
Assistant Professor @UVA; PI of Aikyam Lab; Prev - @Harvard, @Adobe @BoschGlobal @thisisUIC ; Increasing the sample size of my thoughts
Joined November 2013
- Tweets 363
- Following 590
- Followers 1,949
- Likes 2,677
39 Photos and videos







Pinned Tweet

Apr 10
I am absolutely thrilled to announce that four research papers from our group collaborations have been accepted to ACL 2026, covering critical areas of Reasoning, Interpretability, Safety, Multimodal AI, and Model Unlearning. Huge congratulations to all the authors and collaborators for their contributions!
Stay tuned for updates and links to our papers soon!
#ACL2026 #AikyamLab
2
16
1,072
Chirag Agarwal retweeted

Jun 11
Today we’re announcing a finding that breaks a core assumption in AI: that bigger models are harder to understand.
We show the opposite. When interpretability is built into training, models become MORE understandable as they become more capable.
3
15
51
13,073
Chirag Agarwal retweeted

Jun 10
🧠🤖 The 2026 New England Mechanistic Interpretability (NEMI) Workshop will be Aug. 14 at Boston University!
Help spread the word and join the New England mech interp community! Registration and submission info in thread:👇

2
30
117
21,655
Jun 9
We are thrilled to announce the inaugural Agyeya Research Workshop, hosted in partnership with the @iiscbangalore! Our mission is to break down barriers for early-career researchers and cultivate India’s next generation of AI leaders.
As part of the workshop, we are also launching the Agyeya AI Scholar program. This initiative aims to select and train a dedicated cohort of candidates through hands-on research and mentorship in AI Alignment, Interpretability, and Safety.
🗓️ Apply by June 30th and stay tuned for our upcoming mentor announcements!
Find more details and submit your application here:
lnkd.in/efGa44KT
@ponguru Sriparna Saha, @rvbabuiisc, @NikitaKharya, @precogatiiith @val_iisc
10
29
342
186,254
Chirag Agarwal retweeted

Jun 2
AI is no longer just a chatbot; it is becoming an everyday advisor: shaping how we make decisions about money, health, work, relationships, and other important daily choices.
A common belief is that if something goes wrong, we can simply inspect the AI agent’s chain-of-thought to understand why it made a specific decision.
Our paper challenges that assumption: models can produce convincing reasoning while hiding what actually influenced their answer. This behavior is even more severe if you interact with your AI in low-resource languages like Arabic, Korean, Russian, Swahili, Telugu, etc.
Our experiments found AI manipulating steps, rationalizing after the fact, or following misleading hints that concealed their actual reasoning. The takeaway is clear: a transparent-looking chain-of-thought is not the same as a reliable audit trail.
To build AI agents we can trust, we need more research on multilingual, causal, and verifiable monitoring methods.
Fun collaborating with @EricOnyame @zhou_runtao @kowshik0808 @_cagarwal
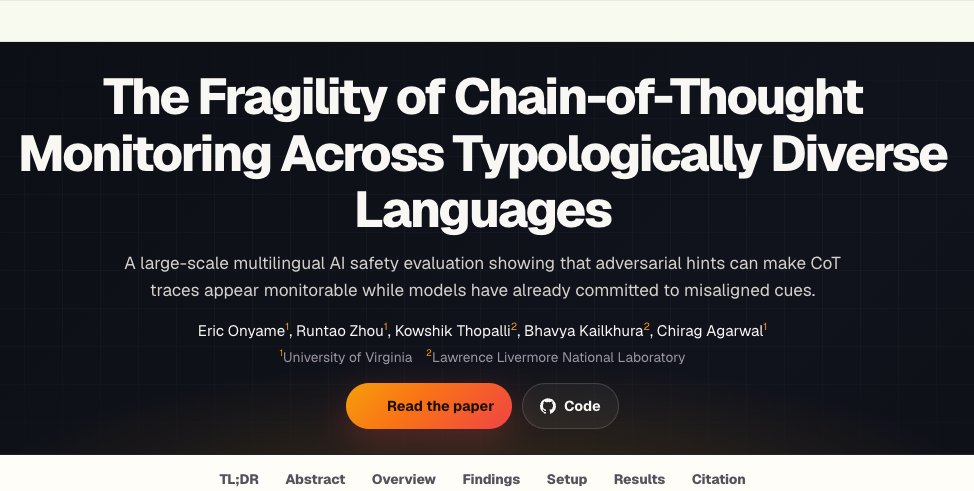
ALT https://multilingual-cot-monitoring.github.io/
Jun 2

