
witnessing the magic (preagi)! 🪄 ~ opinions and posts are my own.
Joined September 2020
- Tweets 67
- Following 740
- Followers 210
- Likes 2,345
6 Photos and videos




May 11
📲 Released today: “About the security content of iOS 26.5 and iPadOS 26.5”
support.apple.com/en-us/1271…
2
205
deven retweeted

May 8
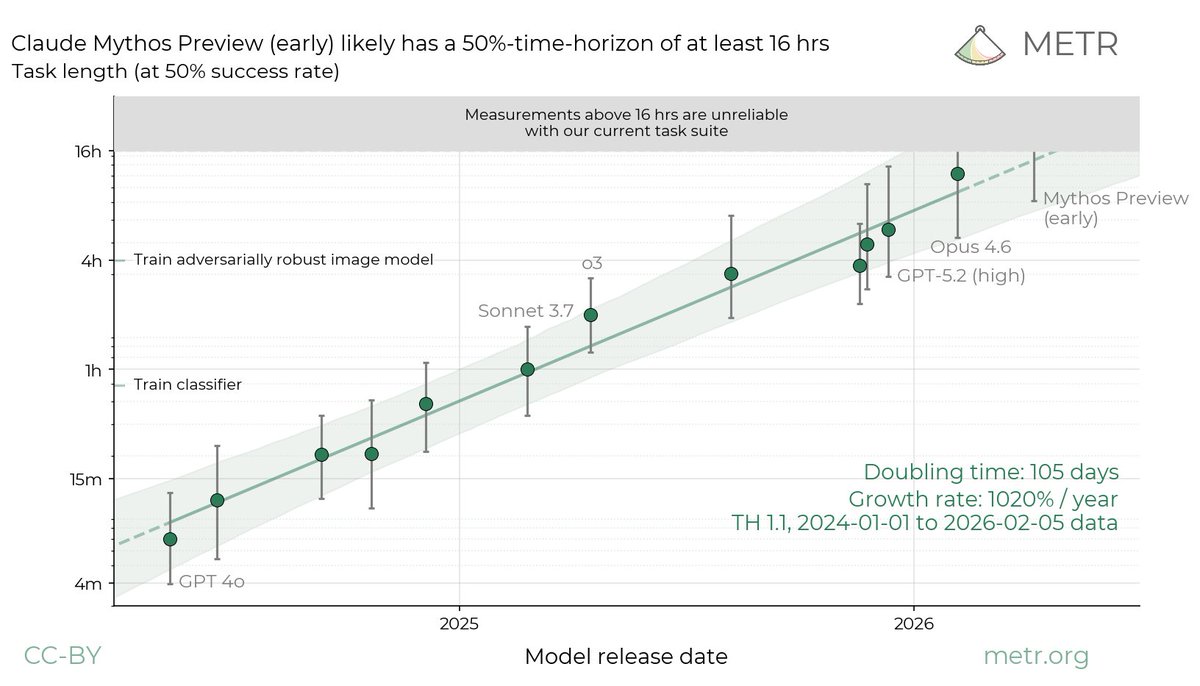
We evaluated an early version of Claude Mythos Preview for risk assessment during a limited window in March 2026. We estimated a 50%-time-horizon of at least 16hrs (95% CI 8.5hrs to 55hrs) on our task suite, at the upper end of what we can measure without new tasks.
69
239
2,083
977,575
May 8
Current sci-fi timeline: Models learn to hide reasoning in RL. Safety observed this. OpenAI publishes. Next training ongoing (sees this).
And…we’re still early!
May 7

We recently found some instances of CoT grading during the training of previously deployed models after building a system that scans all OpenAI RL runs for accidental CoT grading.
We did not find clear evidence that these instances degraded CoT monitorability.

