
Research Intern @AdobeResearch, CS Ph.D. student @UWMadison | prev. intern: @AdobeResearch; @Krafton_AI
Joined October 2023
- Tweets 55
- Following 647
- Followers 118
- Likes 326
9 Photos and videos




Pinned Tweet

Apr 16
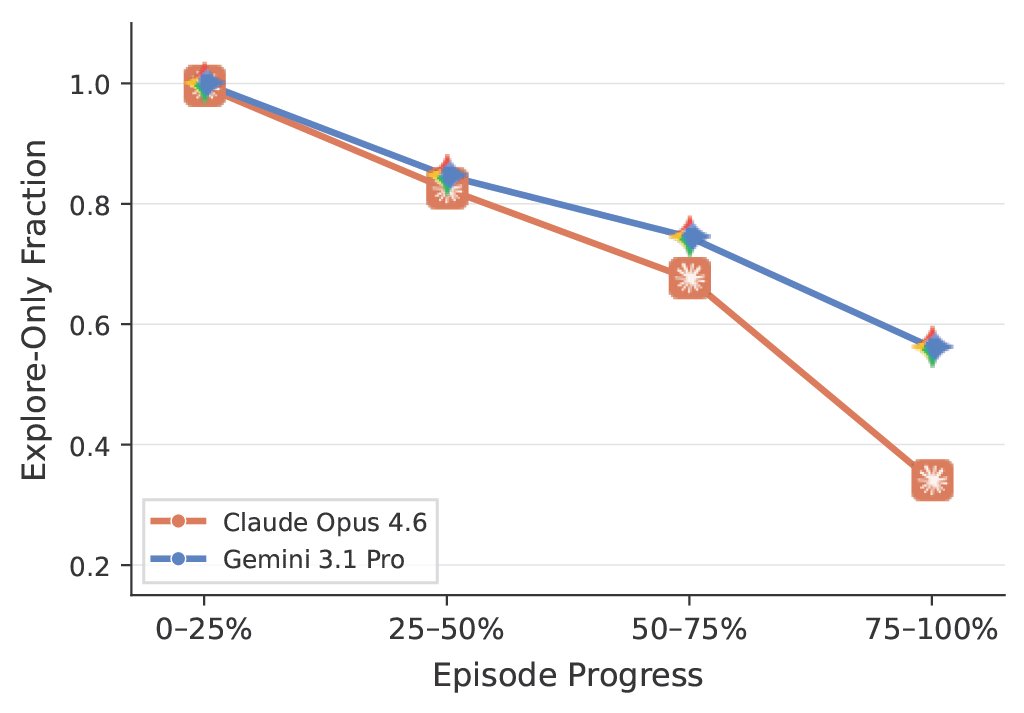
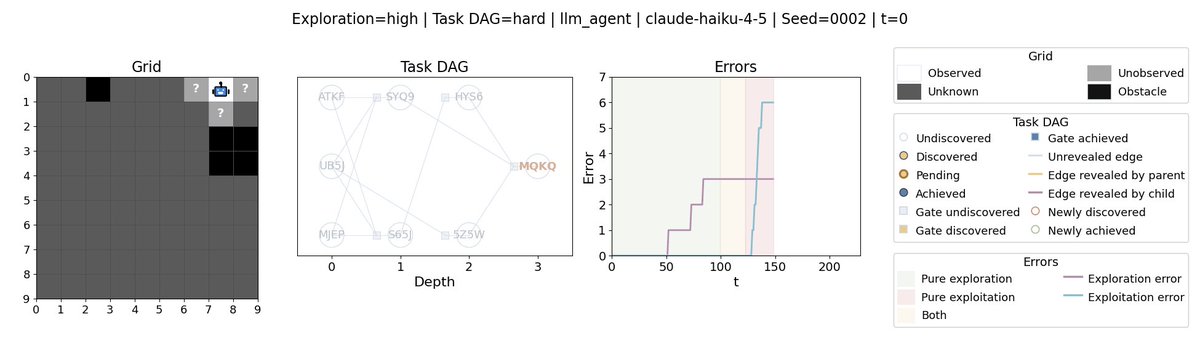
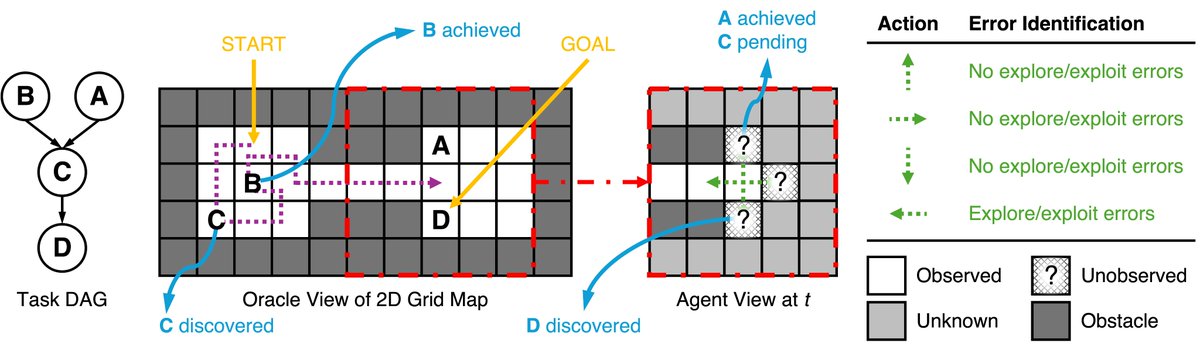
We all knew LLM agents struggle to explore, but we had to eyeball it 👀. We couldn't measure exploration errors. Until now. 🗺️🤖
We built a policy-agnostic metric to quantify exploration and exploitation errors in LLM agents.
Spoiler: Exploration error is what kills📉 agent performance in our setting 👇🧵(1/8)
1
17
31
2,145
Jaden Park retweeted

