
RL @ Cursor
Joined January 2014
- Tweets 369
- Following 499
- Followers 1,347
- Likes 1,605
30 Photos and videos










May 26
currrrrsor biig!
May 26

Today's Training Data episode takes us BTS on the infrastructure challenges required to do large RL runs at scale, featuring @ellev3n11 (Composer Lead at @cursor_ai) and @dzhulgakov (Co-Founder at @FireworksAI_HQ).
The Cursor team trained Composer 2 on Fireworks by starting with a strong base model (Kimi 2.5) and performing large-scale mid-training on code tokens and web data to learn common patterns and libraries, followed by a large-scale Reinforcement Learning run to learn how to navigate the Cursor harness, call tools, and write correct code.
Today's episode dives into the systems and infrastructure challenges of making that large RL run happening, and there were many (!!), from numerical mismatch to global distribution to synchronizing rollouts across asynchronous pipelines to keeping track of expert activation across runs and more.
Extremely nerdy in-the-weeds challenges that Federico and Dima were delighted to nerd out on together :)
Beyond RL infra, we also discussed Online vs Simulated rollouts, self-summarization for long-horizon agents, environment design ("the most powerful RL environment is the product itself"), and other technical nuggets.
PS: We filmed this episode before the SpaceX news, while the Cursor team was still compute-constrained. While Cursor now has *all* the flops, the takeaways and hurdles crossed ring true for any serious application-level company that is racing to post-train their own models.
I believe that more serious application companies will go the way of Cursor and post-train their own models.
00:00 Introduction
00:53 Why Cursor Trained Composer 2
04:55 Specialization vs Bitter Lesson
06:16 Composer 2 Training Recipe
16:32 Scaling RL Infrastructure Globally
23:32 Floating Point Drift
25:11 MoE Sensitivity Explained
26:25 Router Replay Fix
27:19 Real Time RL Loop
31:49 Long Horizon Agents
34:29 Why RL Everywhere
37:34 LLM as Judge Rewards
39:14 RL in Hard Domains
40:13 Build Your Own Environments
44:34 Closing Thoughts
72
20,853
May 18
RL goes brrr 🎶
May 18

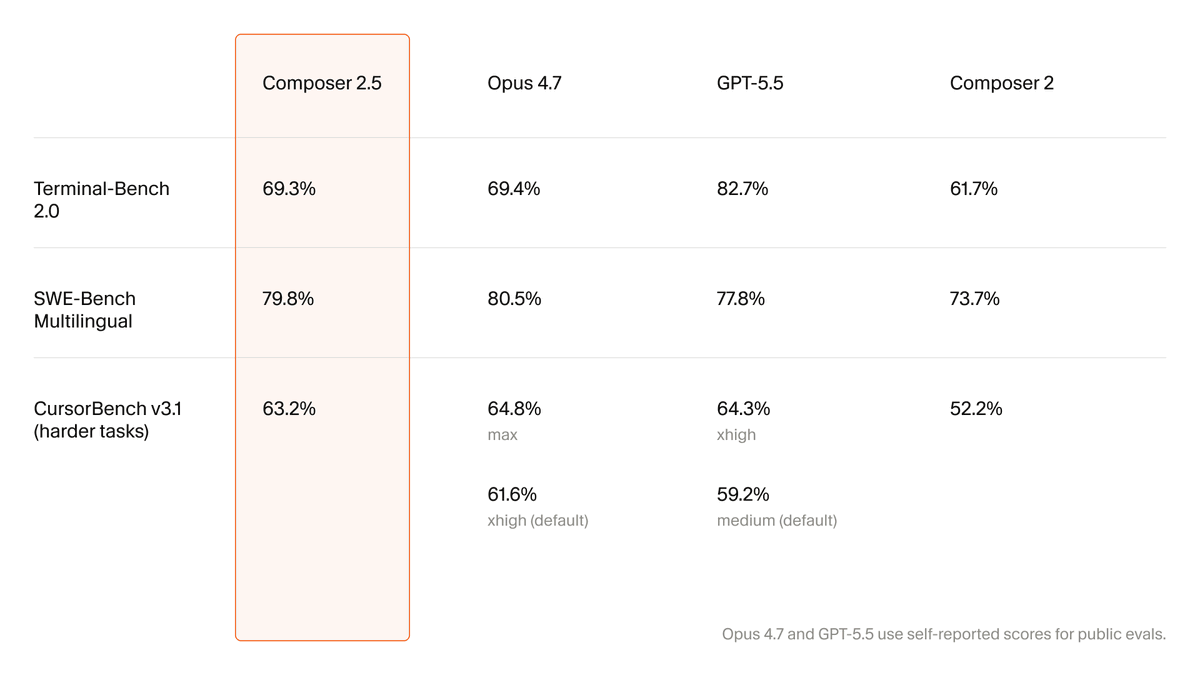
Introducing Composer 2.5, our most powerful model yet.
It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions.
For the next week, we’re doubling the included usage of the model.
2
1
26
1,269
Oleg Rybkin retweeted

