
Learning & exploring ML systems & infra, RL
Joined December 2023
- Tweets 651
- Following 237
- Followers 59
- Likes 2,230
128 Photos and videos





Ramsha Khan retweeted

Apr 6
i feel like all roads lead to
mathematics
physics
philosophy
308
1,174
9,008
176,515

Apr 5
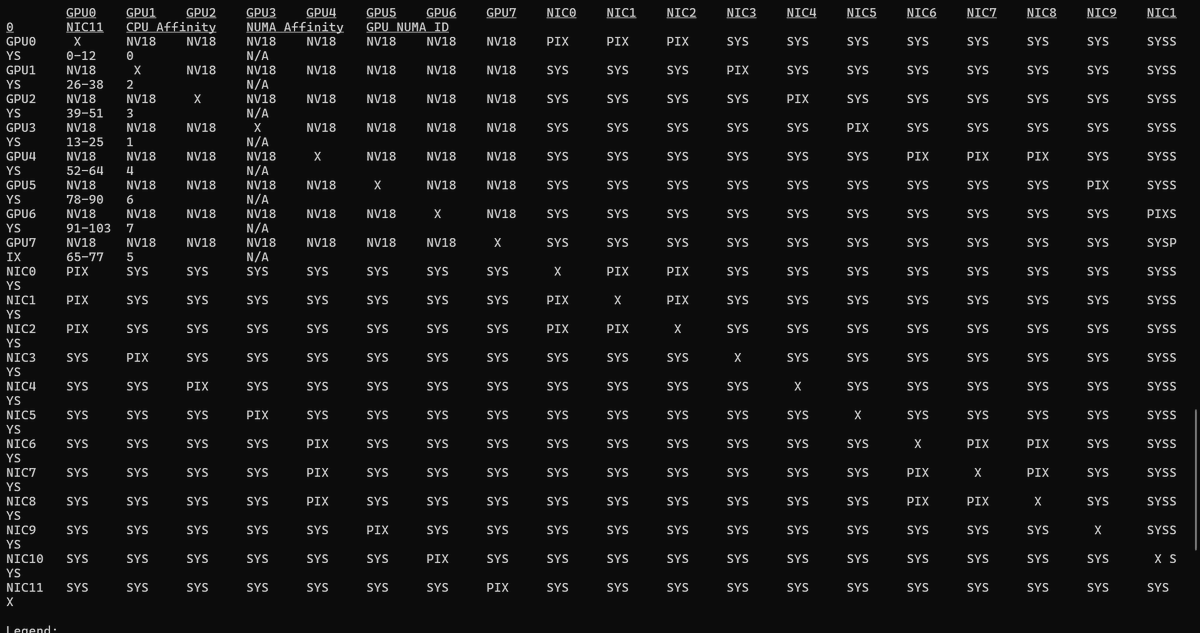
Day 14 of learning distributed training:
Exploring GPU topology 👇
X means the GPU is referring to itself (so yeah, no communication with itself xD)
When you see PHB, it means GPUs are connected via the PCIe Host Bridge (CPU) so no direct GPU <-> GPU link
(1/n)

Apr 4

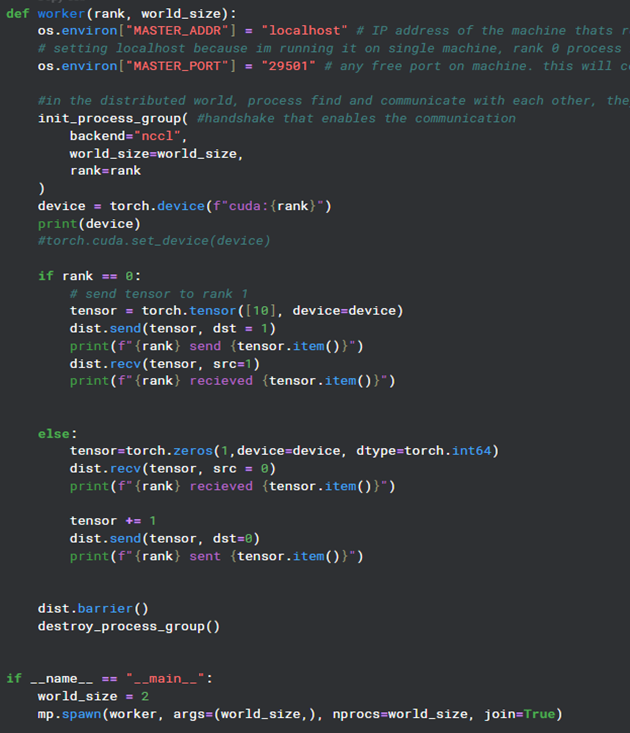
Day 13 of learning distributed training:
We've covered collective operations where multiple processes take part in communication.
