
61 Photos and videos




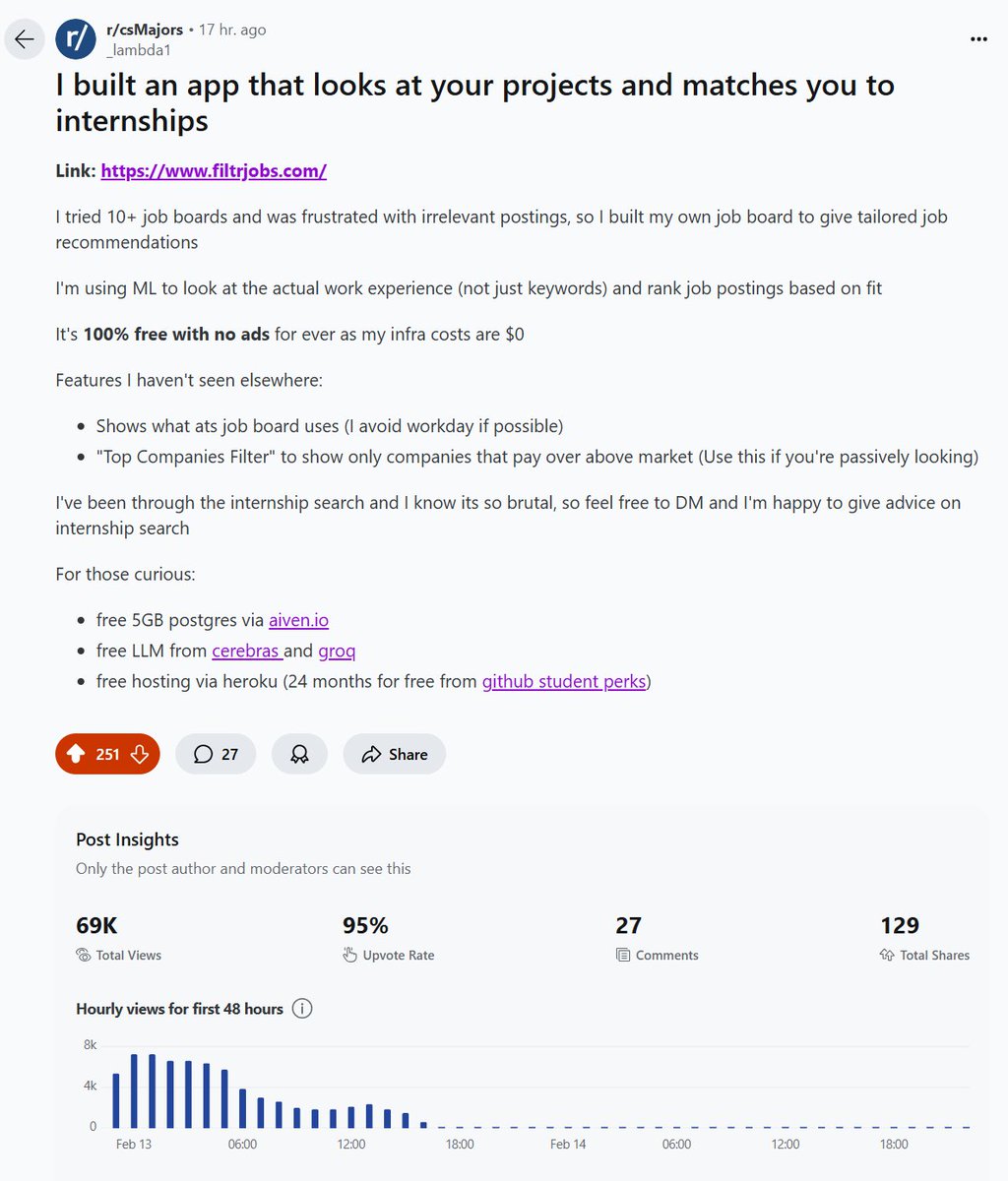



I built an an app that looks at your resume and gives tailored job recommendations rocketjobs.app/landing
Thanks to @togethercompute free llama I'm running this for 0$ so this app is free forever no ads
3
11
1,679
lambda retweeted