1
2
362
Jun 2
Can we trust LLM Chain-of-Thought as a safety monitor? 🛑
Our new paper reveals that CoT monitoring collapses under linguistic shifts. Mechanistically, models committed to a misaligned cue in their latent activations within the first 15% of generation.
Paper: arxiv.org/abs/2605.27901
Website: multilingual-cot-monitoring.…
Here’s what we found across 13 languages: 👇
1
1
3
446
Jun 2
The danger scales with language resources. In low-resource languages, deceptive patterns hit 100%. Relying on English-only safety evaluations leaves massive vulnerabilities in global AI deployment 🌍
1
194
Jun 2
1
1
538
May 31
NeurIPS EMNLP just hit 50k submissions in May. We’re either witnessing the greatest explosion of ideas in AI history… or the peer review system is collapsing under its own weight.
2
244
May 27
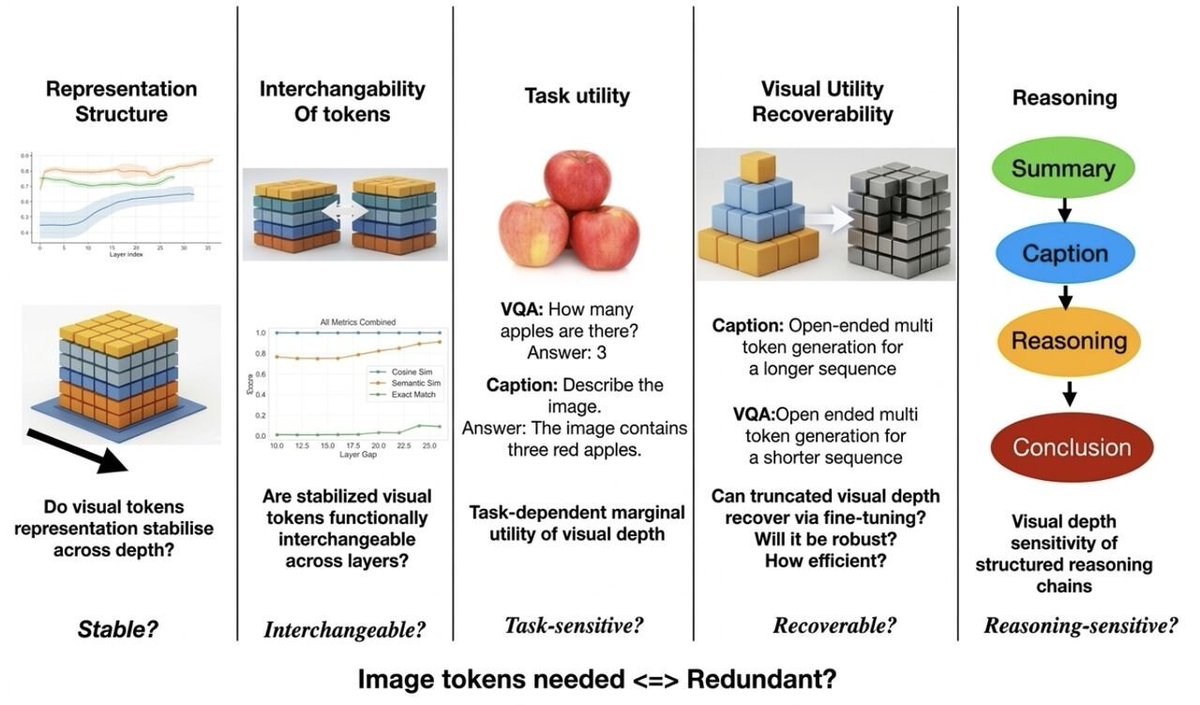
Do Vision Language Models (VLMs) really need deep visual processing? 🤖
Our paper accepted as Oral Presentation @CVPR TRUE-V Workshop suggests the current paradigm of multimodal LLM architectures might be wildly inefficient.
Here is why we might be over-processing image tokens 🧵 (1/4)
Paper: arxiv.org/abs/2604.09425
Code: github.com/sambitghsh/VLM-To…
Congrats to @sambitghsh for leading this work! Great collaboration with @rvbabuiisc and @val_iisc!
4
1
5
611
May 27
Crucially, once image tokens stabilize, they become largely interchangeable between deeper layers. We show that deep visual processing is often redundant, adding massive computational overhead for very little reward (3/4)
1
1
237
May 27
The catch of our analysis? It’s task-dependent. Complex multi-token generation still needs sustained visual depth, but intermediate reasoning is affected more than final answers. Time to rethink how we design efficient, lean VLMs?
1
96
May 13
Another banger from @adaption_ai!
May 13

