
building AI that wont embarrass me in front of my own standards
Joined December 2023
- Tweets 7,381
- Following 690
- Followers 27,753
- Likes 33,921
988 Photos and videos












NEW: Anthropic claims the capability cited by the U.S. in restricting Fable 5 is already widely available from other models, including OpenAI’s GPT-5.5.
5
5
123
5,586
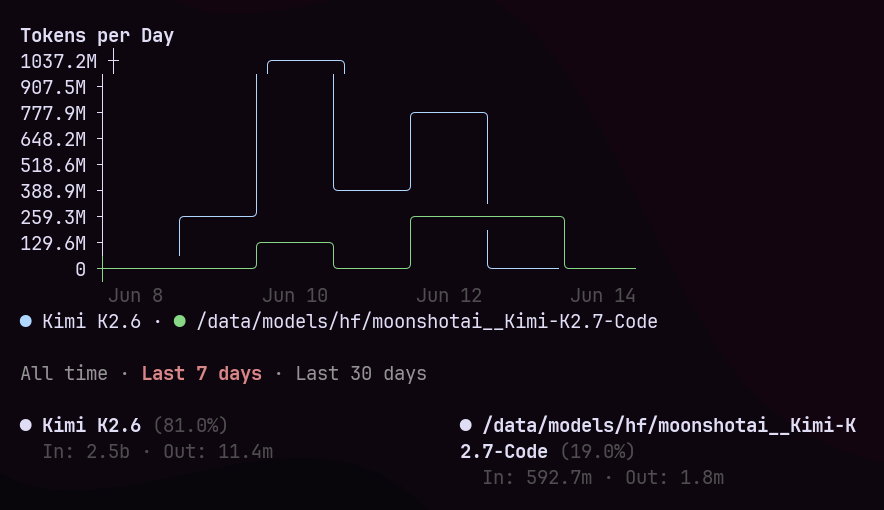
2.7-Code in claude code with my custom inference harness works surprisingly well. im comparing it to my k2.6 which was fine tuned for this harness as well as my recent runs of fable (at least the ones that succeeded) and it stacks up favorably. where k2.6 felt very much like opus, k2.7 is kind of its own thing (for better and for worse) . its more terse, more argumentative and overall 'smarter' (at least for the use cases i've tried it on already) . Moonshot did a very very good job with the post training on this, i am very impressed with their work. While k2.7 would certainly benefit from a FT run specifically on my claude code harness and my new scm system (called ncode), i am going to continue to use it as is for a while instead of falling back to the k2.6 ft (which is about the highest endorsement i can give) .

13
9
223
17,791
heard that anthropic eased up the classifiers, so i thought i'd try fable again on a very simple web app. after spending $200 on a single request (please do a code quality review of this app) it was classified as unsafe and failed
i think i am officially done trying here
15
10
356
27,965
i underestimated
Jun 10

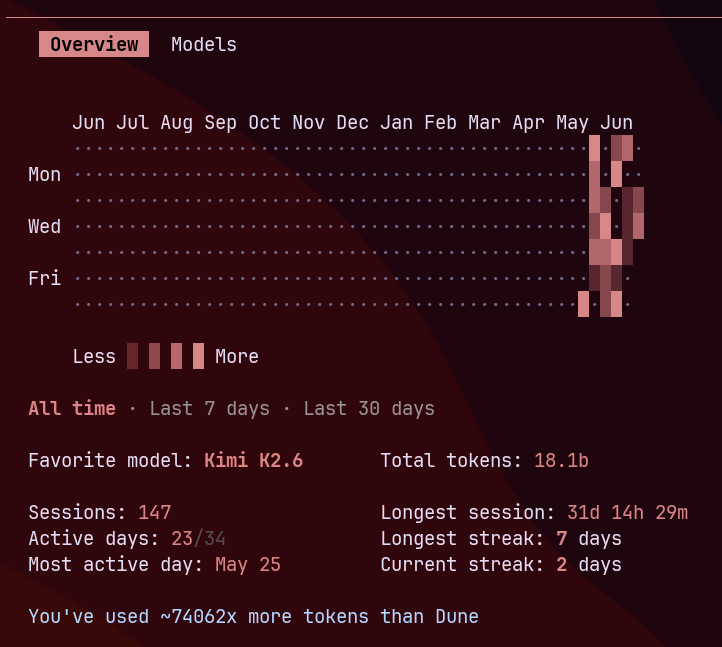
i am curious how many tokens u use a month, has to be like, a billion at least
18
2
380
36,520
towards the middle of last year, it was clear there were 2 key risks for my ongoing research and development the way i was going. one was the reliance on claude code and anthropic, so i spent a large amount of time burning down those risks by moving completely towards codex (thankfully right around the time gpt5 was released) and towards claude code an internally served and finetuned k2.6 (the other key risk was git and github)
fable 5 seems like a massive improvement over the latest Opus models (which, IMHO werent that impressive and i was able to complete replace with our k2.6) but, even without the intentional nerfing, is not a significant enough improvement (in many was a regression) over my current flow. for most things i do, my only real goal is to use the best model available for the given task and the given time but at this point there would need to be a GPT4 or o1 level disparity in capabilities for me to rely on anthropic for my work again.
13
12
433
61,670
i haven't used any Anthropic models since Jan / Feb so i was excited to unleash fable on a bunch of benchmarks and a few of my most complicated repos. so far, it seems like a huge improvement over opus, especially for claude code expert use cases but still not on par with gpt 5.5 xhigh for my specific use cases. in fact, its pretty on par with my fine tuned k2.6 outside of the new claude code features . the areas where it seems to excel are large multi part reviews (it caught a handful of really subtle and complex bugs) and multi-step long running tasks. i kept it away from my research / training and infra code for obvious reasons, so this is 'normal' software dev specific .
overall, solid effort and a huge improvement over the most recent opus, but not pushing the frontier in any meaningful ways (at least that i can see so far). i will probably use it for the rest of the day just to be sure and then move back to 80% k2.6 and 20% gpt 5.5 xhigh
29
23
619
66,450
using gpt 5.5 xhigh on fast mode ended up costing me about 200x more per day than gpt 5.4 xhigh . i switched back but i am forcing myself to use our k2.6 ft at least 50% of the time and only escalating to 5.4 when i need to and finally only to 5.5 as an escalation now
20
3
193
17,459
I removed dsv4 pro from my daily rotation. When it's good, it is still very good but the rate of hallucinations and poor instruction following in a wide range of scenarios make it unusable in practice at this time. With more post training I think it will be an excellent model
8
3
196
12,993
not only is this awesome to see, but i believe this quantization performance will pretty directly correlate to its ability to be finetuned in the future. dsv4 pro is the headline for me but the flash performance should not be discounted (it is exceptional)

