
Passionate, but pragmatic Software Engineer 👨💻 Ask me about: Server-Side, Data(bases), Concurrency, System Design, Linux, Algorithms🤖
Joined November 2021
- Tweets 1,829
- Following 284
- Followers 2,077
- Likes 1,348
97 Photos and videos









Pinned Tweet

4 Jun 2023
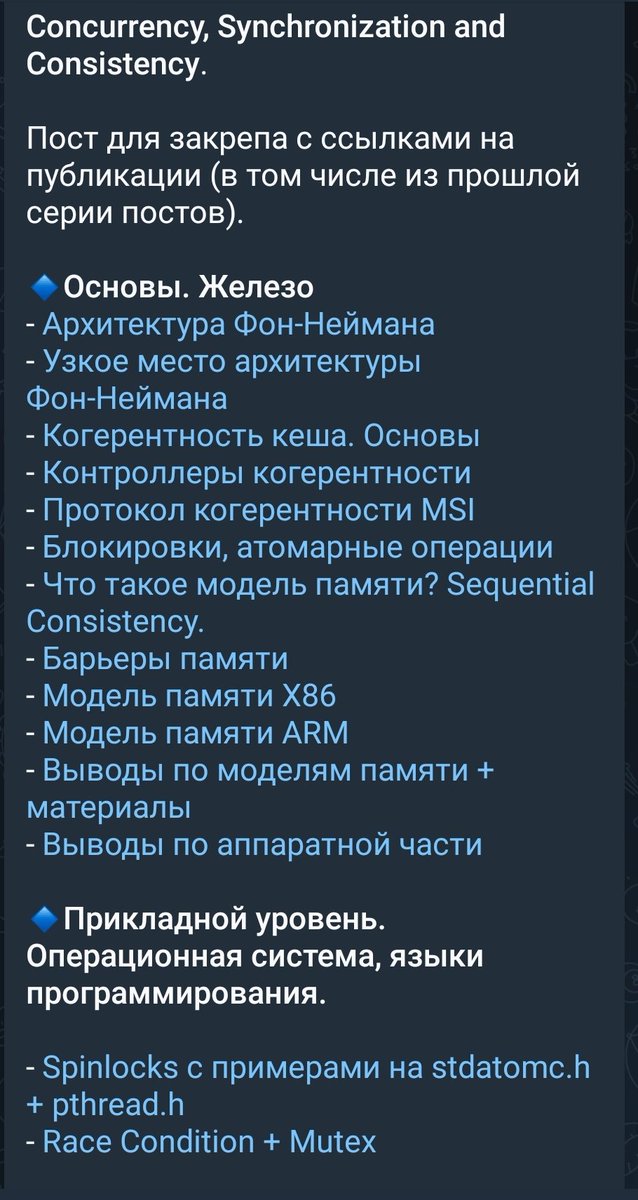
За время что веду твиттер накатал уже приличное количество технических тредов и постов. Для своего и вашего удобства соберу их в единый тред для закрепа😊 📷📷🔽🔽
1
20
144
41,726
Дежурный пост-напоминание - если вам по какой то причине нужно научиться кодить - вам не нужно ничего кроме exercism.org.
На платформе куча языков, задачи c фокусом на конструкции .все по ТDD, решение каждой задачи это Red-Green-Refactor.
Пользуюсь сам, рекомендую.
Exercism
Learn, practice and get world-class mentoring in over 50 languages. 100% free.
exercism.org 1
6
90
5,831
Почему я решил написать об этом сайте? Да потому что понадобилось освежить в голове и на коньчиках пальцев Java Core - и лучше ресурса так и не нашлось :)
4
634
Eugene Kozlov retweeted

Jun 1
Моя скромная просьба к вам, солнышки: пожалуйста распространите информацию о проекте. Я очень устал делать его в одно лицо.
github.com/Warp-net/warpnet
13
25
97
11,908
May 24
Я болельщик Спартака и мне по человечески жаль Хуана Боселли. Просто пиздецкие 2 недели у человека.
