
Joined August 2019
- Tweets 506
- Following 450
- Followers 11,968
- Likes 1,399
91 Photos and videos













Pinned Tweet

6 Oct 2023
I believe the top question in most tech investors' minds is - "where are we in AI?"
I wrote a piece from the perspective of someone who spends a lot of time thinking about the public markets AND speaking with private companies
runrate.substack.com/p/scali…
3
8
80
53,504
Jun 12
We've come a long way ! Full circle moment for $SPCX Evaluating SpaceX was my first assignment at @AltimeterCap😅
Congrats to @AntonioGracias and all my former colleagues at @valor on their hard work & success in helping build one of the most consequential companies of our lifetimes
And thanks to all the incredible teams at SpaceX for allowing us to partner along the way
Ad Astra 🚀
11
2
234
17,465
Jun 2
$NVDA Jensen at Financial Analyst session in Taipei:
"At earnings we announced an $80B share repurchase and a 25x increase in dividend and also said we would review our dividend on a regular basis.
Today we plan to return of 50% or more of FCF to our shareholders this year and next year. And beyond... to infinity and beyond"
5
23
233
30,270
May 21
Just my my math speculation:
Pre Xai deal
OAI at ~2.5GW / Anthro at ~2GW
- Renting NVDA ~$13B/Yr/GW (hyperscalers / CRWV financials)
- Assume mix of Trainium/TPU is 50% discount per GW
- Then Anthro spending ~$13B for ~2GW then = ~$1B / mo of spend
So adding this deal for COLOSSUS and COLOSSUS II = $1.25B / mo of spend
That means after this deal, $NVDA penetration of Anthropic compute stack = >50% instantly...
That's something Jensen mentioned on the earnings call: "And so we're growing - and our coverage of Anthropic has been largely 0 until just recently. And so we're gaining share tremendously in inference"
Based on studying the industry I'm pretty sure that math is right...
Even assuming Trainium / TPU is 25% discount then this deal puts Nvidia compute penetration at Anthropic at 40%!
anyone else have different analysis?


14
19
237
63,517
May 11
Nick’s one of the best, glad he’s finally showing his smarts to the world :) @coatuemgmt
8
10
248
68,228
Apr 30
Wow, I missed this post by Gavin. Exactly on point, and excellent. Not biased, some of the points he describes are good for NVDA, bad for NVDA, good for ASICs, bad for ASICs, good for China, bad for China. But word for word, ‘insight’ encoding super high in this post. Truth dense
Apr 16

Much of Dwarkesh's argument hinges on this statment which *was* accurate but will be increasingly inaccurate on a go forward basis imo:
“American labs port across accelerators constantly. Anthropic's models are run on GPUs, they're run on Trainium, they're run on TPUs. There are so many things you can do, from distilling to a model that's well fit for your chips.”
As system level architectures diverge (torus vs. switched scale-up topologies, memory hierarchies, networking primitives), true portability is eroding. The Mi300 and Mi325 had roughly the same scale-up domain size as Hopper while Blackwell’s scale-up domain is 9x larger than the Mi355 scale-up domain, etc.
Many frontier models are now being explicitly co-designed for inference on specific hardware like GB300 racks. Codex on Cerebras is another example. Those models run less efficiently on other systems and the performance differentials will only widen. A model that runs well on Google’s torus topology will run less efficiently on Nvidia’s switched scale-up topology and vice versa - the data traffic is fundamentally different as a byproduct of the models being parallelized across the different topologies.
Google’s internal teams - and increasingly the Anthropic teams as they become the most important customer of almost every cloud - have the luxury of operating across the stack (models, chips, networking) - but that is not the case for the rest of the market and other prospective users. Anthropic is the exception, not the rule. To wit, Anthropic and Google allegedly have a mutual understanding where Anthropic can hire the TPU engineers they need every year to ensure that they can continue to get the most out of the TPU.