This is DeepSeek v4 Flash quantized at 2 bit that runs as LLM of the pi agent. Perfect tool calling apparently, so this model, with this specific quantization scheme that I used at least, is capable of working very well. Now I need a real speedup not in t/s generation but prompt processing.
2
103
8,890
i completely agree but sometimes 'benchmarks' are hard to quantify. while we still have lots of our own internal benchmarks and evals, what i've moved towards are a specific set of representative tasks and problems that are either currently problematic for the sota models and / or things we do all the time that are core to our version of success. while the distinction might not be particularly interesting at first glance, to me the difference is 'how we do you do on a synthetic approximation of what we value" vs "how well do you actually work in our system with our exact problem compared to the best way(s) we know how to do things today"
Apr 27

Every company building on top of AI should be making their own benchmarks.
This is the way if you want model progress to disproportionally benefit your company.
2
82
6,726
I think software development is currently as hard as its ever been. What has changed with the introduction of AI is:
- software development has become available / accessible to more people than ever
- velocity has increased enormously (with an on average corresponding decrease in quality)
- most products and ideas are no longer constrained by the productivity of a single dev or a small team
- existing tools and infrastructure that are still designed primarily for human developers and human interaction are being stressed to the breaking point as a result
in many ways this reminds me of when coding bootcamps first became popular. there was a tremendous influx of new rails devs and then new js/node/react devs to the industry and corperate insurance and retail companies all of a sudden had 'tech teams' . lines of code and the number of projects/products increased both in volume and in ambition and there was a corresponding increase in outages and bugs and slop. it took some tima and some pain but the software industry eventually caught up and problematic trends died out and best practices and hard-fought experience emerged and in many ways the software industry emerged better for it.
i think there will be a similar (albeit more violent and dramatic) cycle for ai software development in the next 5 - 10 years and while it will look very different at the end of that cycle, in many ways the software industry will most likely end up better for it in the end
22
25
379
25,553
i was finally able to get deepseekv4 (flash and pro) integrated into my system. similar to deepseekv3, it took a lot of work and a lot of trial and error to figure out how to make it work correctly (or at least to an acceptable level).
when prompted and formatted correctly, it can be exceptional in agentic harnesses but on occasion its still naive (like a much better gemini in this regard). its long context seems nearly lossless up to 400k (the max i really trust my evals at) but still seem a bit lossy at the 1m mark (i would put it on par with opus 1m on similar prompts and tasks tho)
where k2.5/6 and glm feel very similar to opus in many ways, dsv4 does not which is going to take time to figure out the best way to interact with it. the undocumented tokens in the tokenizer point at a lot of potentially interesting ideas and use cases worth exploring.
right now my token usage is pretty evenly split between gpt 5.4 xhigh (and now 5.5) and k2.6 . im still not sure if dsv4 pro max going to supplant or augment my k2.6 usage but what i will say is i plan to keep using it because its a very good model (at least as good as k2.6) and when its good, it is potentially my favorite model (even replacing 5.4xhigh in some places) .
13
14
250
19,030