
Principal Scientist at BetterUp Labs
Joined June 2012
- Tweets 76
- Following 18
- Followers 286
- Likes 70
12 Photos and videos
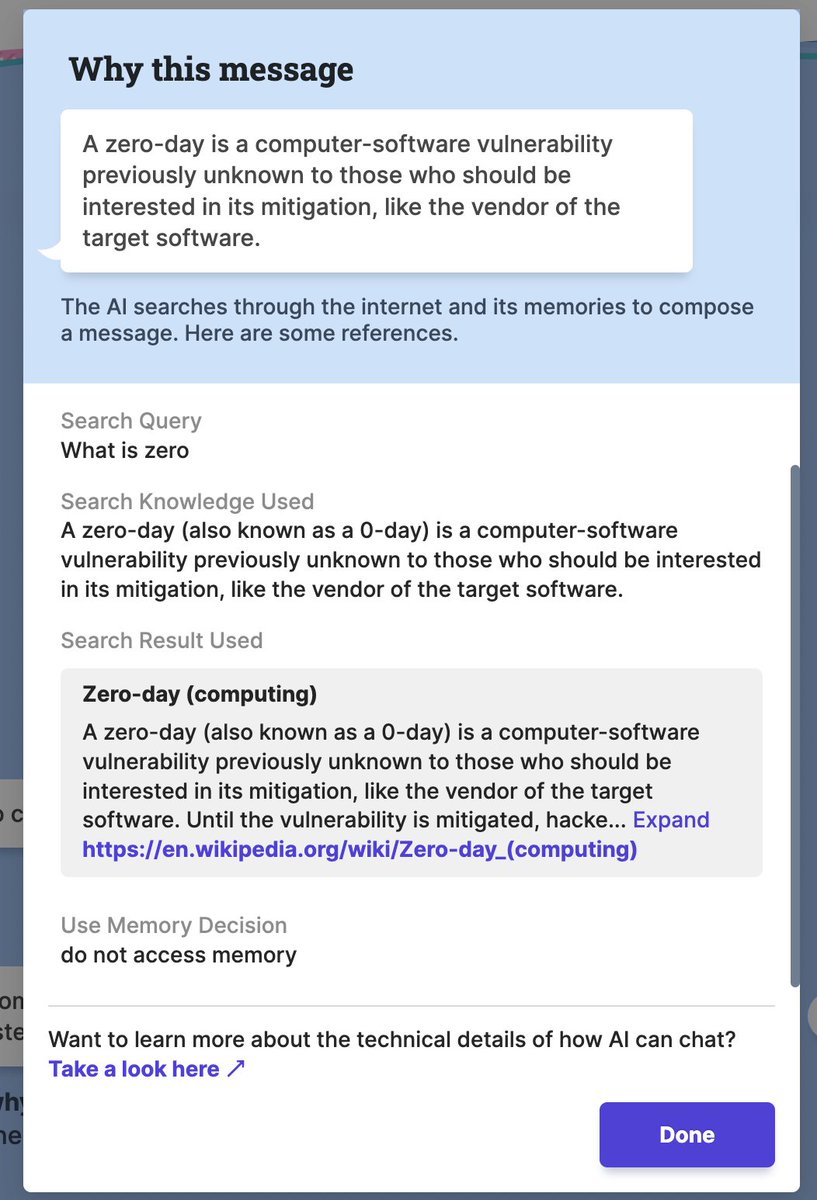
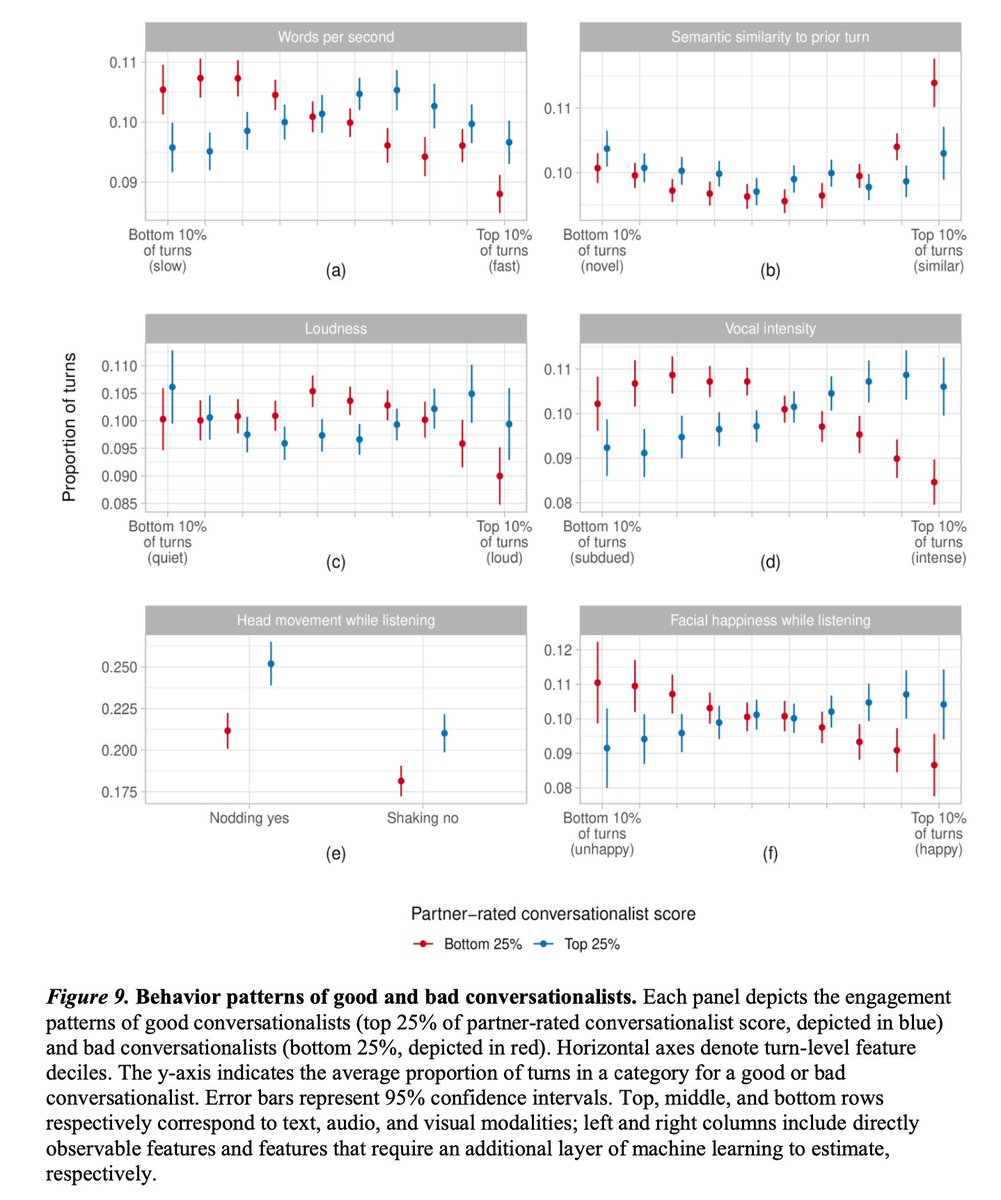
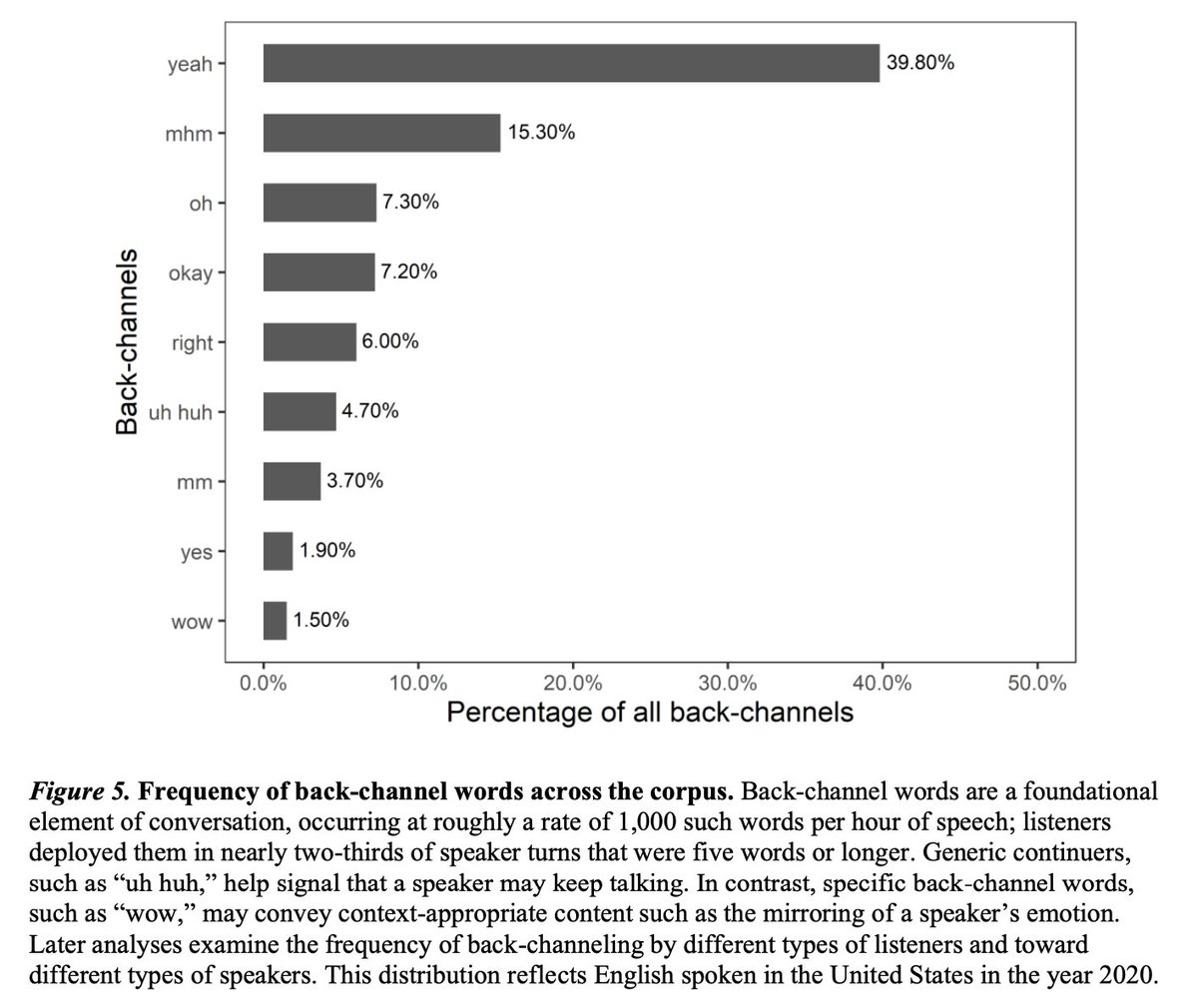
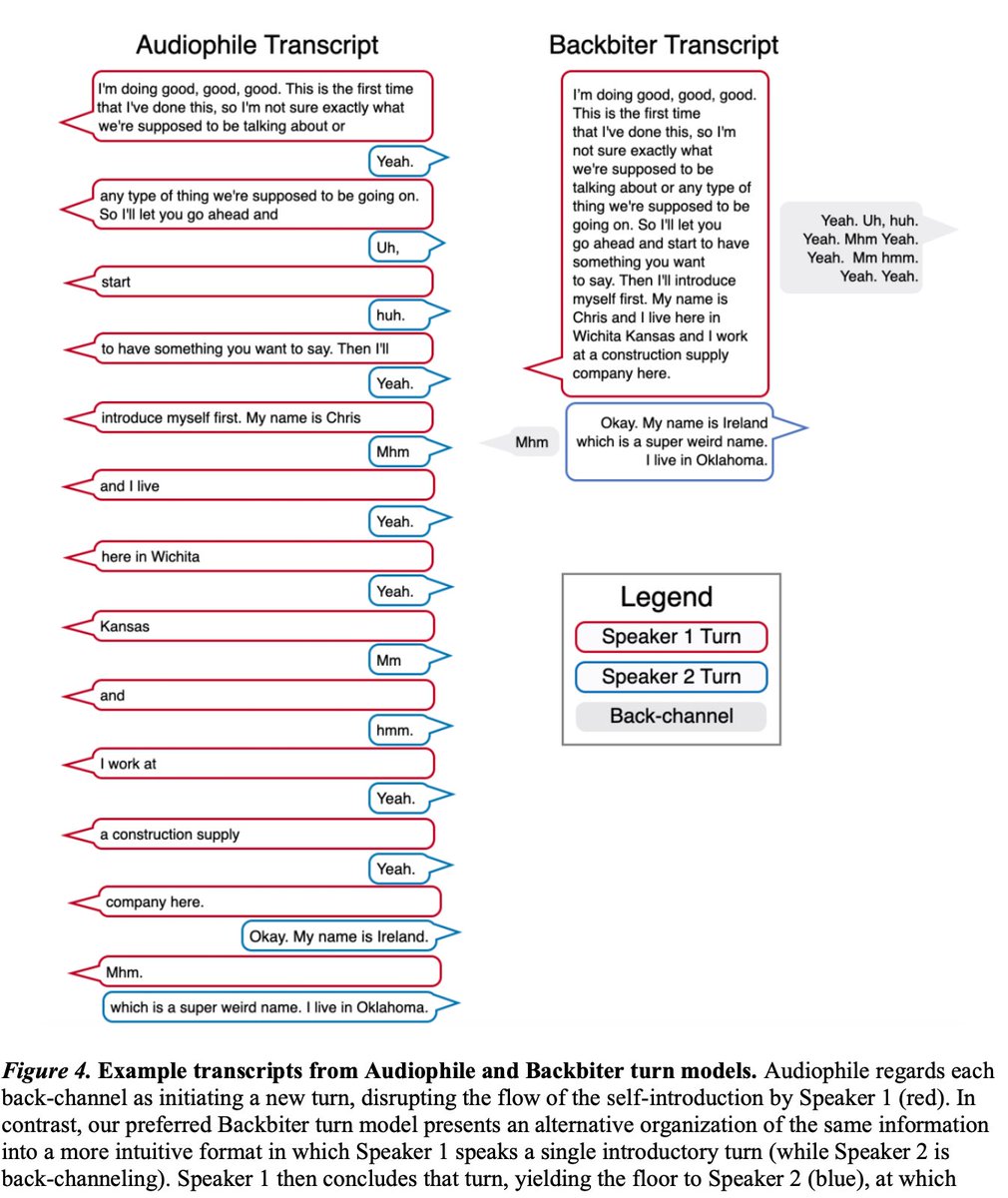

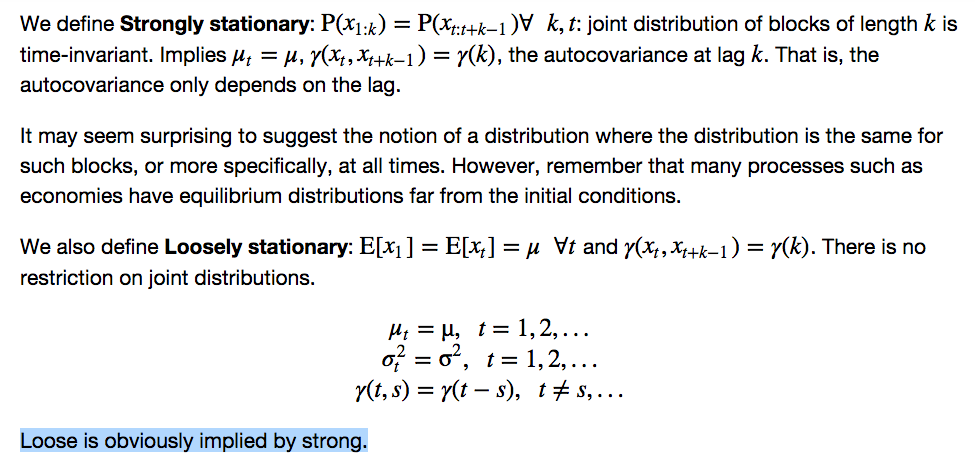


Pinned Tweet

Introducing the CANDOR corpus from @BetterUp: A 1TB, 850hr audio-video dataset of 1,656 unscripted