Given the overwhelming importance of cost per token to the economics of the labs, models will be run where they run best. Most extremely large MoE models will run best on GB300s given the importance of having a switched scale-up network like NVLink for MoE inference. When training was the dominant cost for labs and power was broadly available, labs were optimizing to minimize capex dollars. Model portability was a way to create leverage over suppliers. I think that drove a lot of the focus on portability.
Today, inference costs as measured by tokens per watt per dollar are everything. Inference is way more important than training costs (inference is effectively now part of training via RL). Labs are therefore now optimizing for inference. This means increasing co-design and higher go-forward switching costs for individual models between systems. I do think this explains why Anthropic and Nvidia came together: Anthropic needed Blackwells and Rubins to inference at least *some* of their models economically. And Mythos might just end up being released coincident with the availability of Rubins for inference.
TLDR: as labs shift their focus from training to inference, the costs of portability and the upside of co-design to maximize tokens per watt per dollar both rise. Portability is likely to begin decreasing as a result.
I think what I might have respectfully added to Jensen’s answer is that systems evolve under local selective pressures.
The evolutionary pressure in America is a shortage of watts so it makes sense for Nvidia to optimize, as an American company, for power efficiency and tokens per watt and stay on copper as long as possible. China has a surfeit of watts. Chinese AI systems are already taking advantage of this with the Huawei Cloudmatrix 384 and Atlas SuperPoD having an optical scale-up domain that is much larger than anything offered by Nvidia today at the cost of *much* higher power consumption and much lower tokens per watt. The networking primitives for this Huawei system are very different than those for Nvidia’s systems and a model that runs well on Nvidia will not run well on that system and vice versa. This means that if a Chinese ecosystem gets momentum, Chinese models might stop running well on American hardware. And when Chinese models run best on American hardware, America is in a better position as this gives America a degree of leverage and control over Chinese AI that it risks losing to an all-Chinese alternative ecosystem.
This architectural fork makes porting and distillation less effective and strengthens the pro-American national security case for selling China deprecated GPUs imo.
Also I will attest that I did not wake up a loser this morning.
5
4
148
47,314
Apr 22
Doing some prep work today and this new OpenAI image model is super cracked... It's just super steerable, incredibly smart, the one-shot end product that comes out is just magical...
3
19
4,458
Clark Tang retweeted

Apr 20
we will start benchmarking companies by their revenue generated per token ($/token) in the same way industrial companies look at $/kwh. not saying that other costs (labor etc) won't exist, they will just be a much smaller fraction.
11
14
207
35,006
Apr 6
Sundar telling you we're memory constrained and explains the jevon's paradox of software efficiency gains
but but... fintwit told me about TurboQuant? 😭😭

5
10
179
41,468
Mar 30
I am always baffled by how investors always confidently think that they know better than management
Lord give me the confidence of a 24 year old broccoli hair pod boy telling a memory CEO that his business is cyclical, because he read it in a BofA primer last tuesday
44
11
609
158,041
Mar 30
Actually unfair to pick on the pod boy now, because it's actually the boomer PMs who are in the driver's seat now !
bUt YoU aRe A cYcLiCaL bUsInEsS👴
2
46
11,487
Mar 27
In 2.5 years we have a 99.7% reduction in cost to serve iso-intelligence !
In any other market in the world, this level of compression would have destroyed the underlying market.
But we are still supply constrained... why? We saw this in the early days of the internet. The human world of atoms is geared for linear growth - exponential growth is something our brains can't really grok... Supply chains, multi industry dependencies, all exist to cap the growth of the underlying.
So you just have to look at the data...
4
16
64
9,818
Mar 27
Memory optimization in software generally falls into 3 buckets:
byte destruction (truely reduce bits consumed)
byte relocation (largely engineering mix shift from HBM -> DRAM -> NAND)
friction removal (effect: remove deadweight loss)
helpful framework to interpret new news..!