Now there’s this -> point-to-point communication (one-to-one)
where you pass data from one specific process to another (not all processes).
(1/n)
2
7
335
Apr 5
NVLink = direct GPU interconnect -> much higher bandwidth than PCIe
So communication paths actually matter a lot for distributed training.
I was reading a Hugging Face article where they compared DDP performance with & without NVLink, and the difference is pretty clear:
(2/n)
2
3
122
Apr 5
With NVLink training is faster compared to without NVLink.
If you're curious about NVLink, give this a read: intuitionlabs.ai/articles/nv…
Quick note: I might take a break from this series for a few days, will pick it up again soon!
3
94
Apr 4
Mar 21
Hi people!
It's been a while since I started exploring distributed training, so I thought I'll start sharing what I'm learning.
(and will try to stay consistent)
Right now I'm starting with parallelism strategies for model training.
(1/3)
4
245
Apr 4
Send the tensor between processes using send() and recv()
There's also isend() and irecv() - non-blocking functions > transfer can happen in the background while some other computation/work runs simultaneously
(2/n)
1
2
87
Apr 4
Things NOT to do!
Be careful while setting src & dst and the operation If process0 sends to process1, then process1 should receive from process0
(3/n)
1
2
81
Apr 4
Both should NOT send at the same time they'll wait forever because both are sending and both will keep waiting to receive leads to deadlock.
Don’t modify the tensor before .wait() when using non-blocking functions.
2
86
Apr 3
Day 12 of learning distributed training:
We saw a linear relationship between workers and the steps needed for communication, so there was an assumption that latency doesn’t matter much. But in large distributed systems, that assumption breaks as latency is not negligible.
(1/n)
Apr 2
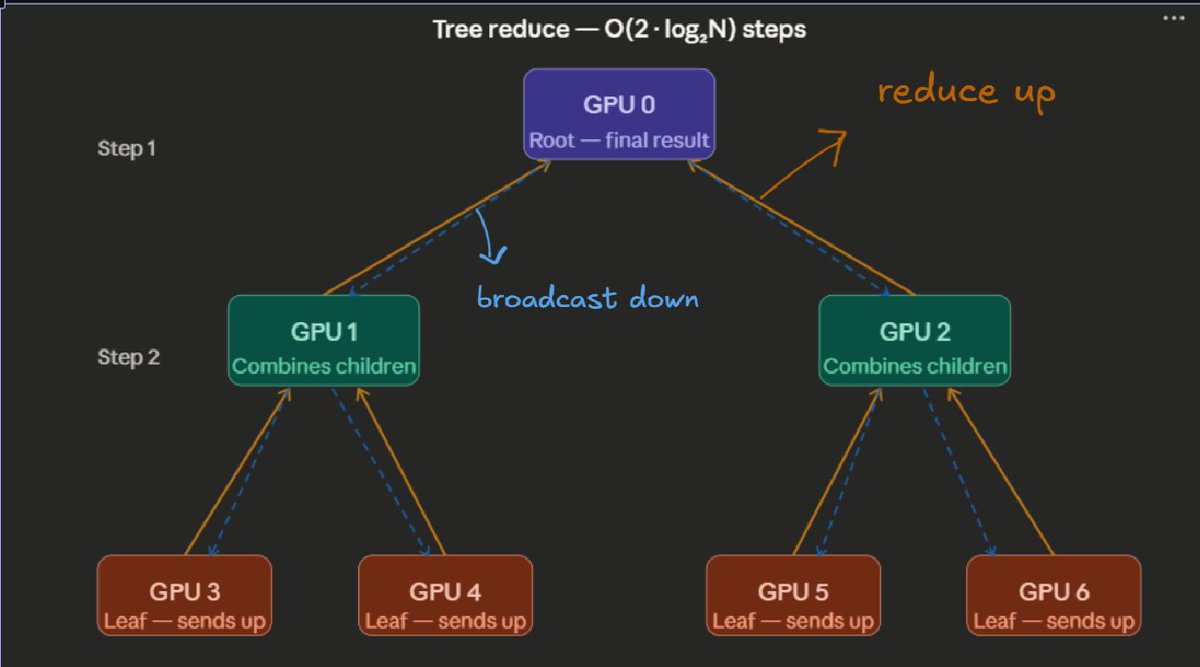
Day 11 of learning distributed training:
Let's keep going with collective ops by zooming into All-Reduce and what's happening behind the scenes.
So I found a couple of ways to do naive all-reduce:
(1/n)
1
8
527
Apr 3
Then, to fix the utilization issue, Double Binary Trees were introduced. It’s a sweet spot between the previous two approaches.
There are two trees: a root in Tree A acts as a leaf in Tree B.
(3/n)
1
3
57
Apr 3
A leaf that was idle in Tree A now becomes active in Tree B. So even if some GPUs are idle in one tree, they are active in the other.
2
45
Apr 2
Day 11 of learning distributed training:
Let's keep going with collective ops by zooming into All-Reduce and what's happening behind the scenes.
So I found a couple of ways to do naive all-reduce:
(1/n)
Apr 1
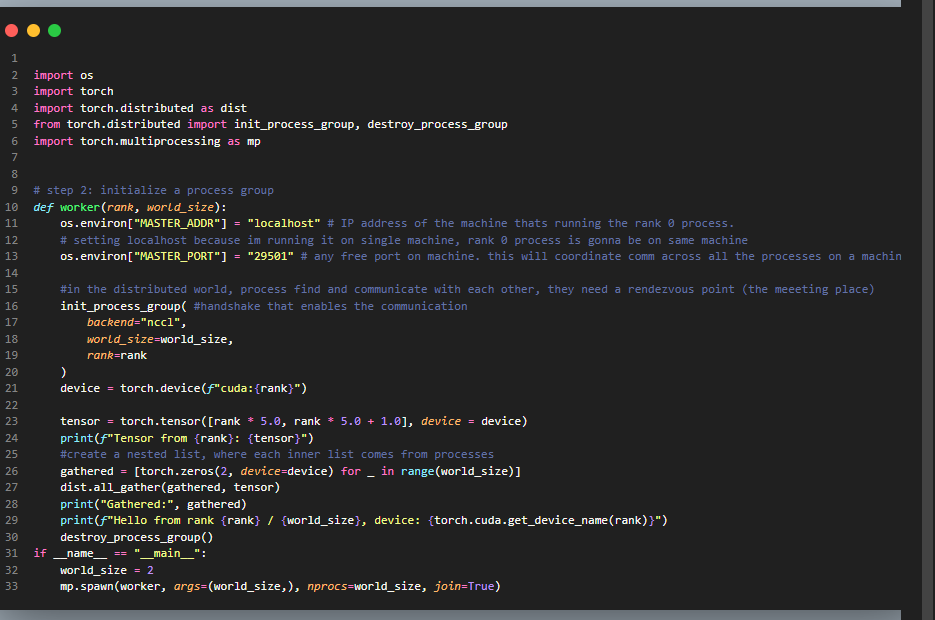
Day 10 of learning distributed training:
How do processes talk to each other?