29 Sep 2025
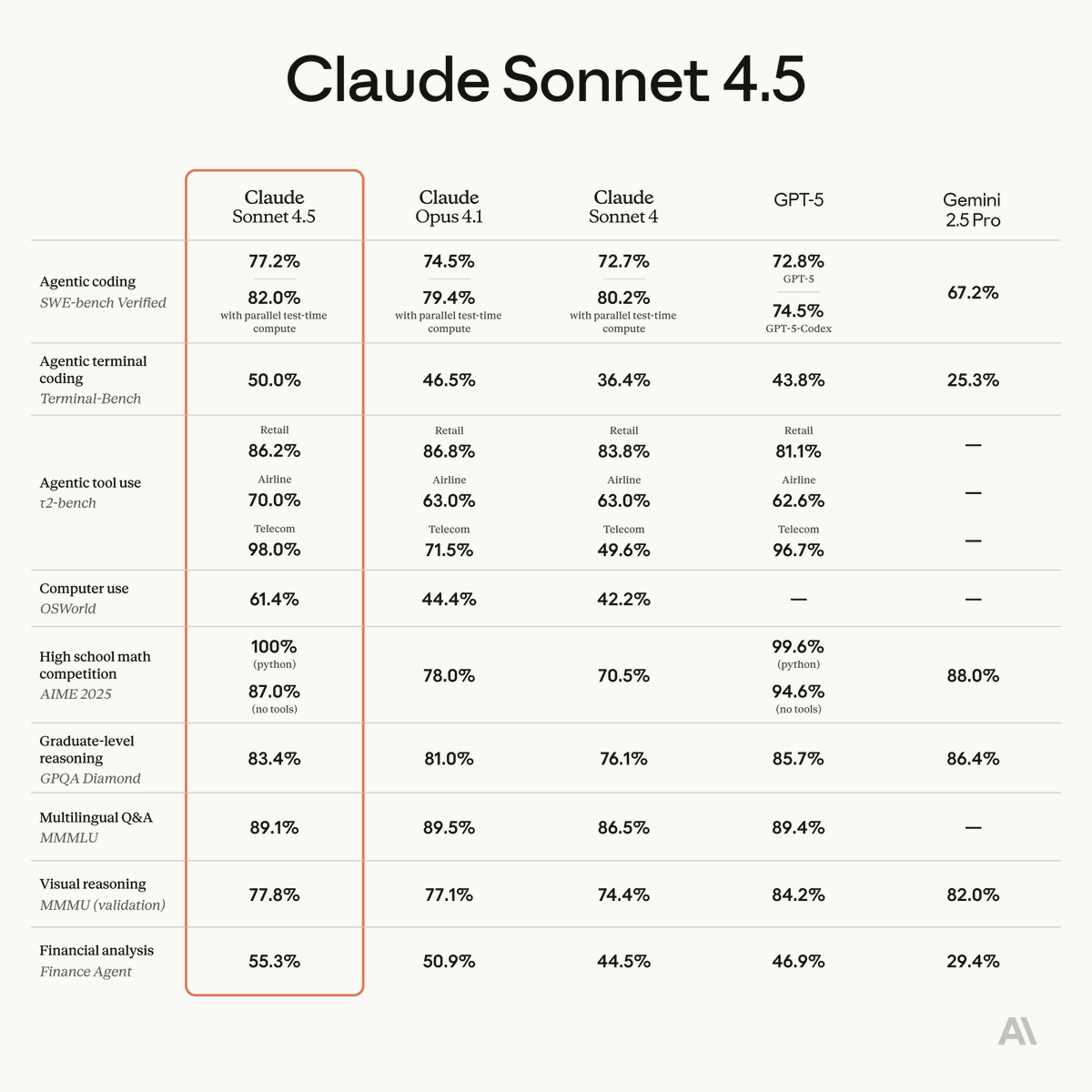
Introducing Claude Sonnet 4.5.
The best coding model in the world combined with the best character of any model I've seen.
141
217
2,859
223,556
lambda retweeted