2
243
May 19
Увидел в рабочем чате вопрос про фреймворк для написания тестов на Go, поделились вот такой ссылочкой, открываю а там буквально рубишный RSpec на Go. И чот так защемило в груди, уже 5 лет никаких рельс и никакого Ruby.
github.com/onsi/ginkgo
Рубисты, как вы там? Ruby жив?
3
11
2,767
Eugene Kozlov retweeted

May 16
Before jumping into books like DDIA or Database Internals, it helps to understand the systems layer these designs are built on.
A lot of the design of such data-intensive systems is based on virtual memory: page tables, page faults, mmap, the page cache, swapping, NUMA placement, TLBs, and the tradeoffs between what the OS wants and what the database wants.
My latest article is a ~25,000-word mini-book on virtual memory.
It starts from first principles and goes all the way down to advanced topics like NUMA placement and performance debugging with tools like perf and /proc.
I also wrote it differently: as a dialogue between a user-space process and the kernel.
Most treatments of virtual memory are dry and fact-heavy. I wanted this one to feel more like a story, while still being technically deep.
Link below.

24
171
1,425
85,734
May 15
Не открывал Claude Code с месяц, попросил его сгенерить сниппет кода, пыхтит минут 5, так ничего и не сгенерил, подписка Pro на месте. Раньше отклик был в несколько секунд для таких простых задач.
Мои токены ушли на переписывание Bun на Rust? Или AI Revolution всё, того?
13
1
77
19,479
Apr 27
Я смущаюсь когда нужно рассказать про должность и чем занимаюсь на работе:
- Утром тимлид
- После обеда CTO.
- Вечером курю пейперы как стафф
- Аналитика.
Переживаю, что выгляжу несерьезно. Думаю, пора что-то менять.
А тут AI revolution и теперь это база. Ну и дела.
2
6
625
Apr 27
"Предвосхитил тренды" или "не жили богато - нефиг начинать"😁
1
169
Eugene Kozlov retweeted

Author of Designing Data-Intensive Applications, Martin Kleppmann, on why scaling down is just as challenging as scaling up:
“Part of what is interesting about modern cloud services, and backend services in general, is how they've introduced the idea of horizontal scalability and shared nothing systems. We can build systems that are able to cope with very high load, even if the individual components are just fairly cheap commodity machines.
The scalability story is not just scaling up, but scaling down as well. How do you run a service in such a way that if it has a very small amount of load, it's really cheap to run? That's sort of the same question as ‘how do you continue running a service if it has a very high load?’
Generally, you want the cost and the computing capacity to be roughly proportional to the load that you have and at the low end, that means actually being able to scale down to something that is extremely cheap to run.
That's not necessarily a given. It's something that is hard with on-premises software because if you've got a physical machine, that is a unit of deployment. Yes, you could carve it up into two dozen virtual machines, but it still requires some sort of resource allocation.
And so, part of what's interesting about some serverless systems, is their ability to scale down and say ‘okay, if you're going to handle just three requests per day, that's just fine as well’”.
6
14
133
21,243
Apr 24
Если вы увидели оригинальный пост и подумали - "О чем вообще речь, нихрена непонятно" то вы не одиноки, я сам офигел, за 2 года некоторые вещи выветрились напрочь у меня самого.