We make use of collective operations and here's an example of using one of them!
Processes need to share data with each other so
let’s make these processes communicate using all_gather.

1
3
624
Apr 2
so each phase takes (N − 1) steps, and since there are 2 phases, total steps = 2 × (N − 1) (N: number of gpus)
in every step, each GPU sends/receives a chunk of size D/N, overall data moved per GPU becomes:
-> 2 × (N − 1) × (D / N)
which is roughly ~2x the data size
1
2
55
Apr 2
all good so far… but yeah, nothing's perfect
ring also comes with a downside of linear latency scaling with number of processes/workers.
we'll see in the next thread what comes up to solve this.
2
54
Apr 1
Day 10 of learning distributed training:
How do processes talk to each other?
We make use of collective operations and here's an example of using one of them!
Processes need to share data with each other so
let’s make these processes communicate using all_gather.
Mar 31
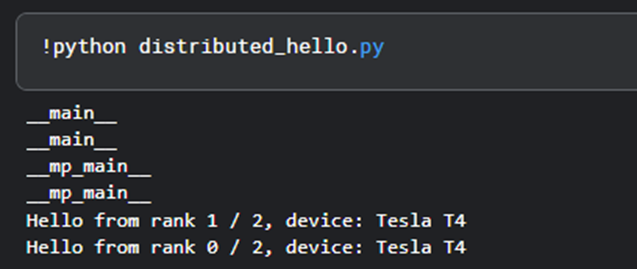
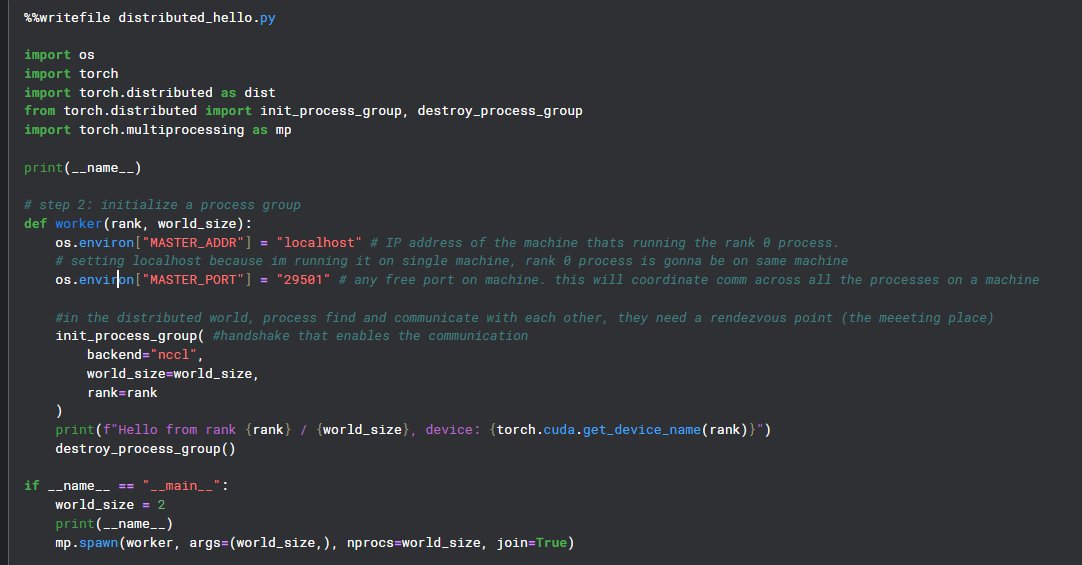
Day 9 of learning distributed training:
Going to discuss some subtle things today:
i) What happens if we forget if __name__ == "_main__" before spawning processes?
ii) Why do we need that "magic command" at the top of the cell (in notebook) ?
(1/n)
3
488