2
8
66
10,745
Mar 25
Reading twitter investor's takes on this being a structural breaker to memory is so ... dunning kruger
Like sure, no one thought to compress their KV cache until Google publicly released this technique when it was the single biggest pressure on their business !!!
😁
Mar 24
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
23
10
228
57,170
Mar 25
Will leave this here: Jeff Dean on Latent Space Feb 12 26
"We’re trying to push the frontier of 1 million or 2 million context, which is good because I think there are a lot of use cases where. Yeah. You know, putting a thousand pages of text or putting, you know, multiple hour long videos and the context and then actually being able to make use of that as useful...
I think we’re very convinced that, you know, long context is useful, but it’s way too short today. Right? Like, I think what you would really want is, can I attend to the internet while I answer my question? Right? But that’s not going to happen. I think that’s going to be solved by purely scaling the existing solutions, which are quadratic. So a million tokens kind of pushes what you can do. You’re not going to do that to a trillion tokens, let alone, you know, a billion tokens, let alone a trillion. But I think if you could give the illusion that you can attend to trillions of tokens, that would be amazing. You’d find all kinds of uses for that. You would have attend to the internet. You could attend to the pixels of YouTube and the sort of deeper representations that we can find. You could attend to the form for a single video, but across many videos, you know, on a personal Gemini level, you could attend to all of your personal state with your permission. So like your emails, your photos, your docs, your plane tickets you have. I think that would be really, really useful. And the question is, how do you get algorithmic improvements and system level improvements that get you to something where you actually can attend to trillions of tokens? Right. In a meaningful way."
2
38
3,880
Mar 16
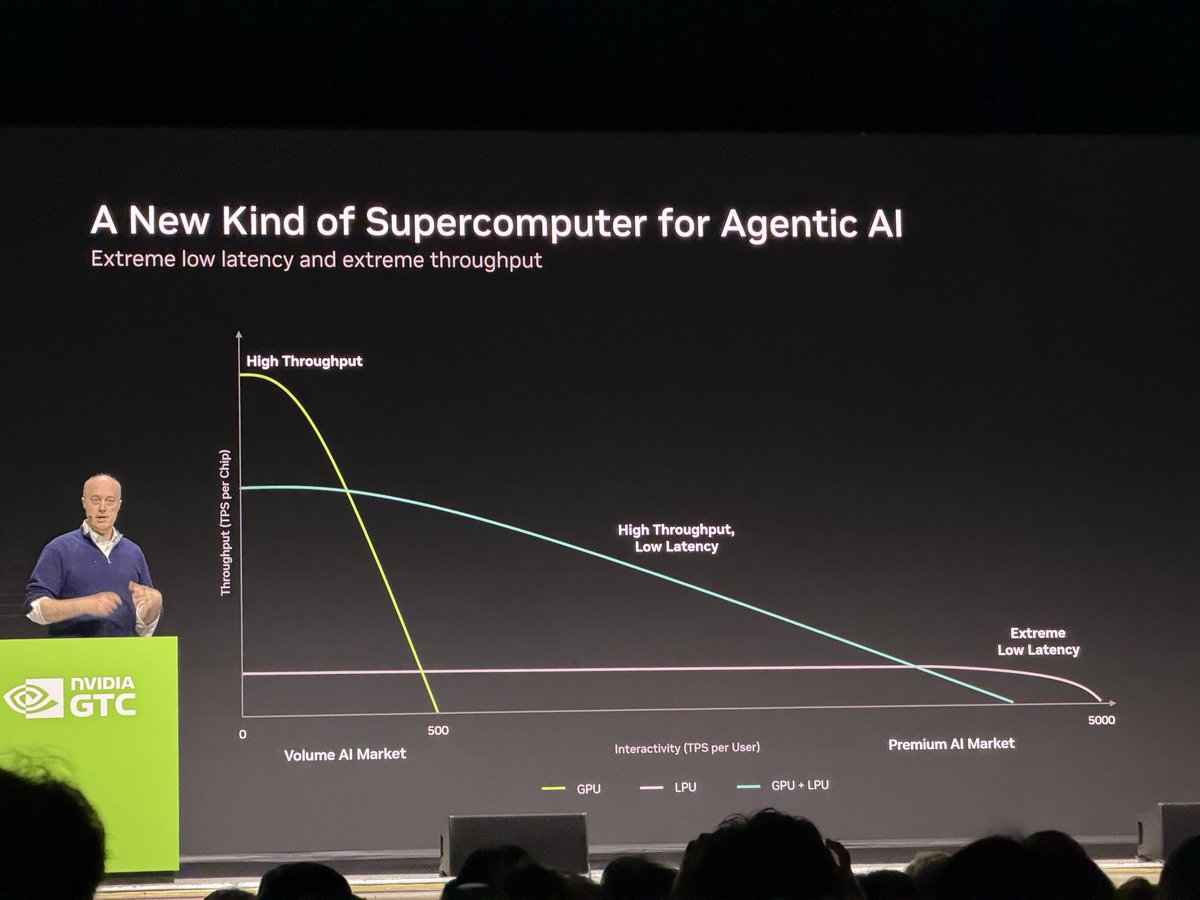
