判断的部分交给云端强模型。
再比如录音转写。很多人会直接把一整段会议转写丢给大模型,让它总结。但会议里经常有寒暄、跑题、重复确认、设备问题,这些东西不值得占用最贵的推理资源。先让本地模型切段、去重、标注主题,再让云端模型做结论提炼和表达润色,最后人来拍板,这条链路会稳很多。
所以我现在会建议大家给自己建一张「本地 / 云端分流表」,而不是看到新模型就问,它能不能替代我现在用的那个。
更好的问法是:
「请帮我判断这个任务应该交给本地模型、云端强模型,还是两者协作。请从隐私敏感度、推理难度、上下文规模、是否需要联网、延迟要求、成本六个维度判断。最后给出推荐流程,不要直接开始执行。」
这段 prompt 的重点不是省钱,而是让 AI 先帮你做任务路由。什么东西应该先在本地处理,什么东西必须上云,什么东西应该拆成两段,这些判断一旦固定下来,你后面的工作流会轻很多。
我自己的判断大概是这样。
本地模型适合预处理、粗分类、隐私资料的第一轮清洗、离线场景和反复跑的小任务。
云端强模型更适合复杂判断、综合写作、需要最新信息的调研、多步骤推理,以及最终要交付出去的版本。
这两类模型的关系,不应该是互相替代,而应该是上下游协作。本地模型做脏活,云端模型做难活,人负责定标准和拍板。
这才是 Gemma 4 12B 这类模型真正给普通人的启发。AI 不再只是一个聊天框,它开始变成一组工位,让每个模型坐在它最适合的位置上。
Jun 3

Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇

17
3
33
3,048
2021年我文科转码,26年文科生不用转码了
后台总有这样的留言:我是学新闻的,我是学中文的,我是学法律的,我不懂技术,现在还能转码吗。
我是2021 年文科转码,赶上了那波热潮。但到了 2026年,我觉得文科生不需要转码,只需要学 AI。
这就意味着不再需要学编程,是把 AI变成你写作、研究、做项目的工具,做成以前做不成的事。
21 年我为什么转码?因为当时我所在的行业已经肉眼可见地往下走,互联网大厂在蓬勃发展。当时编程还是有门槛,门槛后面有溢价。
24 年开始,事情变了
最早是 GitHub Copilot。不太会用编程的同学写代码速度也能追上了工作五年的老员工。接着是 Cursor。然后是 Claude Code。再是 vibecoding。现在你只需要像指挥官只会AI 干活。
我亲眼看着"写代码"的门槛被一节节磨平:从要做两三周的项目变成了一个下午就行。
我用 18 个月构建的护城河,也是变成了大家都能跨过去的水沟。
所以我现在的判断就是,文科在校生,或者刚毕业的文科生就不要转码。21 年值得走,26 年不值得了。
等你花 1-2 年时间学完,这个岗位已经不存在了,ai时代的变化是非常快的。所以我们学ai,不是要做 AI 工程师,而是要成为最会用 AI 的法律人 和新闻人等等
那具体怎么做呢,有以下两方面,
一个就是学会把事情说清楚,把你想做的事情和ai表达清楚;
第二个就是找你专业里耗时 重复的工作,用 AI 重新做一遍。
比如做新闻的朋友或者是说做诉讼的律师朋友,这些工作里都有重复性很强需要用ai去重做的部分,他们都没有去学编程语言,而是把专业判断 × AI 的执行能力放大到极致。目标是做成之前做不成的事
最后我想说的是,
我不后悔 21 年转码。那段经历训练了我怎么样搭建一个系统,这也是AI教不了我的。但今天的文科生,已经不需要再走这条弯路了。
39
4
41
5,211
Rachel🥥 retweeted
Jun 5
看到Jason老师的故事,正好今天也是我的last day,也想简单说一下我的故事
我是一个没有在大厂干过的一个程序员,也不是科班出身,编程是后来上网课学的,二十出头从深圳一路漂泊到杭州已经28了
去年开始瞄准AI赛道,开始做副业,做了自媒体,做了云服务器销售,做了AI中转站也做了培训,不知不觉已经快一年了
副业收入也超越了主业,上个月算了一下发现主业加副业已经达到6位数了,也是人生第一次能够月入十万,这也给了我足够的勇气,决定裸辞 all in AI
接下来我会围绕着自媒体,Token还有AI教育进行创业,欢迎来洽谈合作
Jun 5