Jun 10
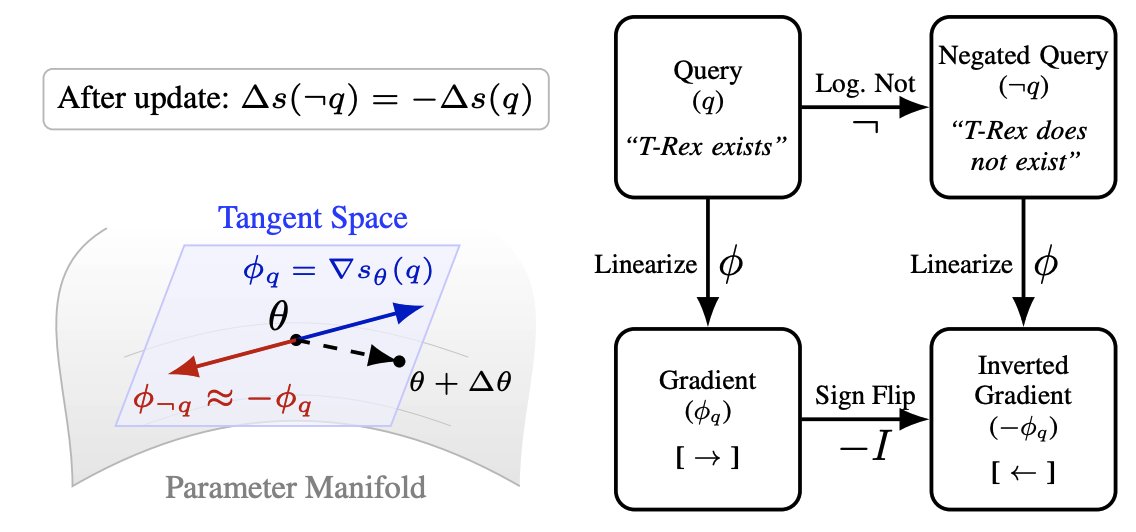
The reversal curse. Edits that don't suppress negations. Multi-hop updates that don't propagate. These look like separate bugs.
Our ICML 2026 spotlight argues they may share a common geometric origin, visible only when you study how representations move under updates 🧵
(1/11)
3
18
81
9,080
Jaden Park retweeted