Ian buck presentation actually really great and compelling - explaining why we need to push out to pareto frontier (agent swarms), why we need to push higher token /s.
Why the hybrid architecture of GPU LPU is much better than just GPU or LPU standalone… pretty awesome
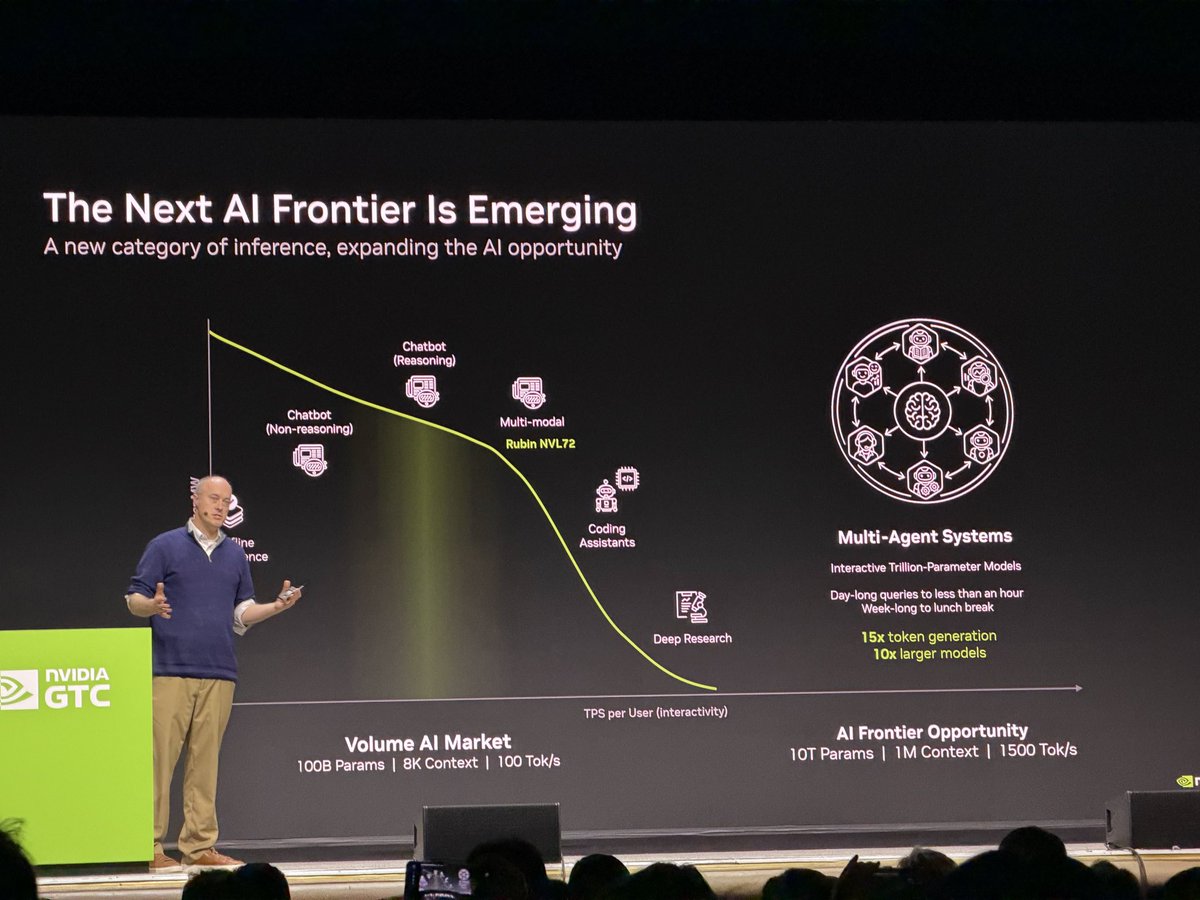
4
16
113
14,957
Mar 2
One of the biggest debates in the compute buildout: are these underlying businesses unprofitable and that there is no way to sustainably finance the investment cycle that we are undertaking.
And I get it – we are spending a lot of money – likely $700B of capex in 2026 amongst the hyperscalers alone. This year, the hyperscalers will build about 20GW of incremental IT capacity. How will we pay for this?
Built a framework to pressure test this – how the major players across multiple sectors monetize a GW of IT capacity.
Before we get into things, want to quickly explain my methodology & frameworks - all this analysis is meant to be a useful framework to get people thinking. These are just my views – do your own work! Validate / reject my premises! We are all our own agents in this world.
That said, unless otherwise noted, all metrics are based on publicly available information from latest calendar year (2025). The adjustments: CoreWeave operating margin of 15% is based on a discounted view on their publicly disclosed 20-30% LT margins / Oracle's 20% target LT margins on GPU cloud business. There is a lot of debate / discourse in the market on what the eventual margins there could be. For illustrative purposes on this chart, I've left them at 15% which largely assumes a shorter depreciation cycle than they have assumed, plus no incremental margins from software. This is akin to the early days of AWS - which in 2015 disclosed they were a 17% operating margin business, while creeping that balance up to 40% over 10 years (spoiler, did so with software!).
