
Joined February 2023
- Tweets 528
- Following 123
- Followers 616
- Likes 1,036
79 Photos and videos











Pinned Tweet

Jun 13
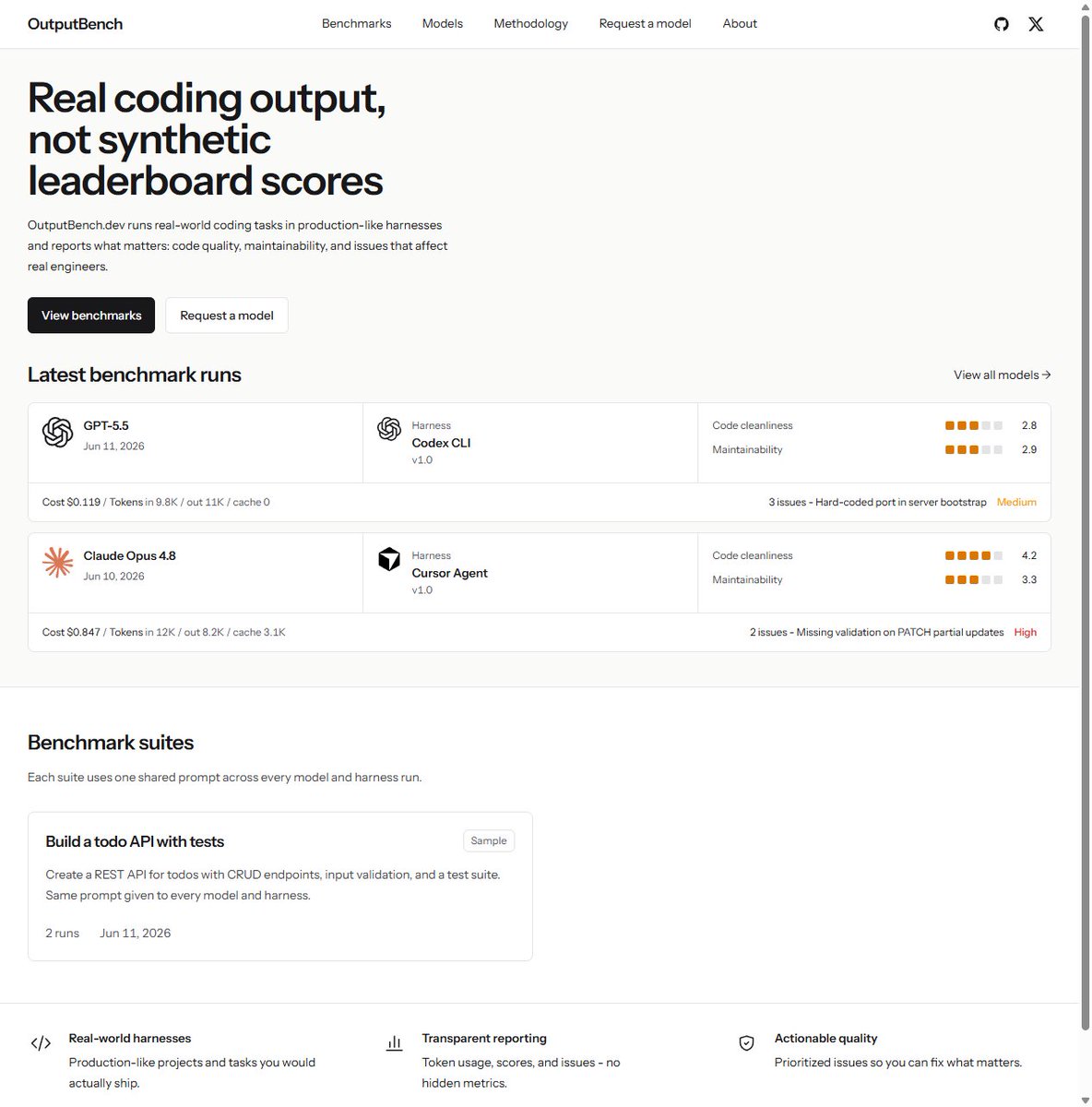
Introducing OutputBench.dev (inspired by @daradoescode his website for frontend)
I wanted coding benchmarks that look less like leaderboard puzzles and more like real engineering work.
Same prompt. Real agent harnesses. Public repos. Concrete issues. Tradeoffs you can inspect and argue with.
outputbench.dev
6
3
25
6,152
1h
OpenRouter launched Fusion as “Fable-level intelligence at half the price.”
I tried it on OutputBench: a real coding implementation benchmark.
Task:
Stripe webhook → SQLite → Discord.
Fusion placed 12th.
2m00s runtime
$2.30 cost
393k input tokens
7 implementation issues
The big one: the real Stripe SDK path crashes before persistence.
So yeah, maybe Fusion works well for research synthesis.
But for this coding task, I’d rather use a normal model directly.
2
4
121
4h
1/ I benchmarked @Kimi_Moonshot Kimi K2.7 Code across 3 agent harnesses on OutputBench.dev.
Same model.
Same prompt.
Same implementation benchmark.
Task: build a FastAPI Stripe webhook that verifies signatures, saves events to SQLite, and forwards clean Discord notifications.
Same prompt. Same model. Very different code.
2
3
179
4h
5/ OutputBench is not asking “which model writes the nicest answer?”
It asks:
Did it build the thing?
Does it run?
Are the tests meaningful?
What bugs survived?
How much did it cost?
How long did it take?
The model matters.
