
!= 280 characters
Joined August 2012
- Tweets 1,296
- Following 360
- Followers 732
- Likes 941
91 Photos and videos






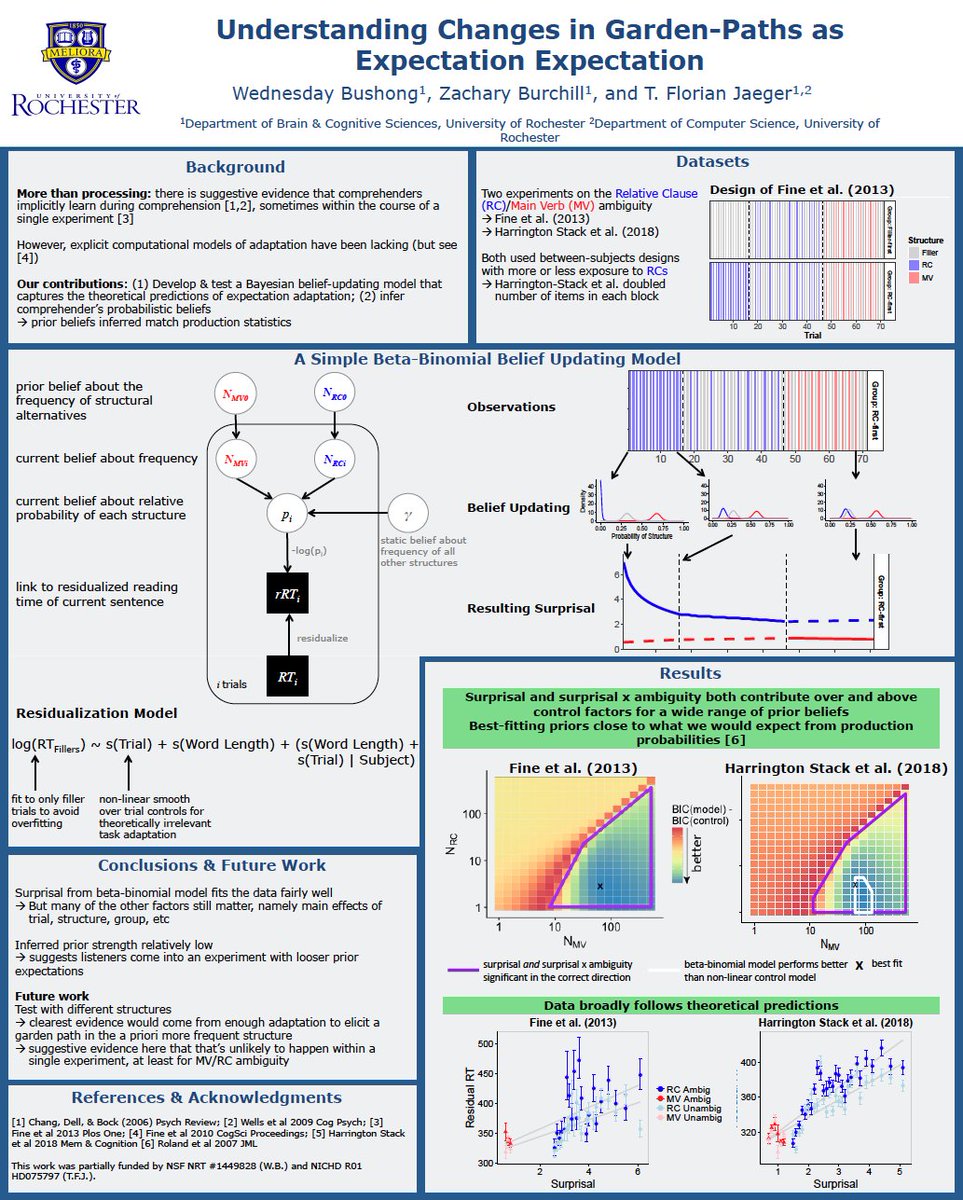


1 Oct 2025
Faculty opening in computational neuroscience and cognition, including language, development, learning through the lifespan, etc.
30 Sep 2025