5 Sep 2025
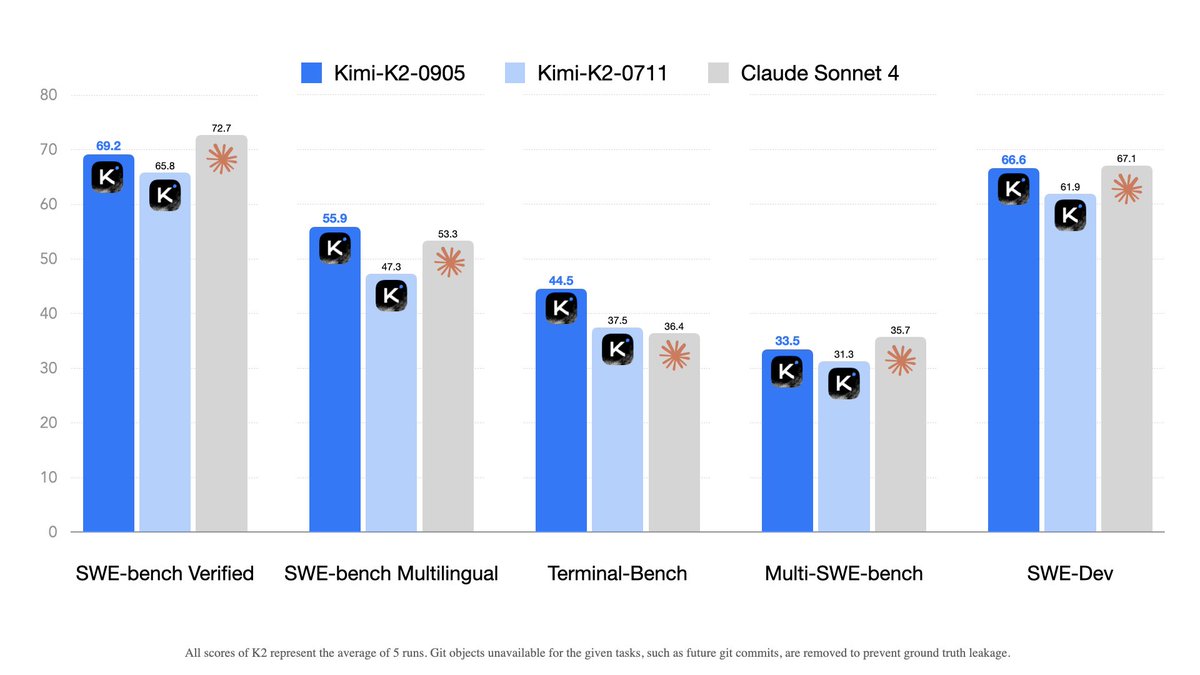
Kimi K2-0905 update 🚀
- Enhanced coding capabilities, esp. front-end & tool-calling
- Context length extended to 256k tokens
- Improved integration with various agent scaffolds (e.g., Claude Code, Roo Code, etc)
🔗 Weights & code: huggingface.co/moonshotai/Ki…
💬 Chat with new Kimi K2 on: kimi.com
⚡️ For 60–100 TPS guaranteed 100% tool-call accuracy, try our turbo API: platform.moonshot.ai
156
357
2,970
638,725
Good model, but sucks that they didnt realease any benchmark scores. even the system card was meh no real coding benchmarks
Introducing Grok Code Fast 1, a speedy and economical reasoning model that excels at agentic coding.
Now available for free on GitHub Copilot, Cursor, Cline, Kilo Code, Roo Code, opencode, and Windsurf.
x.ai/news/grok-code-fast-1
1
48
sorry for doubting you didnt know you were moving like this

58
this is about as good as qwen coder imo. but with qwen on cerebras hard to beat it
26 Aug 2025

Grok Code Fast 1 is now available for free in Windsurf for a limited time. Let us know what you think!

