
Love 3d printing, playing with local llms and learning Claude Code
Joined December 2017
- Tweets 323
- Following 182
- Followers 1,482
- Likes 681
39 Photos and videos











Pinned Tweet

May 17
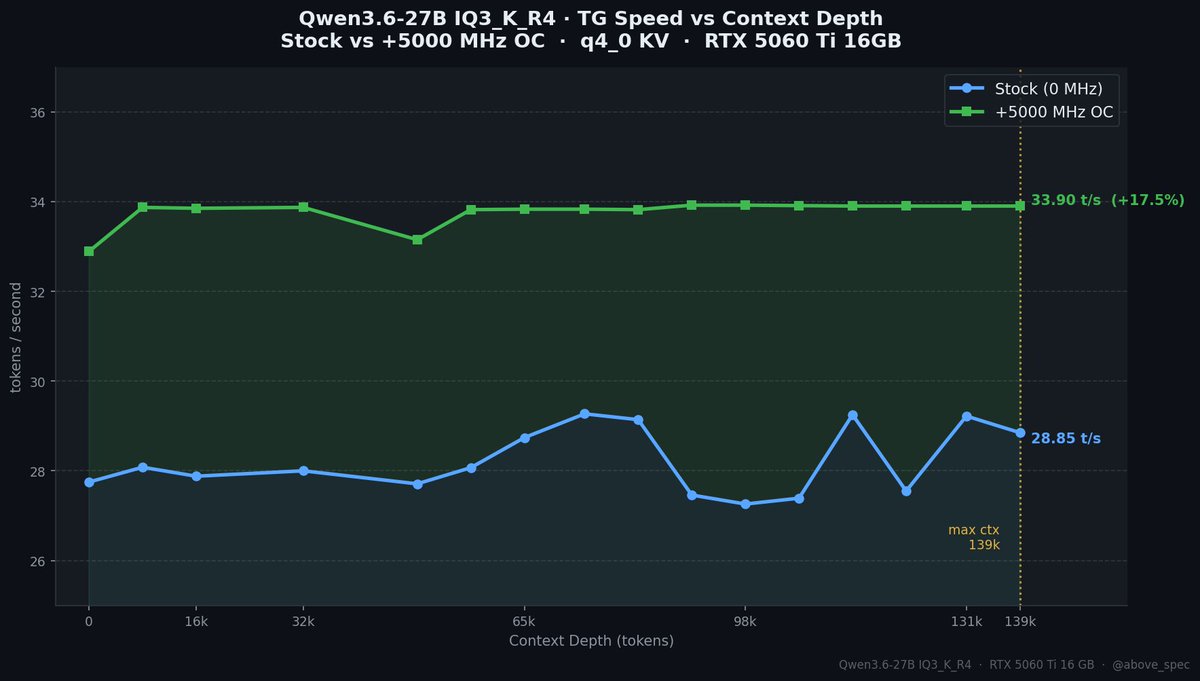
Qwen3.6-27B-MTP at ~61 tok/s. 100k context.
On two *used* RTX 3080 Tis — not the RTX 3090 everyone benchmarks (24GB, but split across 2 cards on PCIe 3.0 x8/x8, no NVLink).
Running llama.cpp's new MTP speculative decoding. The deep-context bottleneck? Nobody's talking about it. 🧵
19
14
214
18,363
May 17
Qwen3.6-27B-MTP at ~61 tok/s. 100k context.
On two *used* RTX 3080 Tis — not the RTX 3090 everyone benchmarks (24GB, but split across 2 cards on PCIe 3.0 x8/x8, no NVLink).