Mar 24
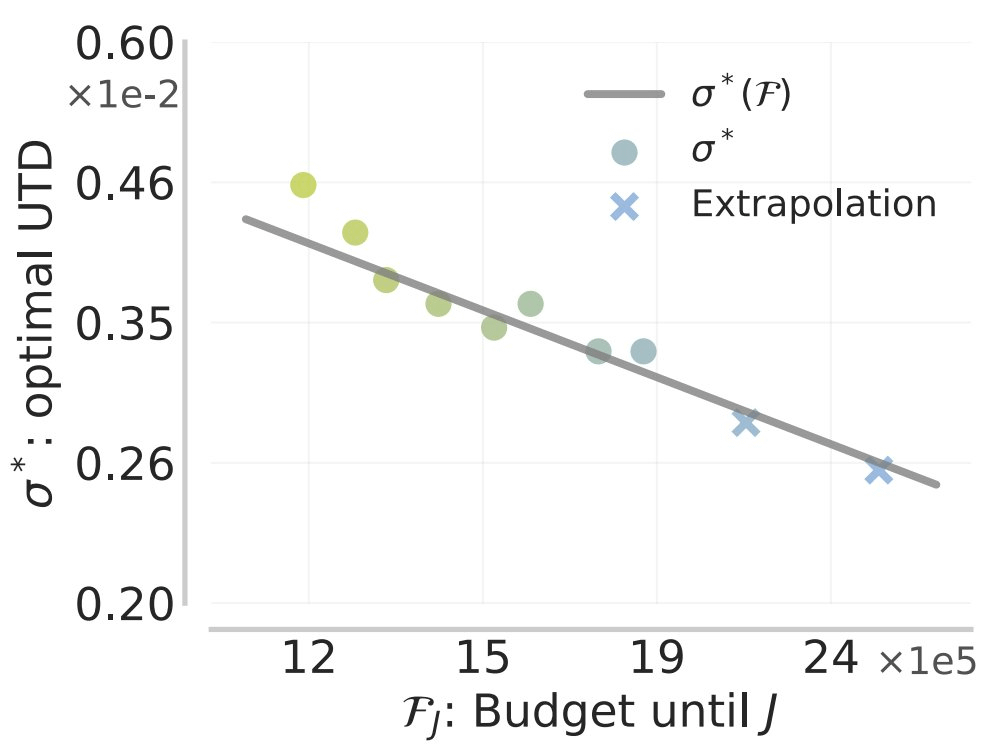
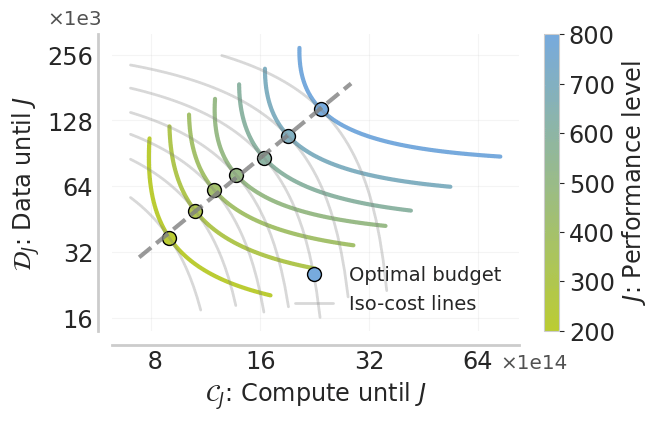