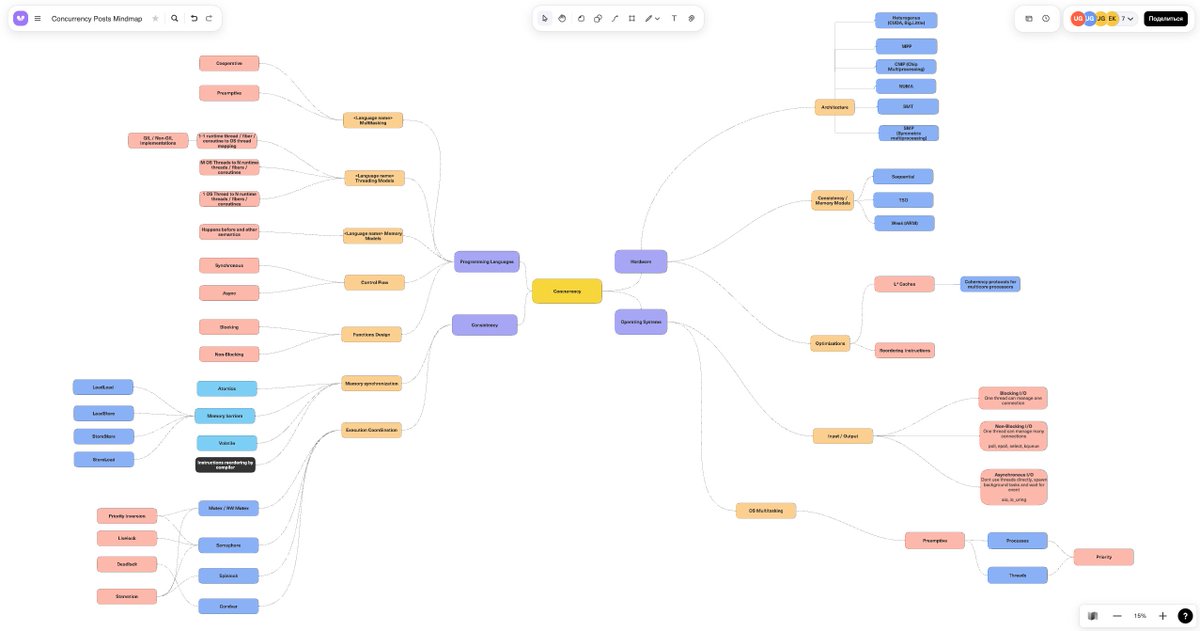
Бахнул Concurrency Mindmap для более комфортного погружения. Исходник добавлю ниже.
Apr 21

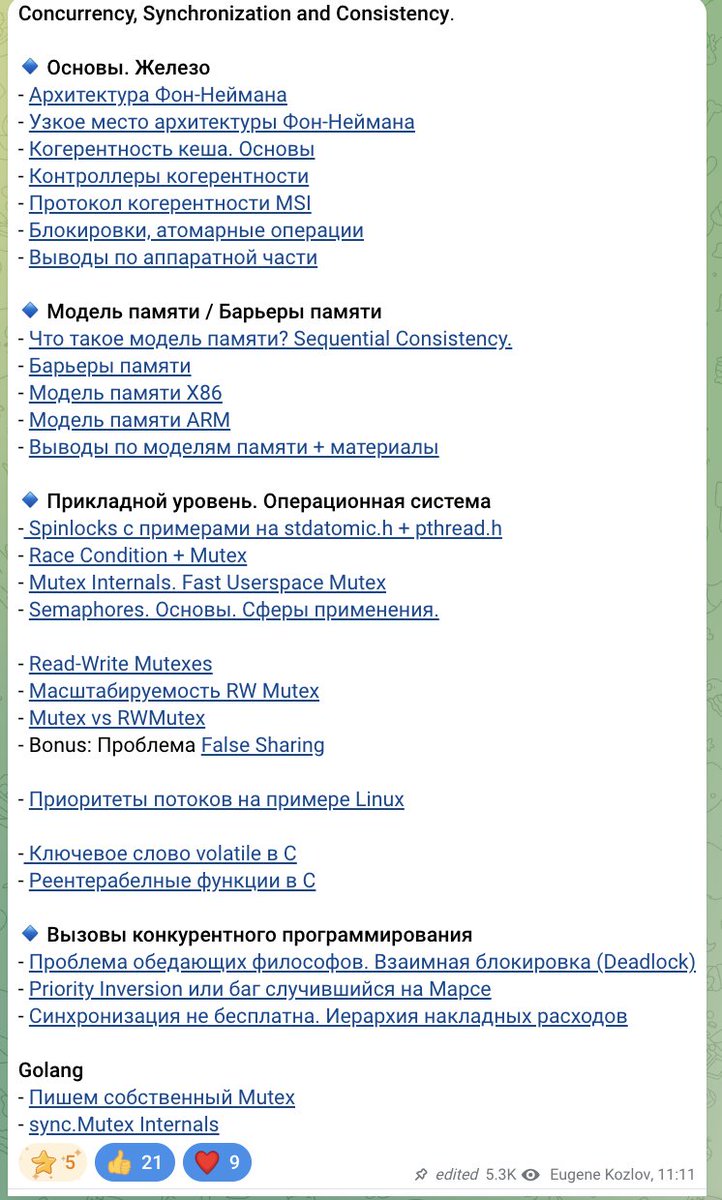
Выдержав паузу начал писать 3й цикл постов по Concurrency. Если в 1м был разбор за счет чего наш код быстрый, то 2й о том как писать корректный код. На скринах то что получилось🙂
Сейчас погружаюсь в lock-free, non-blocking, async и тому как выжимать из железа всё
⏬⏬⏬
1
3
40
6,329
Apr 23
Коллеги DevOps, и просто инженеры. Я совершенно случайно узнал что проект kainko уже год как заархивирован на GitHub.
Вопрос - и какой сейчас положняк для сборки образов на CI?
github.com/GoogleContainerTo…
6
6
3,007
Apr 23
P.S. Имел в виду скорее - сборка образов без Docker как зависимости.
429
Apr 21
Выдержав паузу начал писать 3й цикл постов по Concurrency. Если в 1м был разбор за счет чего наш код быстрый, то 2й о том как писать корректный код. На скринах то что получилось🙂
Сейчас погружаюсь в lock-free, non-blocking, async и тому как выжимать из железа всё
⏬⏬⏬
2
2
59
13,026
Eugene Kozlov retweeted

Apr 9
Недавно у меня случился спонтанный собес, который потревожил больную мозоль, и я решил наконец собрать мысли в текст, т.