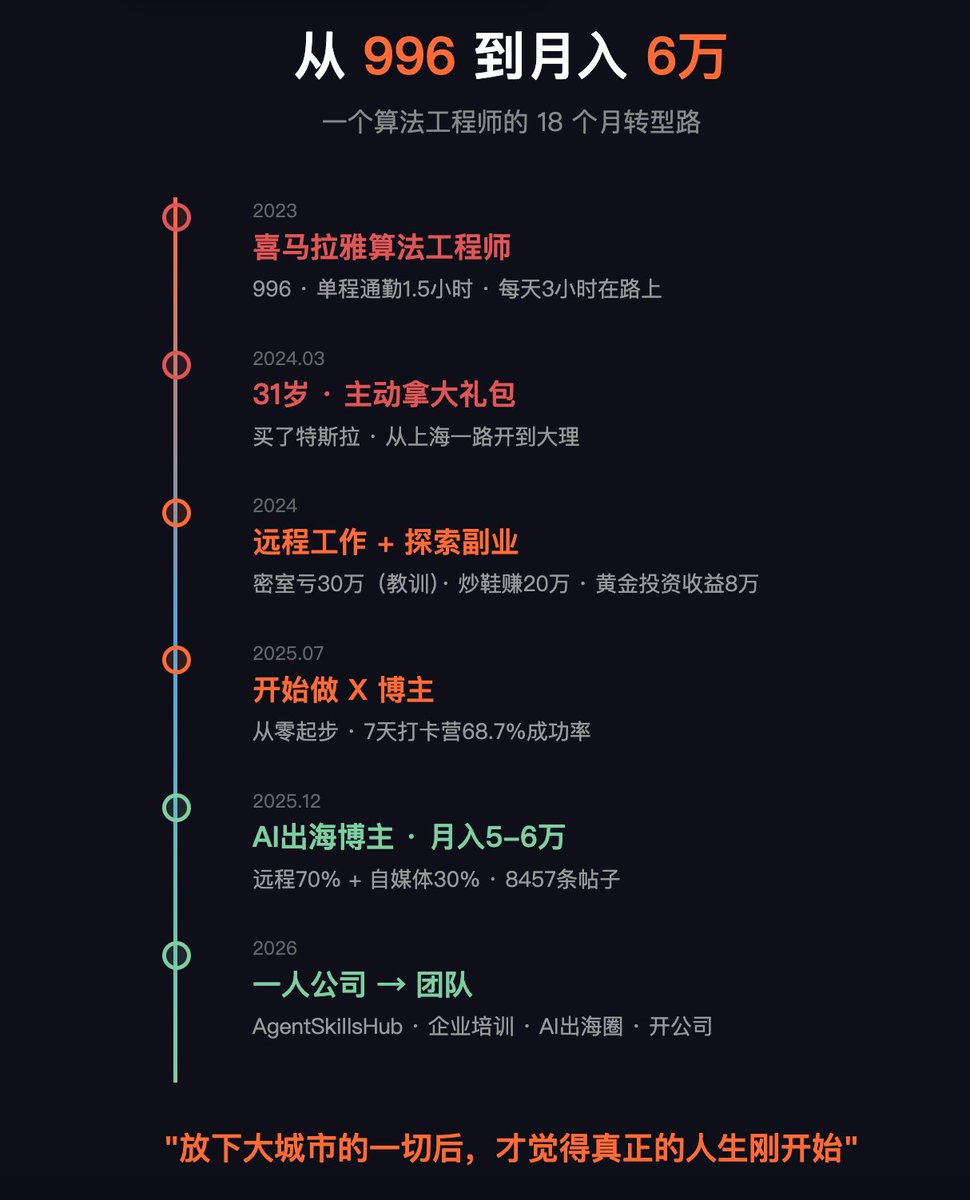
Karpathy 12月后没手写过一行代码
郭宇3个月一人做了15个产品
Uber 500个Skill完全自下而上长出来
这些故事很震撼,但都是别人的
我来讲一个自己的:
喜马拉雅算法工程师 → 996 → 31岁裸辞 → 开车去大理 → AI出海博主
18个月,从月薪到月入6万(现在xx),转型的每一步我都记得👇
88
7
90
59,299