1
198
lambda retweeted

26 Aug 2025
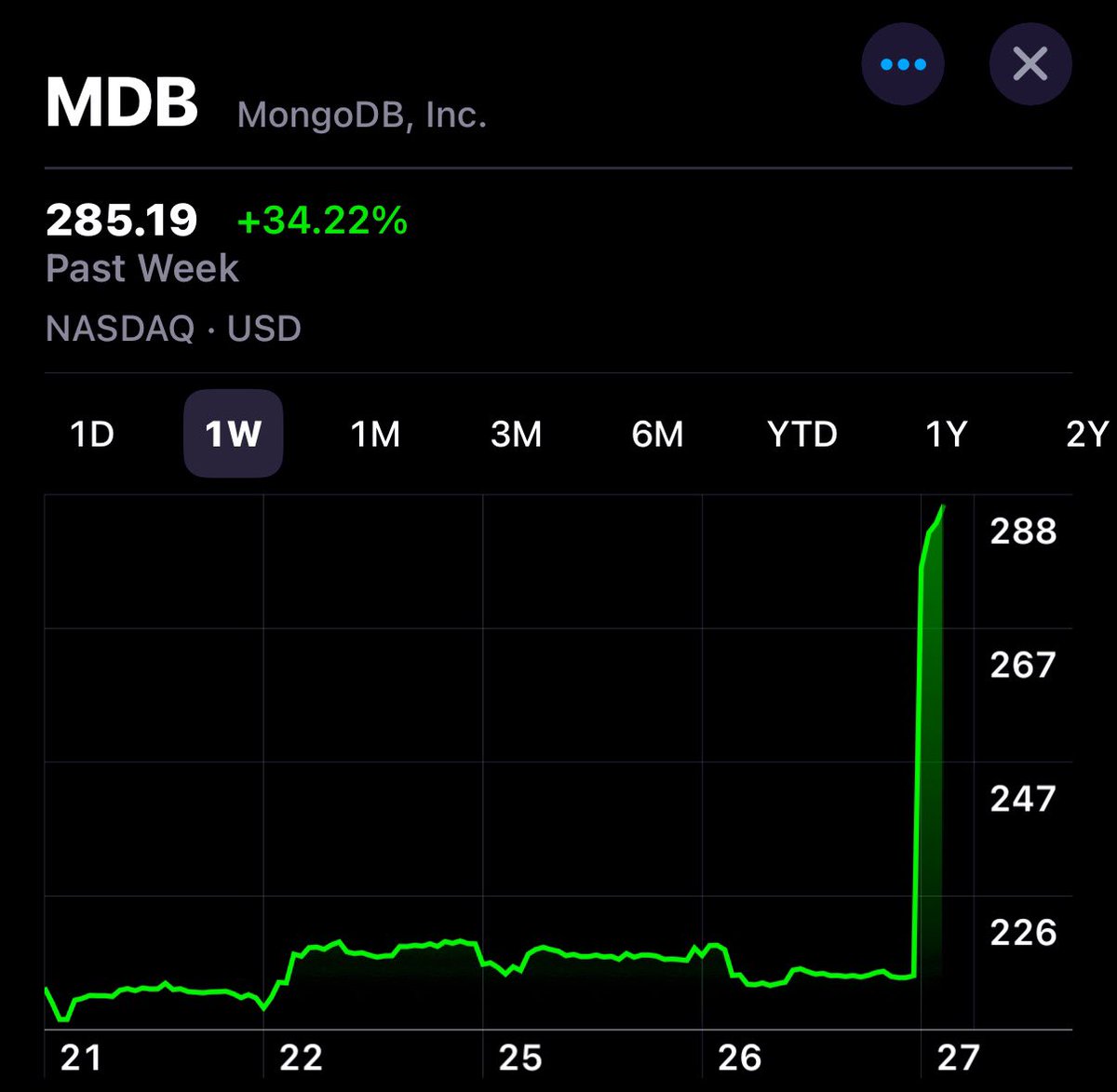
Introducing Gemini 2.5 Flash Image (aka nano-banana), our SOTA image generation and editing model 🍌
As you might have already seen, this model excels at character consistency, creative edits, and has Gemini's world knowledge!
305
541
4,932
716,000
fridge company mogging apple was not on my bucket list for 2025
31 Jul 2025