OpenAI and Anthropic figures are based on publicly rumored figures of ARR and GW deployed and allocating a portion to "inference" vs "training" compute (I am assuming 60/40 for OAI, more training for Anthro). For instance - OpenAI has disclosed that their ARR at end of 2025 was roughly $20B which coincides with a power footprint of 1.9GW - a ratio of $10.5B ARR / GW. Part of that footprint is not revenue generating and is just training. Someone pushing back could say that is a feature, not a bug of a frontier AI lab – I don't agree, because it all depends on the slope of inference growth. Anthropic has had remarkably amazing utilization of their limited resources over the years. From my outside in work, contribution margins are awesome. Finally, note that for the chart, I use estimated GM% instead of OP%, this is for a visual framework and should leave an upper bound on the profitability of these businesses which are fundamentally "different software businesses than past ones".
I included Snowflake & Salesforce Rev / GW just to add some context. After all, these are the 2000s and 2010s era companies that are powered by compute. I derived their figures by dividing AWS Rev / GW by product gross margins. For the chart, Snowflake OI uses Non-GAAP OP% from CY25 as they are negative on a GAAP basis.
-----------------------------------
Ok with that out of the way, what is the point of the analysis I present?
A couple of observations:
1/ A lot of this analysis is meaningless! Why? Because for Snowflake or Salesforce, this Revenue / GW is an output, not an input. They are simply not in the business of selling repackaged power – they are selling VALUE / utility. In the case of Snowflake, an infrastructure SW company, they are running a feature rich scaled cloud data warehouse at scale. This took a decade of R&D, refinement, continuous development – and is selling you a product that is reasonably hard to duplicate. But they cannot grow their business by just adding power. GW consumption is the output, not the input. The same holds true for Salesforce, or any other software company. Rather, these products are somewhat difficult to sell, due to the large contract values, duration of engagement, etc. Given their raw COGs are relatively low, a majority of their gross margin is invested into S&M to sell the product.