Jun 9
Almost all "flagship" models are now MoEs.
But smaller models still prefer to be dense as they target memory-constrained scenarios where total params matter.
So we ask: Can we leverage an MoE to produce dense models without having to train them from scratch?
🧵👇

1
7
50
2,942
May 1
Lots of good news this week! 🚀
1. My internship project from @AdobeResearch has been accepted to #SIGGRAPH2026!
("MAOAM: Unified Object & Material Selection with Vision-Language Models")
Special thanks to my wonderful mentor @michi_fischer who has made this project possible!
2. Paper accepted to #ICML2026!
("DocHop: Benchmarking Out-of-domain Multi-hop Reasoning in Information-Dense Documents")
3. Paper accepted (with minor revisions) at #DMLR!
("Decomposing Complex Visual Comprehension into Atomic Visual Skills for Vision Language Models")
In both papers, we generate carefully designed benchmarks to tackle compositional/multi-hop reasoning in VLMs. Proud to have contributed in these projects.
More detailed posts soon :) Stay tuned!
1
3
23
684
Jaden Park retweeted
Apr 16
We all knew LLM agents struggle to explore, but we had to eyeball it 👀. We couldn't measure exploration errors. Until now. 🗺️🤖
We built a policy-agnostic metric to quantify exploration and exploitation errors in LLM agents.
Spoiler: Exploration error is what kills📉 agent performance in our setting 👇🧵(1/8)
1
17
31
2,145
Apr 20
I will be at #ICLR2026 to present my work on data contamination in VLMs! (Fri, Apr 24, 2026 • 8:30 AM – 11:00 AM, Pavilion 3 P3-917)
I am currently interested in VLA/physical AI, agents and robustness/generalization.
Would love to chat and connect with anyone with similar interests :)
7 Nov 2025