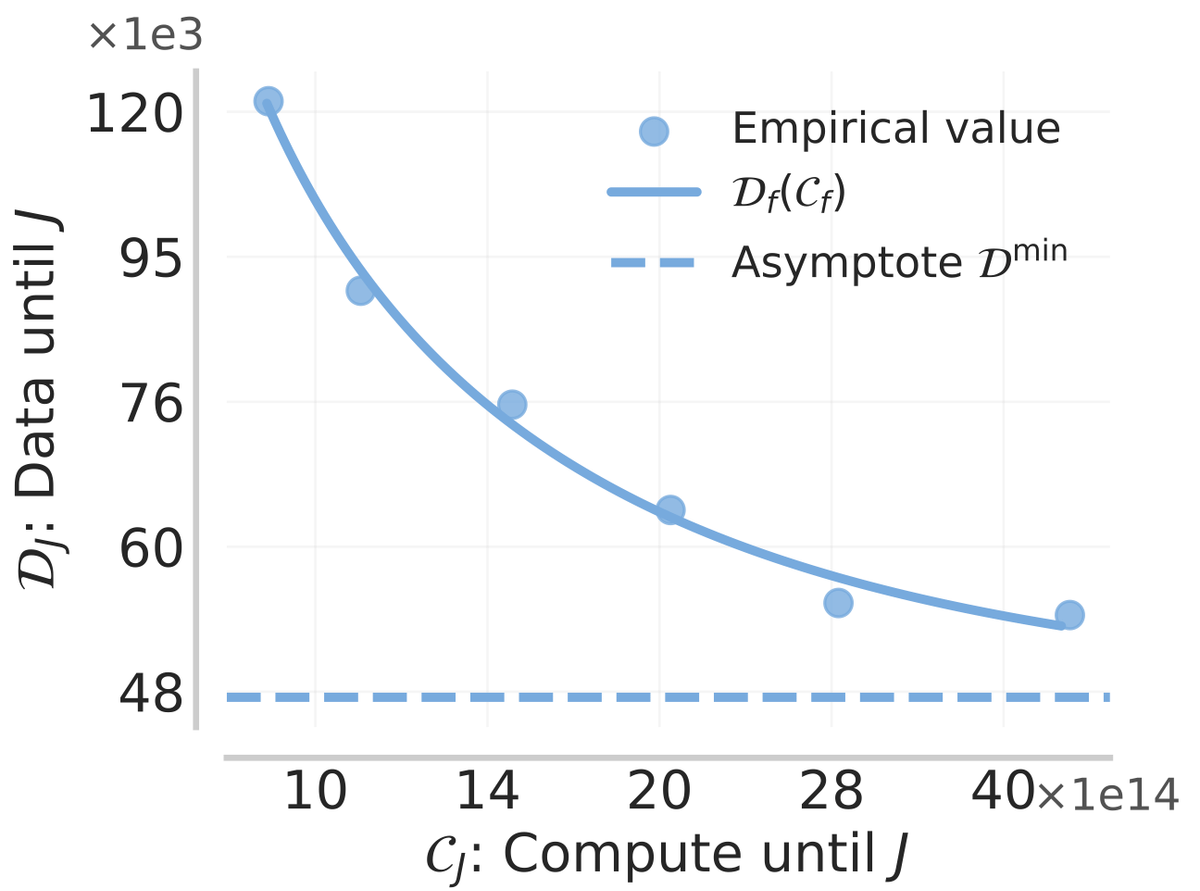
We're releasing a technical report describing how Composer 2 was trained.