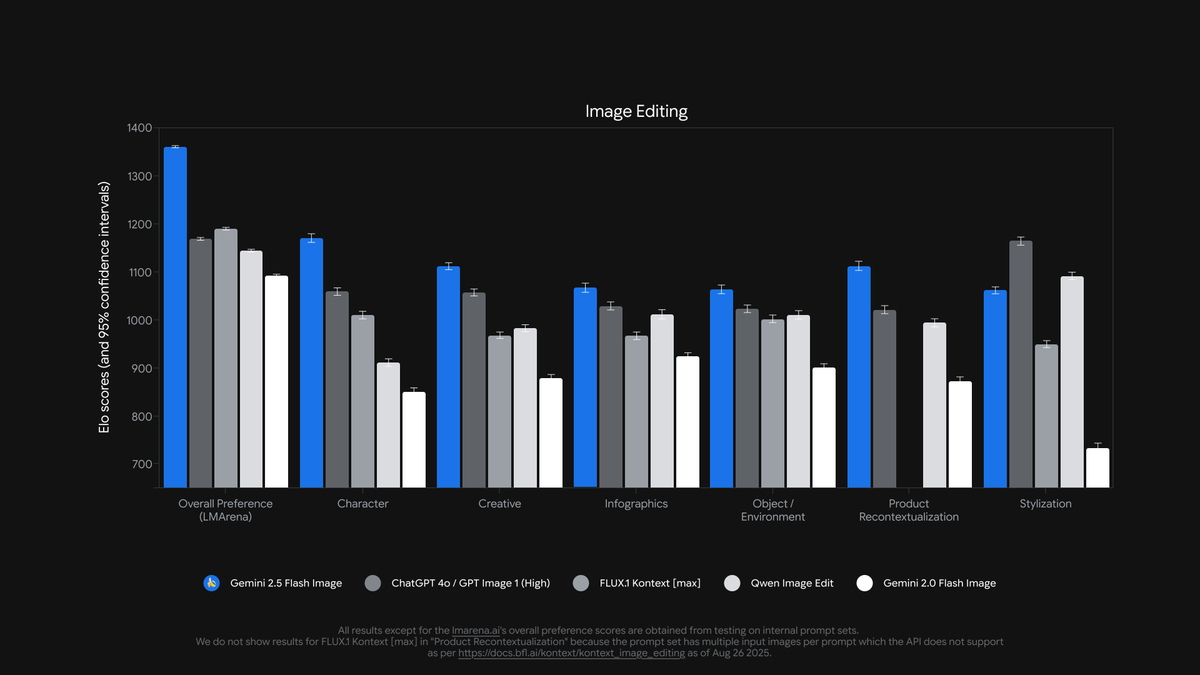
🇰🇷 LG recently launched EXAONE 4.0 32B - it scores 62 on Artificial Analysis Intelligence Index, the highest score for a 32B model yet
@LG_AI_Research's EXAONE 4.0 is released in two variants: the 32B hybrid reasoning model we’re reporting benchmarking results for here, and a smaller 1.2B model designed for on-device applications that we have not benchmarked yet.
Alongside Upstage's recent Solar Pro 2 release, it's exciting to see Korean AI labs join the US and China near the top of the intelligence charts.
Key results:
➤ 🧠 EXAONE 4.0 32B (Reasoning): In reasoning mode, EXAONE 4.0 scores 62 on the Artificial Analysis Intelligence Index. This matches Claude 4 Opus and the new Llama Nemotron Super 49B v1.5 from NVIDIA, and sits only 1 point behind Gemini 2.5 Flash
➤ ⚡ EXAONE 4.0 32B (Non-Reasoning): In non-reasoning mode, EXAONE 4.0 scores 51 on the Artificial Analysis Intelligence Index. It matches Llama 4 Maverick in intelligence despite having only ~1/4th total parameters (although has ~2x the active parameters)
➤ ⚙️ Output tokens and verbosity: In reasoning mode, EXAONE 4.0 used 100M output tokens for the Artificial Analysis Intelligence Index. This is higher than some other frontier models, but aligns with recent trends of reasoning models using more output tokens to 'think more' - similar to Llama Nemotron Super 49B v1.5, Grok 4, and Qwen3 235B 2507 Reasoning. In non-reasoning mode, EXAONE 4.0 used 15M tokens - high for a non-reasoner, but not as high as Kimi K2’s 30M.
Key details:
➤ Hybrid reasoning: The model offers optionality between 'reasoning' mode and 'non-reasoning' mode
➤ Availability: Hosted by @friendliai currently, and competitively priced (especially compared to proprietary options) by FriendliAI at $1 per 1M input and output tokens
➤ Open weights: EXAONE 4.0 is an open weights model available under the EXAONE AI Model License Agreement 1.2. The license limits commercial use.
➤ Multimodality: Text only input and output
➤ Context window: 131k tokens
➤ Parameters: 32B active and total parameters, available in 16bit and 8bit precision (means the model can be run on a single H100 chip in full precision)
3
66
lambda retweeted