к. давно хотелось об этом поговорить. Все вроде как согласны, что важен инженерный подход, умение думать, декомпозировать задачи, разбираться в незнакомом. Это прям мантра на каждом митапе и в каждом посте на LinkedIn. И при этом, когда доходит до реального собеседования, тебя спрашивают конкретный фреймворк или конкретный инструмент. И если ты его не знаешь, ну или знаешь недостаточно глубоко, разговор как-то сам собой сворачивается.
Я долго думал, что это просто лицемерие, что люди говорят одно, а делают другое, потому что им лень или потому что так проще. Но кажется, всё интереснее. Есть такая штука как affinity bias, это когда ты неосознанно отдаёшь предпочтение человеку, в котором узнаёшь что-то своё. Не обязательно внешность или бэкграунд, это может быть стек технологий. Когда кандидат говорит "я писал на Go с PostgreSQL", а у тебя в проде Go с PostgreSQL, у тебя в голове щёлкает что-то вроде "свой человек, понимает контекст, можно не объяснять базовые вещи". И это ощущение знакомости мозг интерпретирует как компетентность, хотя одно с другим вообще не связано.
Исследование Diversity Australia показало, что affinity bias влияет на 78% решений о найме, и я подозреваю, что в IT это даже хуже, потому что технический стек, это такая штука, про которую легко думать, что она объективна. Типа, "я же не по внешности сужу, я по скиллам", но "скиллы" в этом контексте почему-то означают "знает то же, что и я", а не "умеет разобраться в новом".