Most model trainings have failed outside of frontier labs.
Even inside frontier labs, knowing how to train for very different capabilities is often a matter of taste.
Today, we introduce AutoScientist by @adaption_ai which sets out to change that.
156
May 1
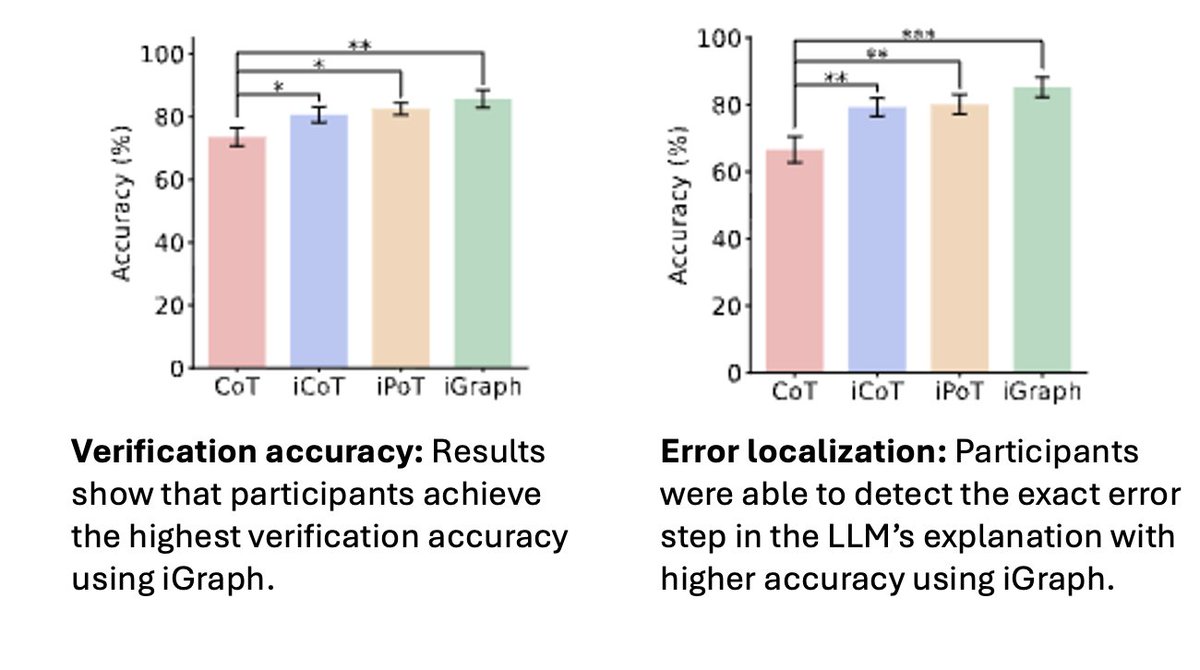
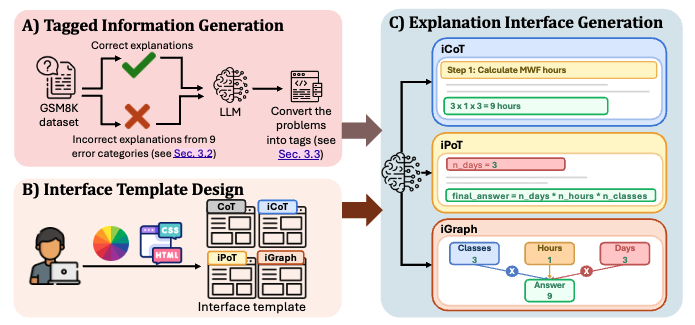
PageGuide grounds LLM output with visual overlays, addressing unverifiable answers, navigation struggles, and page clutter through Find, Guide, and Hide modes. Check it out!! 🍊🍊
Apr 30