169
478
5,063
1,263,211
Oleg Rybkin retweeted

Mar 20
Cursor is at a very chinese time in their life
13
12
391
42,547
Mar 20
The hardest challenge is to be yourself in a world where everyone is trying to make you be somebody else
- E E Cummings


8
1,046
Mar 20
Efficient RL training achieved internally 👀
41
2,848
Oleg Rybkin retweeted

Mar 19
Composer 2 marks the one-year anniversary of our large model training efforts. Since then, we've built an exceptionally talent-dense team of ~40 people with some of the best researchers and engineers from the labs, academia, industry, and more heterogeneous backgrounds.
And we are exclusively focused on coding. We don't care about models that can respond to emails, do your tax returns, or be your friend.
Every FLOP, token, parameter, and researcher is entirely dedicated to software engineering.
77
51
1,020
132,665
Oleg Rybkin retweeted

Mar 19
Very excited for the world to try this model! People like it a lot internally at Cursor - feels frontier-level smart and extremely fast
6
5
101
6,326
Oleg Rybkin retweeted

Mar 19
a lot went into this model. it was fun! i hope people enjoy it.
24
11
244
21,229
Oleg Rybkin retweeted
Mar 19
Composer 2 is now available in Cursor.
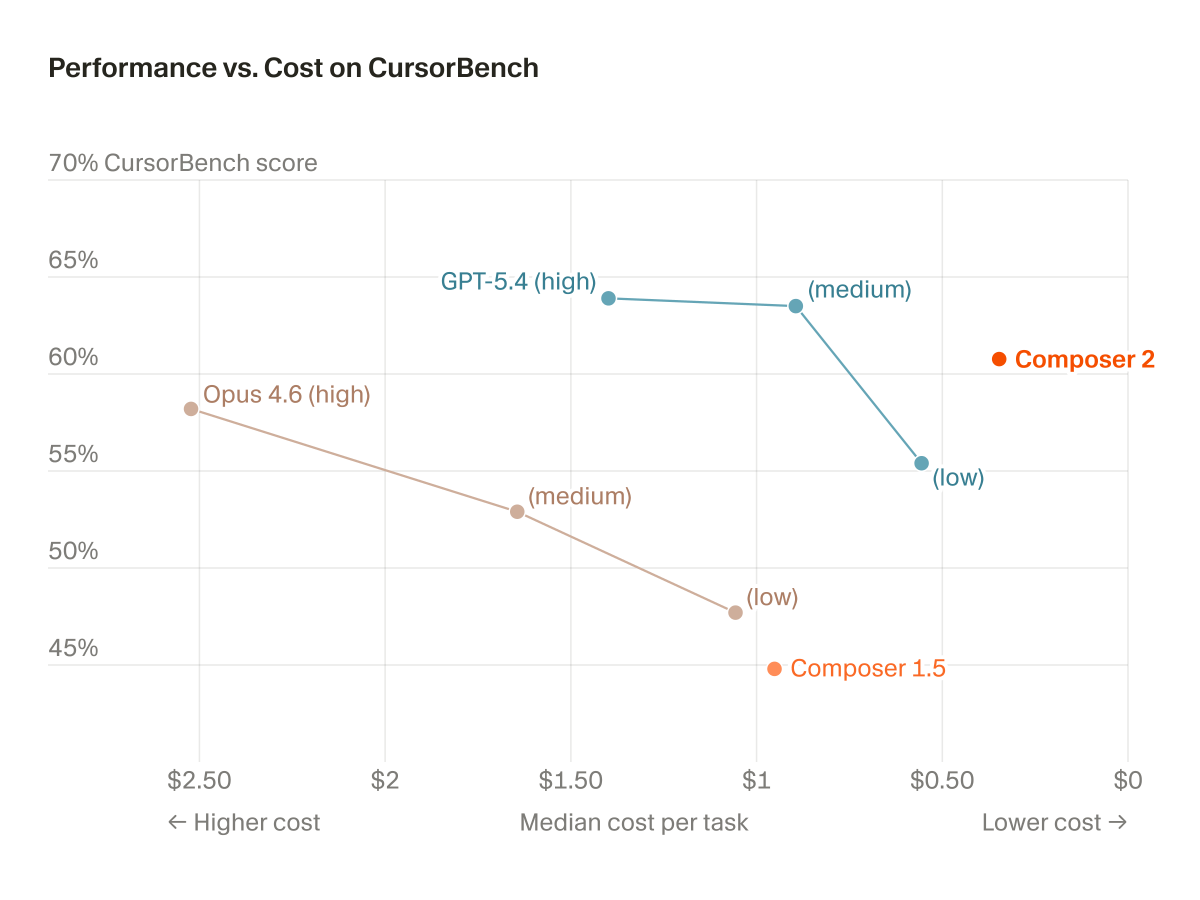
646
878
9,753
5,388,246
Oleg Rybkin retweeted

Jan 20
I am thrilled to introduce humans& alongside my good friends and co-founders @ericzelikman & @noahdgoodman & @gharik & @YuchenHe07.