Есть ещё halo effect, это когда одна положительная черта распространяется на всё остальное. Кандидат работал в Google, значит он наверное и с архитектурой хорош, и в команде нормально работает. Или кандидат знает твой стек, значит он наверное и задачи декомпозирует нормально, и в проде не накосячит. Мозг дорисовывает картину из одного пикселя, причём делает это незаметно для тебя самого.
И вот что получается. Harvard Business School провели исследование про skills-based hiring, это когда вместо требования диплома компания вроде как оценивает навыки напрямую. 85% компаний заявляют, что перешли на этот подход. А реально это затрагивает 0.14% наймов. Один из семисот. 45% компаний из выборки просто поменяли формулировки в вакансиях, но нанимают ровно тех же людей, что и раньше. Исследователи назвали эту категорию "In Name Only", что, кажется, довольно точно описывает ситуацию.
Я это к чему. Мне кажется, с инженерным мышлением vs конкретными навыками происходит то же самое. Компании пишут в вакансиях "нам важен problem-solving и умение учиться", а на собеседовании проверяют, помнишь ли ты синтаксис конкретного языка или API конкретного фреймворка.
И тут есть ещё одна хуйня, которая делает ситуацию практически безвыходной. Допустим, ты реально умеешь разбираться в новом, у тебя за плечами десять лет переключений между стеками и каждый раз ты выходил на рабочий уровень за пару недель. Как ты это покажешь на собеседовании? Собеседование длится час, может полтора. Все вопросы заточены под заготовленные ответы, ты либо знаешь как устроен event loop в Node.js, либо нет, и если нет, то никакое инженерное мышление тебе не поможет ответить на этот вопрос прямо сейчас, потому что оно работает на масштабе дней и недель, а не минут. Ты не можешь "разобраться в новом" за время собеса, потому что это процесс, а собеседование проверяет результат. И получается замкнутый круг: компании говорят, что ценят способность учиться, но формат проверки физически не позволяет её увидеть, зато прекрасно позволяет увидеть, что кандидат заранее вызубрил ответы на типовые вопросы по нужному стеку.
И проблема в том, что человек, который проводит техническое интервью, физически не может отделить "этот кандидат хорошо думает" от "этот кандидат знает то же, что и я". Когда кандидат оперирует теми же инструментами и терминами, что и ты, мозг автоматически считывает это как "он понимает проблему", хотя, возможно, он просто заучил ответы на типовые вопросы по этому стеку.
Karat в своём отчёте за 2026 год пишут, что 73% руководителей считают сильных инженеров стоящими минимум 3x от их компенсации. При этом AI размывает сигнал в традиционных интервью, т.к. кандидат может скормить задачу нейросети и получить рабочее решение, и отличить того, кто реально понимает, от того, кто хорошо гуглит (или промптит), становится всё сложнее. Живые интервью становятся ценнее, потому что на них можно наблюдать процесс мышления, а не результат. Но на живых интервью affinity bias работает ещё сильнее, потому что ты сидишь напротив человека и твой мозг активно ищет сигналы "свой/чужой".
SHRM описывает этот механизм как "familiarity is experienced as competence recognition", и мне кажется, это самая точная формулировка проблемы, которую я видел. Знакомость ощущается как компетентность. Ты не принимаешь решение "выберу того, кто знает мой стек", ты принимаешь решение "выберу того, кто кажется более компетентным", просто компетентным кажется тот, кто знает твой стек. И structured interviews вроде как снижают этот bias на 40%, но я хз, сколько компаний реально проводят structured interviews для технических позиций, по ощущениям, большинство до сих пор работает в режиме "ну, поговорим, посмотрим".
Чёт я пока это писал, подумал, что сам, наверное, делаю то же самое, когда оцениваю чужой код или чьё-то резюме. Видишь знакомый стек и автоматически начинаешь относиться с большей симпатией, хотя умом понимаешь, что человек, который умеет думать, разберётся в любом стеке за пару недель. Возможно, осознание проблемы, это уже половина решения, но я не уверен.
9
14
151
15,592