2/ Google and Meta are THE most profitable businesses from a pure monetization / GW. In fact, before the current datacenter investment cycle starting in 2022, these businesses' Revenue / GW were significantly higher. Critics say that the new AI business models are less profitable than their core ads business. And they are completely correct. In fact, Jensen always says this in his speeches – the truth is that in the world of retrieval based software, ads were the most profitable businesses known to mankind. 90% contribution margin, with hardly any need for any S&M, with a baked in 20% growth algorithm per year by increasing the efficacy of the ads. But the truth is at some point, this algo slows down - scale slows down. In the same way software businesses could not grow their business by building power, these businesses could not either, there was a natural rate of adoption on these businesses, tweaked over the year with ad load and engagement.
3/ Infrastructure providers largely monetize at ~8-12B / GW and are the closest to the underlying hardware. I have a whole post in my drafts on this (still working!)... The thing I want to call out on the hyperscalers / neoclouds is that the core rental business of hardware usually starts out at ~10-15% operating margin. You can trace this back to the early days of AWS (which I may add, also was criticized as hugely money losing before they showed the world how profitable it was). Everyone thinks of these businesses as 40% EBIT businesses, which they largely are, but that was built over the years by selling software attached to their hardware. The core EBIT margins of just the hardware without adding value services is usually around 10-20%. Core cloud ARR / GW is closer to $12B / GW - you can derive this from AWS disclosures on power. The new accelerated compute infrastructure is around $10B of ARR / GW which is consistent from OCI, CRWV, and Nvidia. The way they all move to higher OP margin is attaching software to it at significantly higher blended gross margins -- the same way the hyperscalers built this during the 2010s.
4/ The model providers. Most controversial / interesting in this post. But perhaps the most applicable here. I am reminded most of the mid 2010s of Uber / Airbnb / Netflix and people / media claiming that these businesses would never make money. But it's all about the unit economics. If you can make 50-70% gross margins, then you can choose to allocate those GM dollars in a few ways. You gain significant operating leverage at scale. And my guess is gross margins likely move higher (another discussion for another time). But of note, VS the past generation of companies, the research compute budget is the significant outlier. This will likely be further concentrated at a certain time - continue to decrease as a % of the company budget, and more inference innovation techniques will be pushed - most of the benefits to consumers, while incremental ~3-5% GM gains will be kept per year...
One of the great realizations in this exercise is that there are many ways of balancing a business to make money. In the case of software, they are hugely efficient / profitable from a "GW" perspective - and as a result, invest all their earnings into S&M to sell their product, which leads to a OP margin that is relatively low. For the hyperscalers, their gross margins are notably lower than their SaaS counterparts, but because their business is so large and have a high degree of trust with their customers, they are able to attach a considerable amount of their first party software while spending considerably less than their SaaS peers to sell that incremental $, yielding significantly higher operating margins. The internet providers are both hugely profitable, and need to invest little in their business, so really grew bloated over the years, investing in frivolous things and innovation grinding to a halt... until AI came along. Now they have a great target to invest in, with likely ways to enhance their core as well.
In the case of AI – in the past few months, we have just crossed the uncanny valley of "model usefulness". They have largely gone from moderately useful chatbots / research tools, to very useful autonomous & agentic. Therefore, the name of the game will quickly shift to inference throughput & latency optimizations. As long as we are riding this S-curve, more compute = more revenues = more operating leverage for the model providers. And we are just starting...
On this latest Nvidia earnings call, Jensen was asked how the hyperscalers will pay for their investments. He replied:
"I am confident in their cash flow growing... in this new world of AI, compute is revenues... I am certain at this point that we are at the inflection point, we've reached the inflection point and we're generating profitable tokens that are productive for customers and profitable for the cloud service providers."