The harness changes the implementation.
1
20
Jun 13
Introducing OutputBench.dev (inspired by @daradoescode his website for frontend)
I wanted coding benchmarks that look less like leaderboard puzzles and more like real engineering work.
Same prompt. Real agent harnesses. Public repos. Concrete issues. Tradeoffs you can inspect and argue with.
outputbench.dev
6
3
25
6,152
Jun 13
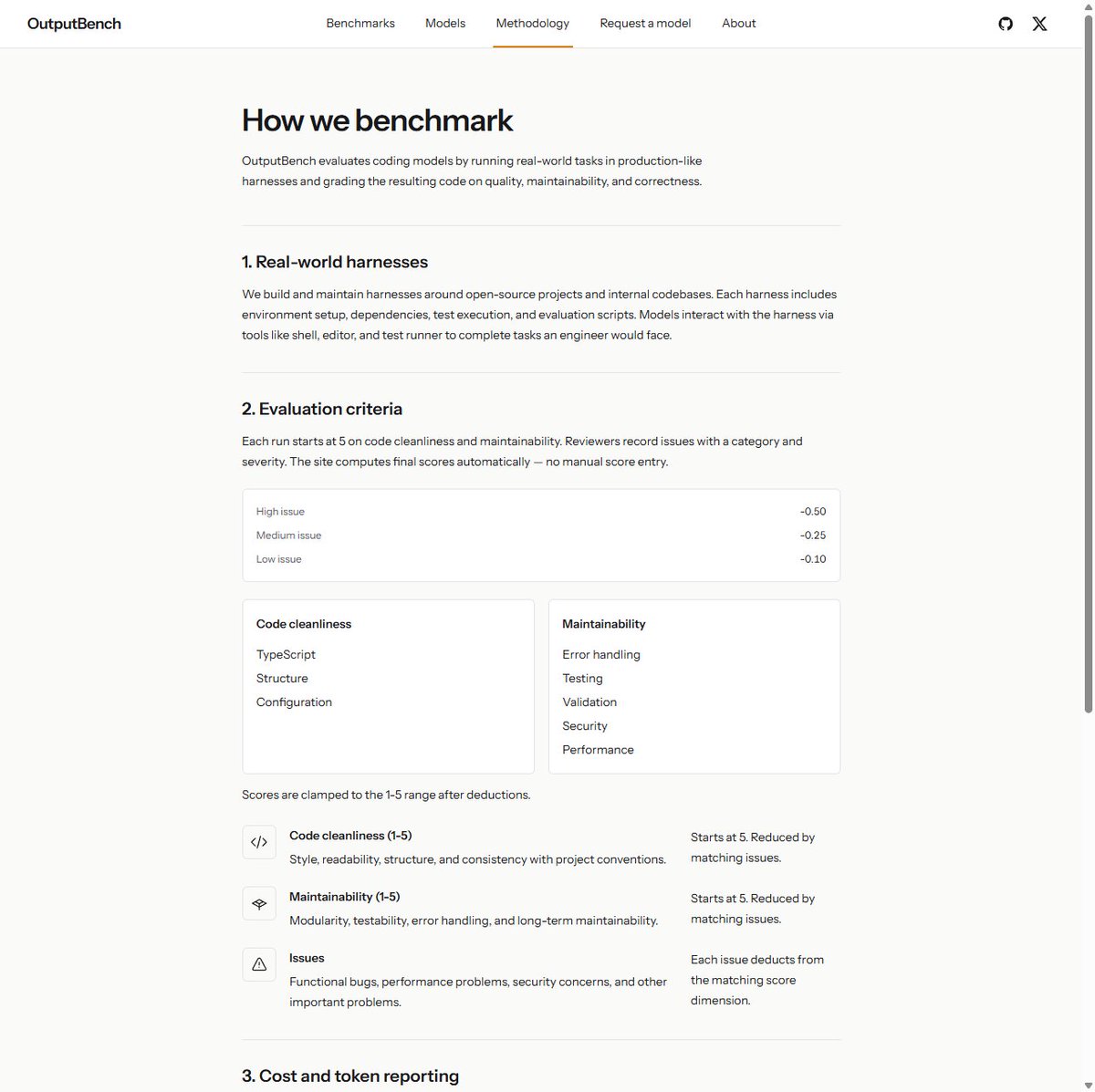
Why I built it:
Most model comparisons feel too abstract.
I wanted to see what models actually ship on the same real task, inside real tools, with inspectable code and honest tradeoffs.
Not just: “did it pass?”
But: would you trust it in production?
1
3
114
Jun 13
I’m adding more suites, models, and harnesses.
What should OutputBench benchmark next?
Drop a model, harness, or real-world coding task in the comments or DM me.
1
4
96
Jun 13
I am so happy that i did the test yesterday
the current benchmark chart looks like this for 1 of the suites
what models should i benchmark aswell?
9
1,754

Jun 11
Coming soon ™️ inspired by @daradoescode his website
An benchmark to test the 1 prompt output of each model and harness and how fast it is
based on how many issues the project has and severity it will rank it based on that
4
10
488
Jun 10
I benchmarked 3 coding models on the same coding task.
Same prompt. Same plan. Same requirements.
Results:
🥇 @cursor_ai Composer 2.5 — 1:29
🥈 @claudeai Fable 5 Medium — 1:52
🥉 @OpenAI GPT-5.5 Medium Fast — 3:05
But fastest ≠ best implementation.
Raw prompt breakdown below.
18
8
139
37,972