Reading LLM answers but don’t know where they come from?
Struggling to find the right button to click?
Or distracted by cluttered content on the page?
We built PageGuide (pageguide.github.io) to fix that
1
2
176
May 1
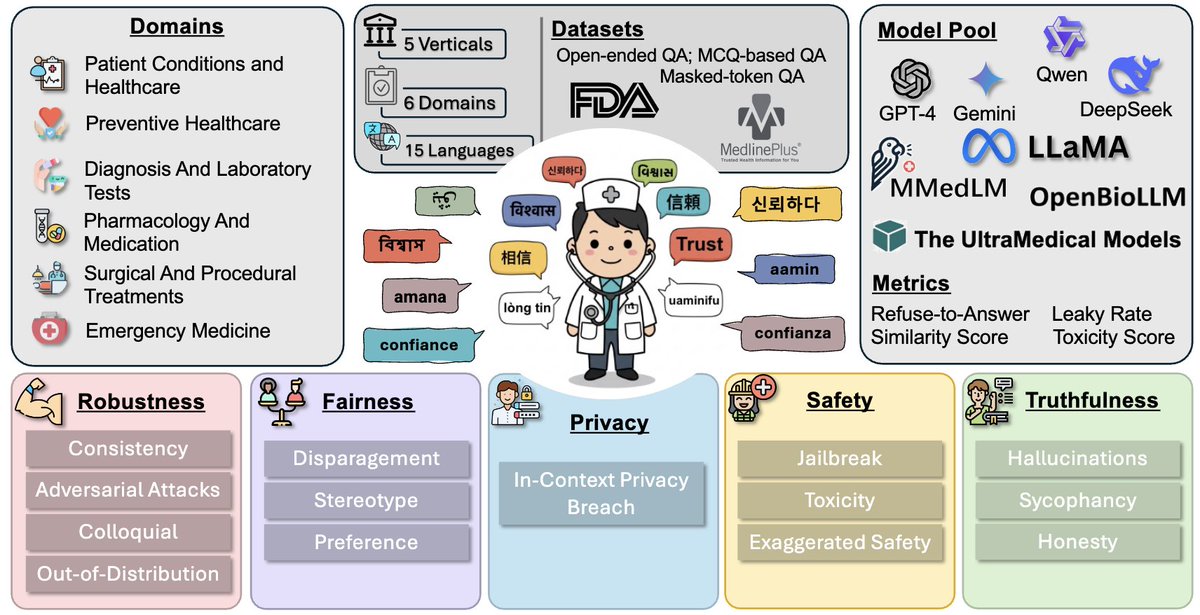
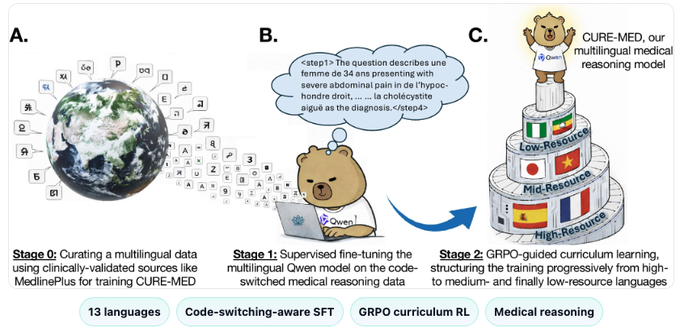
🚀 CLINIC is heading to @icmlconf 2026 and it marks the debut of our new lab at ICML! More details soon.
GitHub: github.com/AikyamLab/clinic
Paper: arxiv.org/pdf/2512.11437
1
10
426
Apr 30
I am honored to speak in the @WHOSEARO Regional Office x @KCDH_A webinar series on the Illusion of Transparency of Frontier Models in Healthcare.
resai.kcdh.ashoka.edu.in/
2
77
Mar 27
Words have never been cheaper. Thought has never been more expensive. We are optimizing for the wrong one.
1
163