Jan 20

Today we introduce humans&, a human-centric frontier AI lab. We believe AI can be reimagined, centering around people and their relationships with each other. At its best, AI should serve as a deeper connective tissue that strengthens organizations and communities

ALT a photograph taken of dolores park with the "humans&" logo overlaid, then transformed to look like a painting
70
46
1,038
781,068

Oleg Rybkin retweeted

19 Dec 2025
There is significant discussion in the academic literature about RL making models better at pass@1 and *worse* at pass@N (or related claims).
We run a lot of RL runs at Cursor and don't see this issue systematically. Not doubting it occurs, but something else might be going on.
29
30
481
129,328
6 Dec 2025
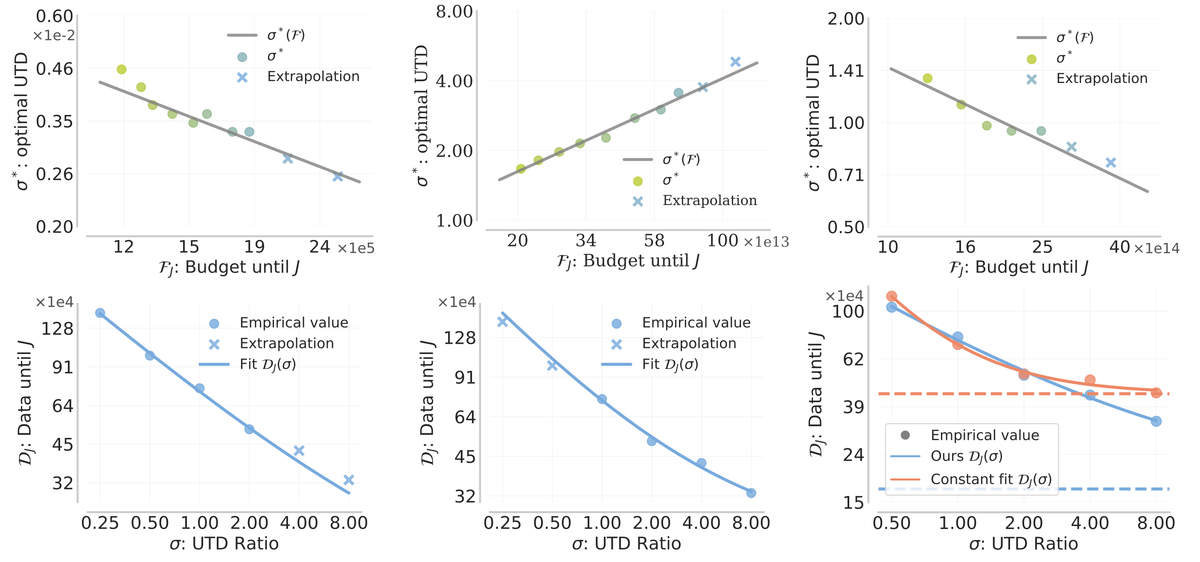
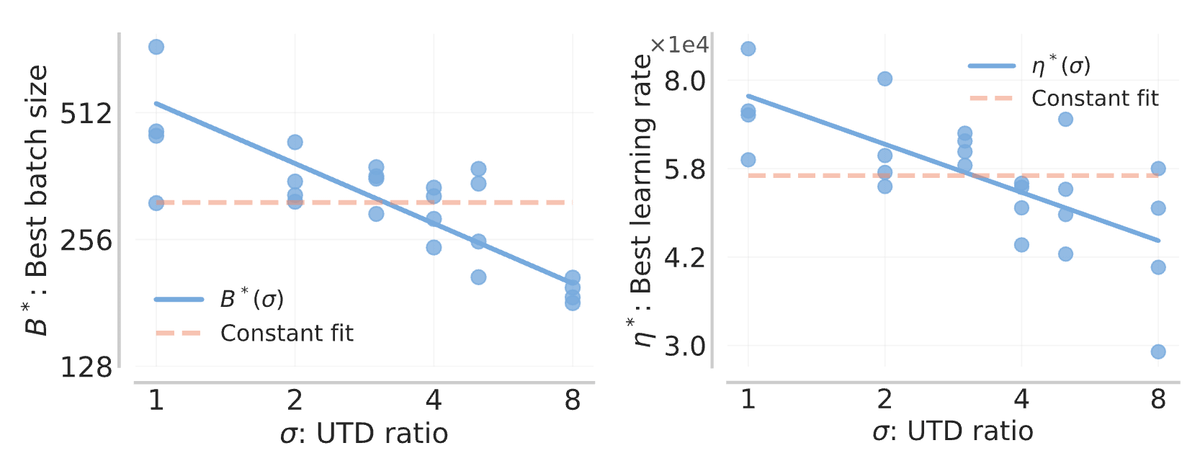
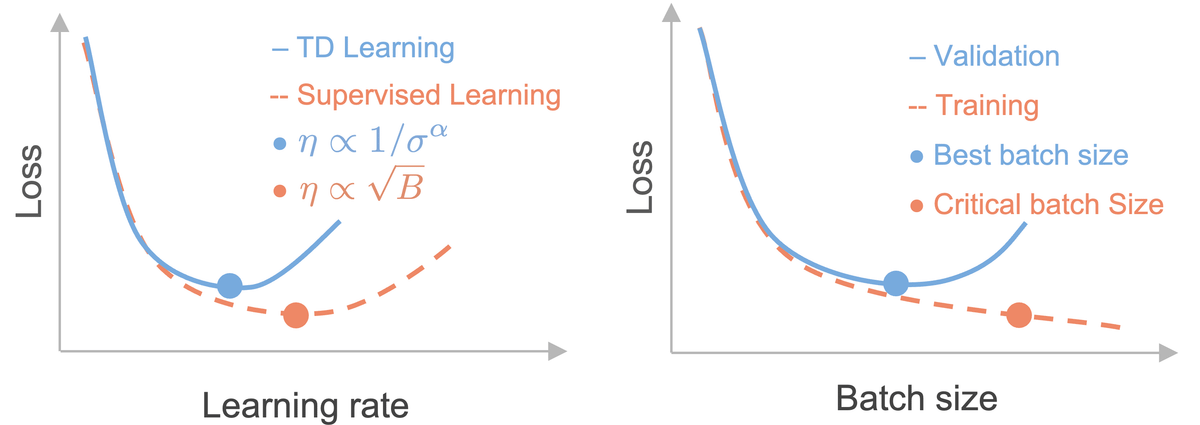
NeurIPS is in the home stretch! If there is one more thing you have energy for, come learn about how to scale them optimally at poster 216 :)
2 Dec 2025