conversations in America in 2020. CANDOR = Conversation: A Naturalistic Dataset of Online Recordings arxiv.org/abs/2203.00674
5
66
182
Andrew Reece | PhD Behavioral Data Scientist retweeted

4 Apr 2023
CANDOR corpus is now available! It took years of hard work, but we hope it will be useful for researchers from many fields interested in conversation and social interaction. Dataset available for download (link in manuscript). Please share it widely.
science.org/doi/10.1126/scia…
4
40
88
16,976
I asked 5 hard questions to two modern language AIs - Meta's new BlenderBot (blenderbot.ai) and OpenAI's GPT-3. Warning: Gets a little computer nerdy, but there are riddles and metaphysics too!
Answers and commentary in :thread:
2
3
5
GPT-3 (first answer):
def square_root_of_sum(foo, bar, baz):
return math.sqrt(foo bar baz)
Blender: 0 (but why)
GPT-3: 5 (bad indentation forgiven)
1
In sum, if it's going to be robot overlords I at least hope it's the one who doesn't have to Google my pleas
Introducing the CANDOR corpus from @BetterUp: A 1TB, 850hr audio-video dataset of 1,656 unscripted conversations in America in 2020. CANDOR = Conversation: A Naturalistic Dataset of Online Recordings arxiv.org/abs/2203.00674
5
66
182
Register here for free access to the CANDOR corpus: betterup-data-requests.herok…
2
1
11
Code/analysis files here:osf.io/fbsgh/
1
12