
CTO @heynoah. Built ARC-AGI 2 evals @gregkamrad.
Joined August 2017
- Tweets 3,362
- Following 1,623
- Followers 1,255
- Likes 37,868
205 Photos and videos










Pinned Tweet

20 Oct 2025
When you deploy an LLM-as-a-Judge, you’re shipping a classifier into production.
Each new version is a hypothesis about how the model interprets the world.
It’s data science, just expressed in natural language.
Here’s what that looked like for a recent client project where we trained an evaluator to detect a specific agent error type (labeled Category 1 failures) before release.
Dataset
Dev: 104 labeled traces (46 failures, 58 clean)
Eval: 95 labeled traces (34 failures, 61 clean)
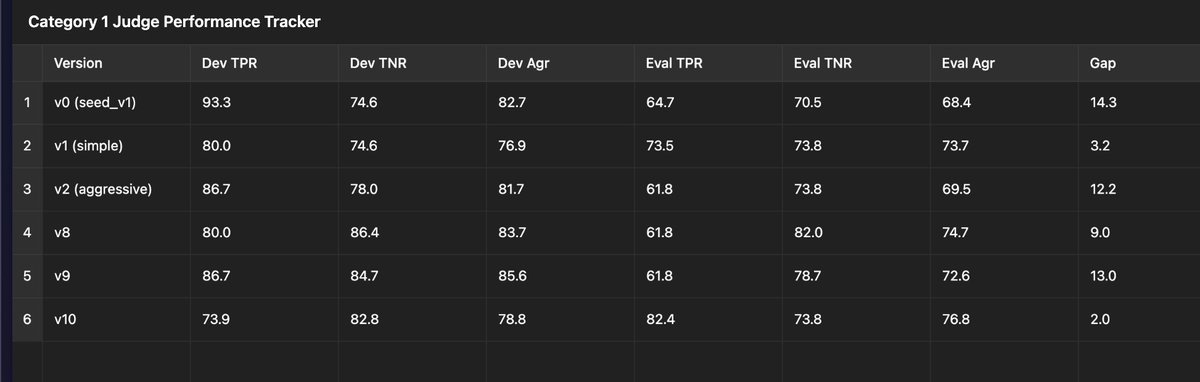
What We Saw
v1 established a clear baseline.
v2 drove recall higher but overfit to the dev set, collapsing generalization.
v3 made surgical adjustments that clarified “when not to trigger,” improving specificity and stability.
v10 is when started to see a step change in the eval set performance, a sign the judge was beginning to generalize.
Why It Matters
I find that teams often fall into the trap of assuming the llm works without verifying it through hard data. This is a big mistake! Look at the numbers below and see for yourself. Even with careful preparation, the model still fails to correctly classify more than 80 percent of actual labeled errors.
A few percent of overfit recall here, a small generalization gap there, and suddenly your CI isn’t filtering what you think it is.
Treat them like classifiers: versioned, measured, and tuned against held-out data.
That’s how you keep agents honest in production.
@HamelHusain @sh_reya
8
14
134
16,376
Jun 12
Everyone's talking about agent loops right now. The part nobody says out loud: loops compound, and most directions you can compound in are negative.
Our loop was simple. Issue comes in, spin up a bunch of agents, review lightly, trust them, ship. The velocity was real. We could have gone further and pulled straight from the tracker with a human almost fully out of it.
Here's what that buys you. You stop understanding your own system, and AI reviewing AI isn't enough to fix it. It's the middle management problem at hyperspeed: you're the CEO reading the ground floor through three layers, except the floor moves faster than you can read it.
And because a loop compounds, an undisciplined one doesn't drift a little. It runs confidently in a bad direction and builds your confidence the whole way, until you hit an edge you never saw coming.
I used to be AI for everything. Now I think it's a tool that quietly makes your life harder if you point it wrong, and it feels like progress right up until the ravine.
The skill isn't running more loops. It's making good decisions with less understanding of what's underneath than you've ever had.
1
1
39
May 15
reading user transcripts on a sunday is the closest thing founders have to therapy.
not because the users say nice things. because you stop being defensive about your product and start hearing what they actually said.
distance is a feature. plan for it.
46
May 14
ai chat ux failure mode i keep seeing:
the agent has too much context and uses all of it.
users don't want a system prompt rolled into the response. they want the answer. context should be invisible. the moment the agent says "based on what you told me earlier..." you've shown your hand and lost the magic.