We are at NeurIPS and excited about compute-optimal RL with value functions! Come stop by our poster on Friday :)
9
1,382
3 Dec 2025
Check out Ed's new paper, presented at NeurIPS on Thursday!
Robot policies are great when they can see what to do, but what if the target object is hidden? We use RL by training value functions with privileged sensors and learn effective active perception policies, see below!
2 Dec 2025

Happy to announce our neurips’25 paper, real world RL of active perception behaviors!
I am pretty excited about this project - I learned that real world robot RL is actually quite straightforward. Details below:
1
8
1,227
2 Dec 2025
We are at NeurIPS and excited about compute-optimal RL with value functions! Come stop by our poster on Friday :)
2 Dec 2025

I'll be at Neurips this week! On Friday afternoon (4:30-7:30), we're presenting our work on training value functions compute-optimally.
value-scaling.github.io/
With @_oleh @zhiyuan_zhou_ @mic_nau @pabbeel @svlevine @aviral_kumar2
1
23
3,759
Oleg Rybkin retweeted

2 Dec 2025
Happy to announce our neurips’25 paper, real world RL of active perception behaviors!
I am pretty excited about this project - I learned that real world robot RL is actually quite straightforward. Details below:
4
25
207
24,610
30 Nov 2025
Will be in San Diego for NeurIPS starting tomorrow! Excited to catch up with everyone :)
2
2
42
4,842
Oleg Rybkin retweeted

25 Nov 2025
What happened to adding error bars to evals?

24 Nov 2025

Claude Opus 4.5's score on SWE-bench is wild.
I like how Anthropic has focused on coding from the beginning.
They haven’t released any image or video models. All in the most economically valuable area. Good strategy.

17
31
898
117,012
Oleg Rybkin retweeted

24 Nov 2025
Multi-task RL can be highly sample-efficient and when done right, it unlocks LLM-style transfer and fine-tuning.
We’re excited to introduce BRC, a simple recipe for multi-task RL that outperforms SOTA single-task agents while using less compute (!)
4
32
117
29,108