For me, this switch flipped in the middle of 2025 - and really took off in late last year. Opus 4.5 and GPT 5 were tremendously valuable models, that were incredibly useful. We're seeing it now from the testimonies of the likes of Karpathy, etc. But anyone paying close attention to this knows / feels like everything has changed. Inference & usage is in take off mode & these profitable tokens are at the core of it all.
These views are my own – not a view of Altimeter. Do your own research & look forward to discussing!
30
94
582
97,783
Mar 2
I think this goes without saying, but as long as your revenue generated per GW > cost per GW and you’re monetizing that way, you get to contribution positive margins
2
17
6,765
Feb 19
A few years ago, I heard this quote from one of the leading labs: "GPUs are the only appreciating asset in the world"
Despite being a huge AI bull, I scoffed at the idea - because my mind has always been hardwired with the basic principles of supply & demand, commoditized compute, ROIC, etc
As I watch the world unfold these days, I increasingly think that it seems like this person was right - or at the very least, the economic "depreciation curve" of these assets don't look like those of traditional assets. Let me explain:
Accountants depreciate assets typically straight-line over a fixed useful life, or in some cases on an "accelerated timeline" (more depreciation up front). The first originated to match the "revenue generative potential" of an asset with the "depreciating nature of equipment".
AKA - my washing machine breaks down in ~5 years, as a Laundromat I should write the value of the asset down to 0 over 5 years
However, this only holds true if the economic value someone is willing to pay for the asset is relatively stable
What the labs were suggesting, was that the economic value of what each GPU could produce was about to multiple many-fold. They found that each time they trained a smarter model, a stepfunction increase of more people willing to pay for that model would be unlocked. Not only this, but all the while, they increased the efficiency of each GPU by many-fold.
What does this look like in practice? Say I took 1,000 H100s - if before I could serve 10K concurrent users' requests on GPT-4 with this amount of compute, I can now serve GPT-5.2 (a vastly better and more economically valuable model) to 200K concurrent users. Think about it analogously to your early iPhone -- I spend $500 for an awesome phone, but every year I get to upgrade it for free with vastly improved features (iOS 2 --> iOS 10 in 1 year). I was able to hire a college student before for $10/hr and now I can hire 20 grad students for the same fee.
My "fixed costs" per unit of compute are the same through this period -- but I theoretically should be "willing" to pay 20x more for this compute. (In practice a lot of the the optimizations are kept with the labs to be economically viable, and the rest is passed to the consumer as surplus)
This is all known and good, but now the next step function change in my mind is Seedance 2.0. Everyone on X raves about this model, but we haven't even begun to scratch the surface of the economic value creation / destruction that is about to occur because of it. Video generation is an insanely compute intensive process, but is fractional compared to the budget of an A-list movie (Transformers budget $100M and years of filming production is compressed into weeks)
Consider that all of these models are running on H100s and H200s and Blackwells are just beginning to roll out (and be debugged)
The economic value to the world of an H100 is vastly higher than it was when it was first sold in 2023.
In practice, we have to balance this thought experiment with the fact that new compute will be vastly more performant than Hoppers. I say all of this, and the reality is that Hoppers will probably depreciate the most when Blackwells take over - the performance gains are just too massive & flops shipped will rise by a lot. At the same time, we continue to invent new and more economically valuable ways to monetize this compute.
Consider that any practical usuable videogen was breakthrough just 6 months ago (Sora 2), and we now can potentially have user (or small business) directed movies. In the short term - can always have distortions of consumer surplus and producer surplus - but over time, law of economic gravity and value delivered always find price equillibriums...
It would shock me if by this time next year, we don't find the next breakthrough in useful "general compute" -- drug discovery, physics, material science, robotics, etc.
This is an S curve & this is what it feels to ride one...
Just some random thought dumps today - happy to discuss !
25
28
224
29,009