1
49
May 14
startup math:
100% of 1 thing > 75% of 7 things.
the second is dead in the water. the math feels wrong because adding features feels like progress. it's the opposite. each new feature dilutes the one thing you were almost great at.
30
May 13
the questions you ask politely get answered politely.
the questions you ask after four hours of sitting in a room together get answered honestly.
most product research stops at hour one. the good stuff starts at hour three. founders who skip the slog get the polite answer and miss the real one.
1
40
May 13
every great agent product i've used has the same property:
i forget there's a model behind it.
the moment you remember it's an llm, the product has lost. the work is making the seams invisible. most teams optimize for showing the seams off.
1
32
May 12
scheduling isn't the wedge into executive workflow because scheduling is hard.
it's the wedge because the meeting that didn't happen is more expensive than the meeting that ran ten minutes long.
founders building "calendly for X" miss this. it's not the meeting. it's the meeting NOT happening.
35
May 12
LLM costs are now the variable cost.
infrastructure is the fixed cost.
we've inverted the SaaS economics in two years and most of the playbooks haven't caught up. usage-based pricing isn't a billing model anymore. it's a margin survival strategy.
1
29
May 11
founders ship two products at the same time:
the one the user pays for.
the one they sell to themselves at night to keep going.
if those drift apart for too long you quit. the work is keeping them aligned without lying about either.
14
May 11
calling it review surface area: how fast your team can comment on what claude code just made.
markdown is bad at this. html with inline comments (like google docs) is great. specs, evals, prompts, feature proposals, code reviews. all rendered commentable now. comments feed back into claude code as direct edits.
ai for implementation. humans for judgment. that second one breaks the moment review gets painful.
1
43
May 11
the eval suite that matters is the one built from user complaints, not the one designed upfront.
upfront evals test what you imagined the product would do. complaint evals test what the product actually does in users' hands.
these are different surfaces. one is a vanity metric. the other is the product.
1
35
May 8
i'm a context-switcher. it took me years to stop apologizing for it.
the productivity advice industry is built for momentum people. deep blocks. monk mode. one thing at a time. it's good advice. it's just not for me.
i do my best work jumping between threads. each one charges the next. the cost of forcing myself into a single-track day is bigger than the cost of switching.
play to your wiring. half the productivity gospel is for someone else's brain.
55
May 7
agents that over-explain what they did are showing their training.
agents that just did the thing and moved on are showing taste.
"here's the draft, does this look okay?" is a model output. "done, you're booked thursday at 2pm" is a product output. these are different things.
1
70
May 7
qa suite that runs once is a smoke test.
qa suite that runs and then auto-updates the prompt against the failures is the actual product.
the eval system that improves itself is worth 10x the eval system that just grades.
we built the second one and i'd never go back.
1
50
May 6
agent ux insight i didn't see coming:
users tolerate 60 seconds of latency once they trust the agent.
not because they got more patient. because they stopped watching. trust = put the phone away. the product target isn't speed. it's earning enough trust that users are doing something else while you work.
1
2
51
May 6
two of my agents got stuck in a group chat with each other. infinite loop. neither would shut up.
the fix wasn't smarter agents. it was teaching one to not need to have the last word.
most llms are trained to. that's a problem when they meet themselves.
59
May 5
agent design rule i didn't appreciate early enough:
the agent doesn't need a filesystem. it needs to think it has one.
a read-only view projected from your db is enough. the model gets the affordance ("i can list files, i can grep") without you actually mounting anything.
half the time the filesystem is a useful lie.
1
52
May 5
typing indicators are the loading bar of conversational ux.
users tolerate ~2 seconds of nothing before they assume something broke. after that you've already lost the trust round.
the agent that's slower but shows it's thinking beats the agent that's faster but silent. show the work even when there's no work to show.
2
38
May 5
two of my agents got stuck in a group chat. infinite loop. neither would shut up.
the fix wasn't smarter agents. it was teaching one not to need the last word.
most llms are trained to. that's a problem when they meet themselves.
1
78
May 5
a year of using AI for everything in engineering. honest take.
what got better: throughput, junior ramp, code review.
what got worse: architectural memory, debugging instinct.
net positive. but the costs are real and most teams aren't naming them.
3
63