20 Jul 2025
Luminal (luminalai.com) is creating PyTorch for Production – an ML compiler that generates blazingly fast CUDA kernels and makes deploying to production one line of code.
Congrats on the launch, @stake_jevens, @joefioti, and @matthewjgunton!
ycombinator.com/launches/O0g…
28
29
401
98,647
windsurf is so back
16 Jul 2025
Claude Sonnet 4 is back via first party support from @AnthropicAI!
Available at 2x credits (limited time discount) per request for Pro and Teams users. That’s 250 requests a month!

1
14
493
lambda retweeted

17 Jun 2025
The recording for this talk is now available!
tl;dr
- GPUs scale like bandwidth, quadratic w.r.t latency
- the key bandwidth they scale is math bandwidth (FLOP/s)
- among math bandwidths, low precision matmuls have scaled fastest
and some takeaways for data eng/data science


7
23
275
28,087

No more waitlist – Cerebras inference API is open to all!
1M free tokens/day
20x GPU speed
Reasoning in ~1 second
It's time to build!
inference.cerebras.ai/?utm_s…
52
64
648
108,463
lambda retweeted

2 Jun 2025
🚨 BREAKING: After a years-long battle, Taylor Swift has reclaimed ownership of her entire music catalog for a reported $360 million.
Here’s everything that happened:

54
55
1,806
399,352
lambda retweeted

20 May 2025
Today, for the first time, I genuinely want to leave the Apple ecosystem for Google's AI-powered Android. Having worked on Apple's OS for a decade, I know the entire stack intimately.
Google's innovation is happening at every level, from smaller to larger models, from cloud to TPUs, from app experiences to search. It's all finally coming to fruition, and the trajectory is clear: Google will be a dominant leader in mobile because of their tight AI integration. Their architecture positions them perfectly to maintain this leadership.
What makes this so powerful is the hardware-software integration. Companies without this end-to-end control will struggle to create the same seamless AI experiences across products. Just as OpenAI has leveraged my conversation history to make better decisions with newer models, Google already has access to my data through email. As I use their devices more, their AI will truly understand what I'm trying to accomplish.
Yes, privacy remains important, but there are tradeoffs. The conversation about sharing data with companies like Google deserves deeper exploration so we understand what this means for computing's future. When AI algorithms can process and truly understand massive datasets that humans simply cannot manage, we're witnessing what I believe is the biggest breakthrough in computing history.
Google's ability to implement this at scale while pivoting so quickly is, without question, a massive win. Their leap in AI intelligence is incredible, and it fundamentally transforms what's possible in personal computing.
I'm planning to share more of my experiences on my live streams as I explore this transition. I'll be getting an Android device soon so I can truly understand what this means in practice. As an engineer, I feel it's really important to actually use these products and share my genuine experience in real time, without the hype. I want to see firsthand how Google's AI integration changes the mobile experience and what it might mean for the future of computing.
114
84
1,401
168,965
lambda retweeted

7 May 2025
Introducing Mistral Medium 3: our new multimodal model offering SOTA performance at 8X lower cost.
- A new class of models that balances performance, cost, and deployability.
- High performance in coding and function-calling.
- Full enterprise capabilities, including hybrid or on-premises/in-VPC deployment, custom post-training, and seamless integration into enterprise tools and systems.
Check out our blog to learn more:

103
363
2,586
524,461
lambda retweeted

21 Apr 2025
openai launched gpt-4.5 to great excitement
yet under 2 months after launch, they announced it would be deprecated
is pre-training over now?
@jackgwhitaker and i show:
1. pre-training scaling laws haven't bent
2. why the marginal dollar left it for RL
3. why it'll come back

9
12
151
18,160
lambda retweeted

5 Apr 2025
Today is the start of a new era of natively multimodal AI innovation.
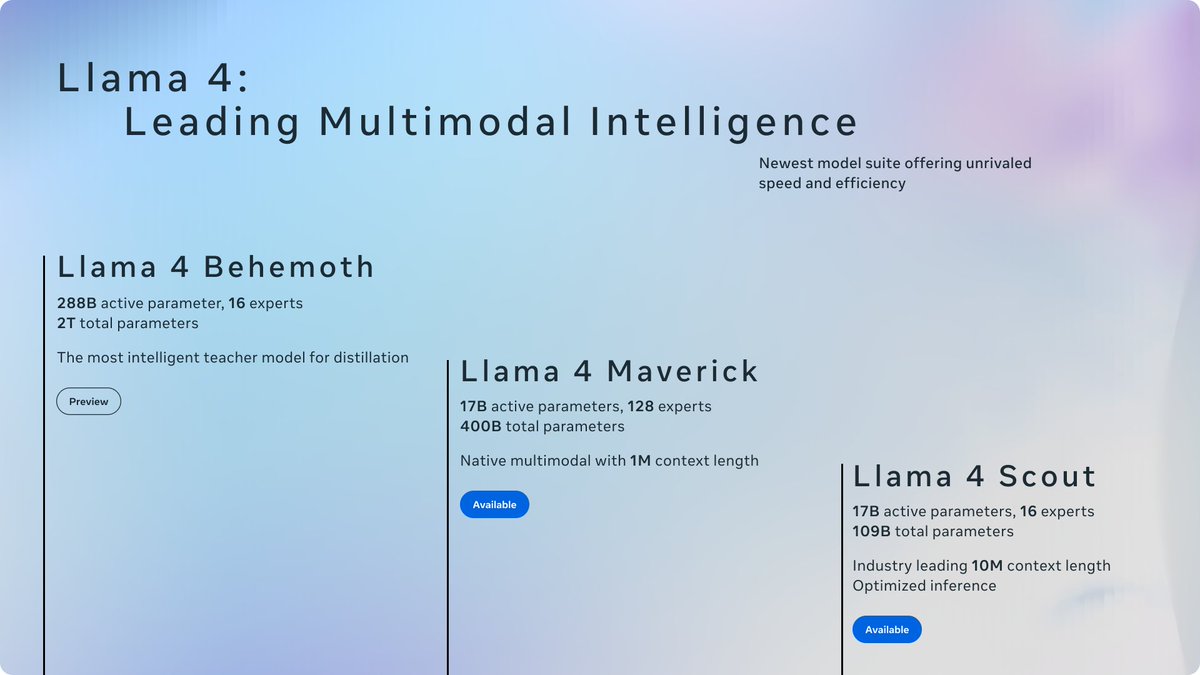
Today, we’re introducing the first Llama 4 models: Llama 4 Scout and Llama 4 Maverick — our most advanced models yet and the best in their class for multimodality.
Llama 4 Scout
• 17B-active-parameter model with 16 experts.
• Industry-leading context window of 10M tokens.
• Outperforms Gemma 3, Gemini 2.0 Flash-Lite and Mistral 3.1 across a broad range of widely accepted benchmarks.
Llama 4 Maverick
• 17B-active-parameter model with 128 experts.
• Best-in-class image grounding with the ability to align user prompts with relevant visual concepts and anchor model responses to regions in the image.
• Outperforms GPT-4o and Gemini 2.0 Flash across a broad range of widely accepted benchmarks.
• Achieves comparable results to DeepSeek v3 on reasoning and coding — at half the active parameters.
• Unparalleled performance-to-cost ratio with a chat version scoring ELO of 1417 on LMArena.
These models are our best yet thanks to distillation from Llama 4 Behemoth, our most powerful model yet. Llama 4 Behemoth is still in training and is currently seeing results that outperform GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on STEM-focused benchmarks. We’re excited to share more details about it even while it’s still in flight.
Read more about the first Llama 4 models, including training and benchmarks ➡️ go.fb.me/gmjohs
Download Llama 4 ➡️ go.fb.me/bwwhe9
822
2,367
12,747
3,662,022
lambda retweeted