1
180
Apr 22
About the security content of iOS 26.4.2 and iPadOS 26.4.2
support.apple.com/en-us/1270…
3
155
Mar 24
Today: About the security content of iOS 26.4 and iPadOS 26.4
support.apple.com/en-us/1267…
1
198
deven retweeted

Feb 26
🔺NEW: iPhone and iPad are now the first and only generally-available devices to meet the exacting security requirements for handling classified NATO information. apple.com/newsroom/2026/02/i…
18
95
344
47,275
Feb 11
Today - About the security content of iOS 26.3 and iPadOS 26.3 (Feb 11 2026)
support.apple.com/en-us/1263…
2
416
12 Dec 2025
Today: About the security content of iOS 26.2 and iPadOS 26.2
support.apple.com/en-us/1258…
1
232
3 Nov 2025
📲 Today: About the security content of iOS 26.1 and iPadOS 26.1
support.apple.com/en-us/1256…
1
8
967
10 Oct 2025
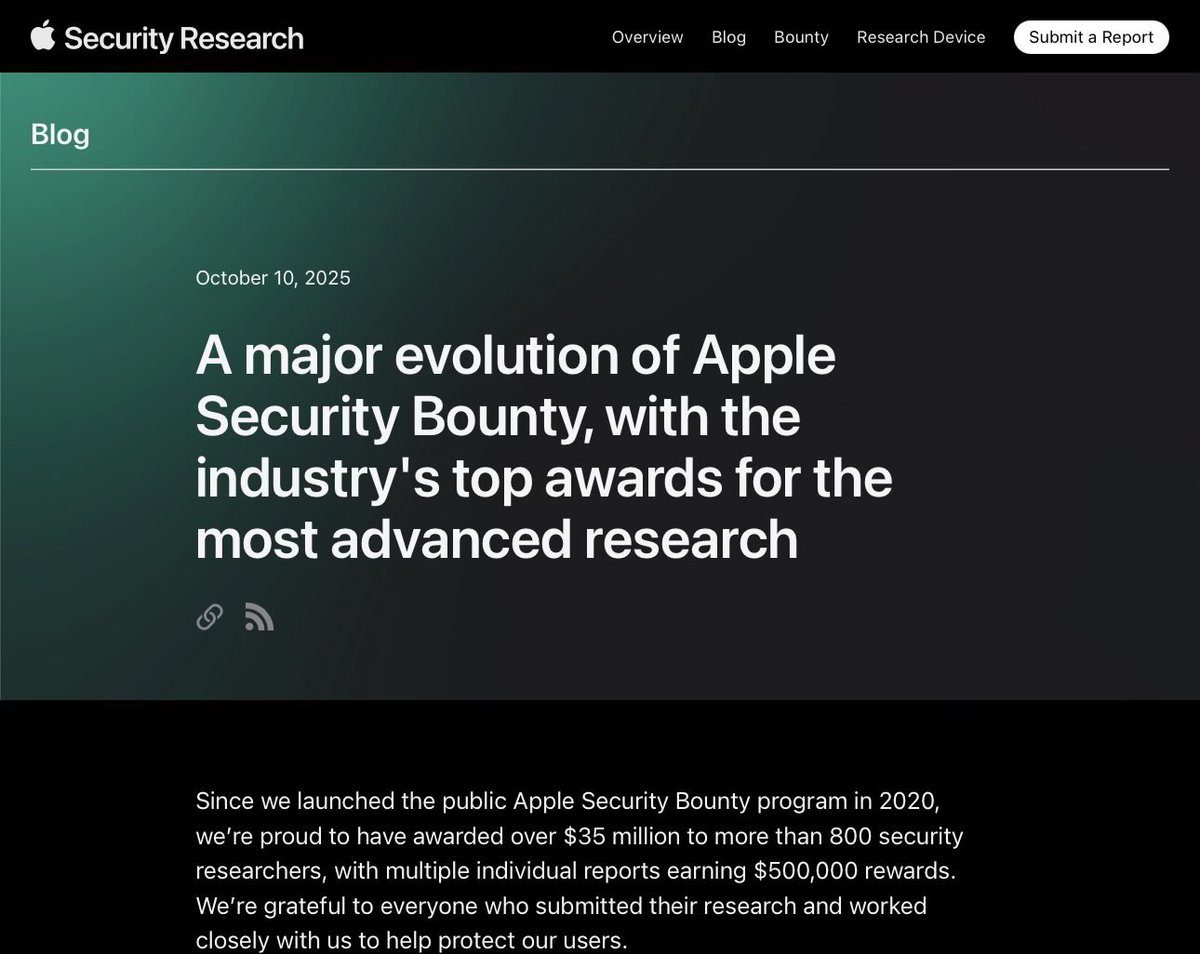
“A major evolution of Apple Security Bounty, with the industry's top awards for the most advanced research”
security.apple.com/blog/appl…
1
1
16
840
29 Sep 2025
📲 Today: "About the security content of iOS 26.0.1 and iPadOS 26.0.1"
support.apple.com/en-us/1253…
6
490
deven retweeted