We’re hiring a tenure-track Assistant Prof in Computational Neuroscience/Cognition at
@uor-braincogsci.bsky.social! Join a Simons-supported cluster across Math/Physics/Biology/BCS. Apply by Nov 1, 2025: sas.rochester.edu/bcs/jobs/f… #ComputationalNeuroscience #Cognition #FacultyJobs
121
30 Sep 2025
New R library STM bsky.app/profile/hlplab.bsky… by Santiago Barreda implementing incremental vowel normalization & categorization (Nearey & Assmann's PSTM). New paper that describes & uses that STM to model vowel perception bsky.app/profile/hlplab.bsky…
2
103
30 Sep 2025
The OSF repo also contains a vignette for the R library, as well as a walk-through of the bootstrap analyses we applied. Hopefully this will make it easy for others to apply this model to their own data! osf.io/tpwmv/. Feedback welcome.
75
30 Sep 2025
(P)STM infers vowel & talker-specific normalization parameters from single observations, predicting listeners' perception far better than other common normalization models (incl. Lobanov or C-CuRE).
60
12 Aug 2025
Very excited about this: putting distributional learning (DL) models of adaptive speech perception to a strong, informative test sciencedirect.com/science/ar… by Maryann Tan. We use Bayesian ideal observers & adapters to assess whether DL predicts rapid changes in speech perception 1/2
1
133
12 Aug 2025
DL captures human speech perception both *qualitatively* & *quantitatively* (R2>96%) for over 400 combinations of exposure and test items. Yet, previous DL models fail to capture important limitations. Specifically, we find that DL seems to proceed by remixing prev experience 2/2
109
T. Florian Jaeger retweeted

7 Feb 2025
🚨Exciting news! We now have the first-ever complete #EEGManyLabs replication. This large-scale multi-site study revisits a key debate in EEG & reinforcement learning. A thread! 🧵👇
📄 Full paper: doi.org/10.1016/j.cortex.202…
1
32
87
10,992
T. Florian Jaeger retweeted

23 Jan 2025
More than 40 percent of #postdocs leave academia. Those who landed a coveted faculty position were more likely to have had a highly cited paper, changed their research topic between their #PhD and postdoc, or moved abroad after receiving their doctorate. pnas.org/doi/10.1073/pnas.24… @PNASNews -> nature.com/articles/d41586-0… #ScienceCareer
15
518
1,700
303,867
T. Florian Jaeger retweeted

21 Jan 2025
Please share: Postdoctoral position available in high-resolution retinal imaging and video eye-tracking at the University of Rochester.
buff.ly/4ja5fKj
@aplabUR @CVSUoR @URNeuroscience @RochesterOptics @FlaumEye
8
12
1,081
23 Oct 2024
For how long is information about past speech input available in short-term memory? What evidence would inform this question? What does (not) follow from previous work on this question? Delighted to see this work by @klintonbicknell @_wbushong_ in JML sciencedirect.com/science/ar…
4
2
546
23 Oct 2024
Feedback welcome! & see @_wbushong_ 's thesis for more on this topic, and her very cool computational simulations--presenting a new effort to better understand what can be inferred from the types of data collected in studies on subcat infomaintenance during speech perception. /n
1
238
23 Oct 2024
But Bayesian mixed-effect analyses also identify a previously undocumented tendency in all 4 datasets--unexpected under all existing accounts. We present initial simulations that suggests that a combination of attentional lapses & ideal integration might explain the data. /3
186
23 Oct 2024
We show existing evidence is compatible with ideal maintenance & integration of uncertainty, and derive a stronger test of that hypothesis. 2 re-analysis & 2 new experiments find that the ideal observer's predictions fit listeners' behavior better than previous proposals /2
173
23 Oct 2024
We revisit the classic work by Connine and colleagues, and show why its results are often misinterpreted. Using an ideal observer framework, we derive what would be expected if listeners maintained and integrated subcategorical information beyond word boundaries. /1
171
T. Florian Jaeger retweeted
20 Sep 2024
A new study from co-author Chigusa Kurumada reveals that difficulties in adapting to changes in speech patterns may affect how adolescents with autism understand tone and meaning.
#URochesterResearch @UofR_Psych
20 Sep 2024

Verbal communication isn’t just about words—it’s also about how we say them
Teens with autism can have a difficult time understanding changes in tone and timing in speech
A new study from Rochester neuroscientists reveals why
#URochesterResearch urmc.info/1Jr
2
3
655
21 Aug 2024
Great, super accessible, 3-step tutorial for running experiments online sites.google.com/view/reo-tu… by Chigusa Kurumada (kinderlab.bcs.rochester.edu/) @UoR_BrainCogSci @UofR
2
5
587
20 Aug 2024
Can't wait for this to arrive at my door! (t - 1.5 months)
14 Apr 2024

Delighted to announce the upcoming release of my new book this fall, a culmination of my life and work to date:
us.macmillan.com/books/97803…
1
446
16 Aug 2024
A wonderful resource for anyone working with R & Praat to analyze phonetic & speech data. marissabarlaz.github.io/port…
4
9
1,163
30 May 2024
Another neat paper by Xin Xie and Chigusa Kurumada: an initial attempt to measure adaptive changes with prolonged, repeated exposure to second language-accented speech (over 4 weeks) insightful discussion of methodological challenges that arise frontiersin.org/journals/psy…
1
382