5 Apr 2025
Introducing our first set of Llama 4 models!
We’ve been hard at work doing a complete re-design of the Llama series. I’m so excited to share it with the world today and mark another major milestone for the Llama herd as we release the *first* open source models in the Llama 4 collection 🦙. Here are some highlights:
📌 The Llama series have been re-designed to use state of the art mixture-of-experts (MoE) architecture and natively trained with multimodality. We’re dropping Llama 4 Scout & Llama 4 Maverick, and previewing Llama 4 Behemoth.
📌 Llama 4 Scout is highest performing small model with 17B activated parameters with 16 experts. It’s crazy fast, natively multimodal, and very smart. It achieves an industry leading 10M token context window and can also run on a single GPU!
📌 Llama 4 Maverick is the best multimodal model in its class, beating GPT-4o and Gemini 2.0 Flash across a broad range of widely reported benchmarks, while achieving comparable results to the new DeepSeek v3 on reasoning and coding – at less than half the active parameters. It offers a best-in-class performance to cost ratio with an experimental chat version scoring ELO of 1417 on LMArena. It can also run on a single host!
📌 Previewing Llama 4 Behemoth, our most powerful model yet and among the world’s smartest LLMs. Llama 4 Behemoth outperforms GPT4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on several STEM benchmarks. Llama 4 Behemoth is still training, and we’re excited to share more details about it even while it’s still in flight.
A big thanks to all of our launch partners (full list in blog) for helping us bring Llama 4 to developers everywhere including @huggingface, @togethercompute, @SnowflakeDB, @ollama, @databricks and many others👏 This is just the start, we have more models coming and the team is really cooking – look out for Llama 4 Reasoning 😉
A few weeks ago, we celebrated Llama being downloaded over 1 billion times. Llama 4 demonstrates our long-term commitment to open source AI, the entire open source AI community, and our unwavering belief that open systems will produce the best small, mid-size and soon frontier models. Llama would be nothing without the global open source AI community & we are so ready to begin this next chapter with you. 🦙
Read more about the release here: llama.com/, and try it in our products today.

315
882
5,615
1,138,555