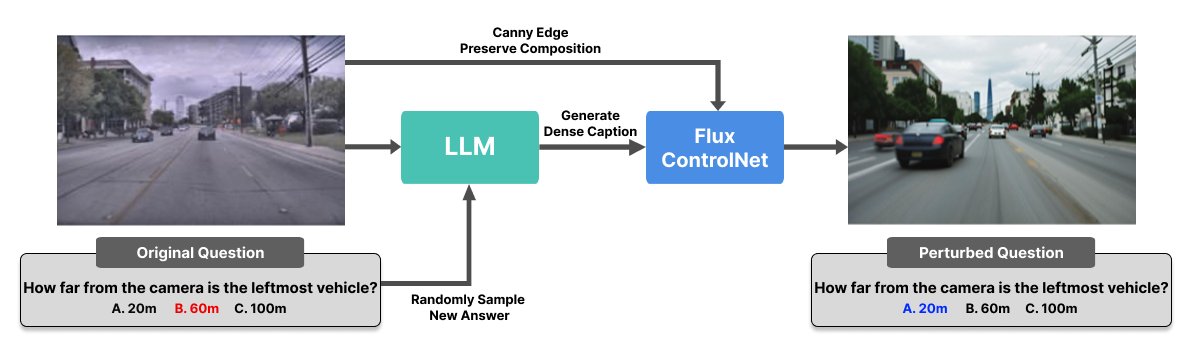
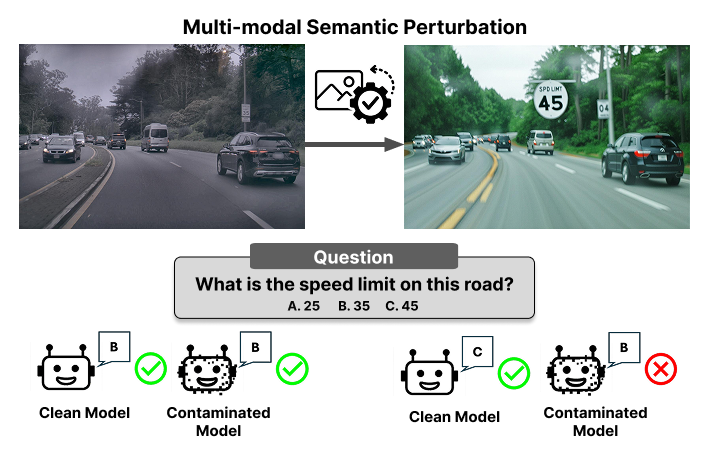
Me: memorize past exams 📚💯
Also me: fail on a slight tweak 🤦♂️🤦♂️
Turns out, we can use the same method to 𝗱𝗲𝘁𝗲𝗰𝘁 𝗰𝗼𝗻𝘁𝗮𝗺𝗶𝗻𝗮𝘁𝗲𝗱 𝗩𝗟𝗠𝘀! 🧵(1/10)
- Project Page: mm-semantic-perturbation.git…
2
18
958
Apr 16
We all knew LLM agents struggle to explore, but we had to eyeball it 👀. We couldn't measure exploration errors. Until now. 🗺️🤖
We built a policy-agnostic metric to quantify exploration and exploitation errors in LLM agents.
Spoiler: Exploration error is what kills📉 agent performance in our setting 👇🧵(1/8)
1
17
31
2,145
Apr 16
Can we improve exploration failures in LM agents? 🛠️
🗺️ Exploration Prompts: Explicitly injecting exploration strategies increases success rate by 17%.
📝 Explicit Harness: Providing the agent with structured summaries of its past observations; success rate boost by 29.4%! 🧵(7/8)
1
5
206
Apr 16
This was a joint co-first author work with @jungtaek_kim and @jongwonjeong123, with the guidance from @rdnowak, @Kangwook_Lee and @yong_jae_lee.
If this sounds interesting, please check out our paper 📄 arxiv.org/abs/2604.13151!
If you have any questions, feedback, or new ideas, I'd be more than happy to discuss!🧵(8/8)
6
297
Apr 8
Excited to be back at @AdobeResearch this summer where I will be working with @Shramanpramani2 :)
Would love to connect with anyone who will be around!
1
6
120
Jaden Park retweeted

Mar 28
🔥 Upgrade your frozen vision encoders with <10 lines of code!
Single-scale inference throws away vital details. Enter MuRF 🚀: a simple, training-free plug-in for instant, massive gains in MLLMs, Seg & Depth. 🤯 1/6

7
25
147
28,381
Jaden Park retweeted

Mar 19
🚨New work with @Meta @RealityLabs
We introduce EGAgent, an agentic reasoning framework for very long video understanding powered by entity scene graphs
Why? With long multimodal data streams, agents must search and reason across multiple modalities!
🧵 (1/n)
2
8
19
2,060
Jaden Park retweeted

Mar 19
New paper out! 🚨 Introducing STTS: Unified Spatio-Temporal Token Scoring for Efficient Video VLMs. We tackle the massive token bottleneck in video models by jointly identifying the tokens that actually matter. The overall figure below breaks down the core problem! 🧵👇

1
4
19
4,738
Jaden Park retweeted
Mar 16
Hi ML Twitter!
My Summer 2026 internship unfortunately fell through last minute 😵💫
If your team is looking for interns, I’d love to connect - RTs appreciated 🙏
My website: aniketrege.github.io/
17
29
266
34,725
Mar 13
There should be a meta-conference where reviewers are Claude Code.
(1) Claude Code figures out how to run your code like TerminalBench.
(2) Claude Code tries to run your code for 48 hours.
If Claude Code can't beat your Table 1 in 2 days of vibe-research, it gets accepted ✅.
1
3
201