19 Sep 2025
We’re thrilled and honored to reveal our second keynote speaker: Ivan Krstić (@radian)
Any guesses what he might talk about? 😉
2
21
63
11,133
15 Sep 2025
📱Today: About the security content of iOS 26 and iPadOS 26 - support.apple.com/en-us/1251…
5
21
3,358
deven retweeted

3 Sep 2025
2026 Apple Security Research Device Application is now live. Apply at security.apple.com/research-…!
* Arbitrary code with arbitrary entitlements
* Arbitrary code injection into existing processes
* Arbitrary SPTM, TXM, KernelCache firmwares
* Downgrades to old builds
* ...and more
1
43
181
22,289
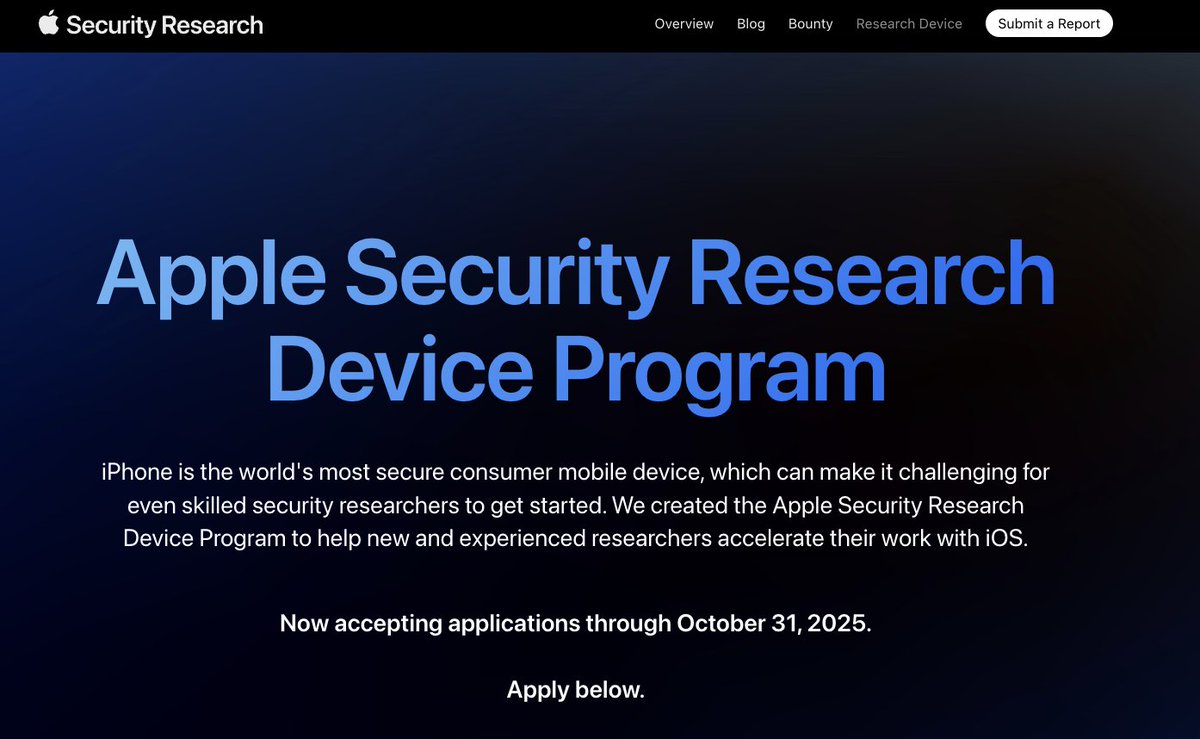
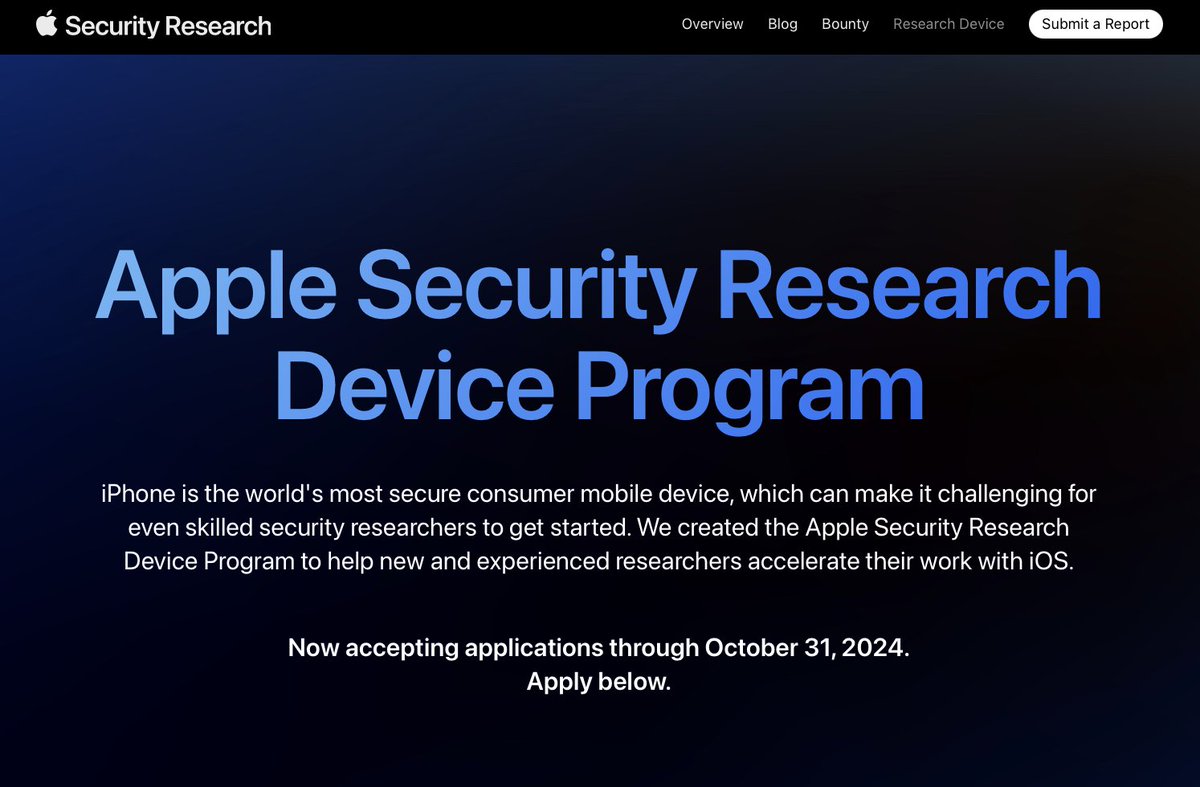
3 Sep 2025
🍎 Apple Security Research Device Program – Now accepting applications through October 31, 2025.
1
4
19
3,071
20 Aug 2025
📲 Today: About the security content of iOS 18.6.2 and iPadOS 18.6.2
support.apple.com/en-us/1249…
2
12
3,333
deven retweeted

14 Aug 2025
✨We're hiring an AI Software Engineer @apple!
Join the Interlinked team and completely reimagine software with AI.
⬇️ Details in thread

ALT Apple job posting featuring the Apple logo on a plain background. The position is "AI Software Engineer • Interlinked" located in Cupertino, California, United States.
1
6
9
1,420
29 Jul 2025
About the security content of iOS 18.6 and iPadOS 18.6
support.apple.com/en-us/1241…
3
237
12 May 2025
🍎 Apple security releases today! support.apple.com/en-us/1001…
📲 About the security content of iOS 18.5 and iPadOS 18.5 support.apple.com/en-us/1224…
2
6
721
16 Apr 2025
🍎 📲 Today – About the security content of iOS 18.4.1 and iPadOS 18.4.1
support.apple.com/en-us/1222…
1
330