Running llama.cpp's new MTP speculative decoding. The deep-context bottleneck? Nobody's talking about it. 🧵
19
14
214
18,363
May 17
Final recommended llama.cpp config
```bash
./llama-server \
-m Qwen3.6-27B-Q4_K_M.gguf \
-ngl 99 --split-mode layer --tensor-split 58,42 \
-c 102400 \
-fa on -ctk q4_0 -ctv q4_0 \
--spec-type draft-mtp --spec-draft-n-max 3 --spec-draft-p-min 0.75 \
-ub 256 \
-np 1 --jinja -t 8 \
--host 127.0.0.1 --port 8080
```
The flags that carry the findings:
- `-ub 256` — *the* result (5–6): halves the per-prefill compute-graph reserve (~1.8GB), frees ~1.4GB on the choking card. This, not KV-quant, unlocks deep ctx.
- `--tensor-split 58,42` — weight off GPU1 because MTP pins the draft head growing draft-KV there (7); whole-layer quantized, ~170MiB/step.
- `-ctk/-ctv q4_0` — sane default, but *not* the deep-ctx fix (5).
- `--spec-type draft-mtp --spec-draft-n-max 3` — native MTP, no separate draft model (2).
- `-c 102400` — 100k, the honest ceiling (8); config D ran 0→94k clean. (Config E's `-c 153600` / `-ts 54,46` was only to trace the throughput curve, not for serving.)
# Power cap is NOT a llama.cpp flag — set it first (250W = efficiency knee, ~96% perf / −17% power):
sudo nvidia-smi -pl 250 # both cards
1
14
1,430
May 17
Power scaling — the surprise. Same config, only the cap changed:
- **250W = ~96% of 300W throughput, for 17% less power.** Basically free.
- 200W is where it falls off a cliff: −15% (short ctx) → −23% (98k)
- accept rate fully power-independent (deterministic)
~250W is the efficiency sweet spot on these cards.
Takeaway: 2×3080 Ti is a legit 24GB-class box for 27B MTP if you (1) tune `-ub`, not KV-quant, for deep context, (2) accept ~100k as the honest ctx ceiling, (3) cap at **~250W** — the efficiency knee: ~96% of 300W throughput for 17% less power.
3
1,075
May 17
The VRAM mystery: deep context kept OOMing ~94–114k — but *only on GPU1*. Obvious suspect: KV cache. So we quantized the MTP draft KV f16→q8_0. Result: bit-identical accept rates, 58MiB freed. Zero help. KV was never the problem.
Real culprit: the compute-graph reserve — a ~1.8GB scratch buffer sized to the *physical batch* (`-ub`, default 512), allocated per prefill. Halving it (`-ub 256`) freed ~1.4GB on the choking card and unlocked deep context. The wall was batch-sizing, not KV.
Why GPU1 specifically? Self-speculative MTP puts the draft head its (ctx-growing) draft KV entirely on one card — there's no `--spec-tensor-split`. At depth it re-saturates that card no matter how you tune `-ts`. Structural to split-VRAM MTP. Found this documented nowhere.
8
1,206
May 17
Throughput (Q4_K_M, q4_0 KV, MTP n=3, 300W cap, 24GB split 2 ways):
- short ctx: ~61 tok/s
- 32k: ~47 tok/s
- 65k: ~41 tok/s
- ~98k: ~36 tok/s
MTP accept rate 0.59–0.72 depending on depth. Consumer cards, no NVLink.
7
1,407
May 17
The rig: 2× RTX 3080 Ti (12GB ea, 24GB total), i7-7700K, Z270, PCIe 3.0 x8/x8, no NVLink → layer-split, not tensor-parallel. Q4_K_M (~17GB), q4_0 KV, MTP n=3. Both cards power-capped at 300W (from 400W stock) — deliberate for thermals/efficiency, ~5% cost, and it sets up a power-scaling test later. All numbers below @300W.
6
1,747
May 17
Why this is new: llama.cpp just gained native **MTP speculative decoding** (`--spec-type draft-mtp`), and unsloth shipped `Qwen3.6-27B-MTP-GGUF` with the MTP head intact. MTP = the model drafts its *own* tokens — no separate draft model. Almost zero real benchmarks for this exist yet, let alone on split-VRAM consumer rigs.
12
2,031

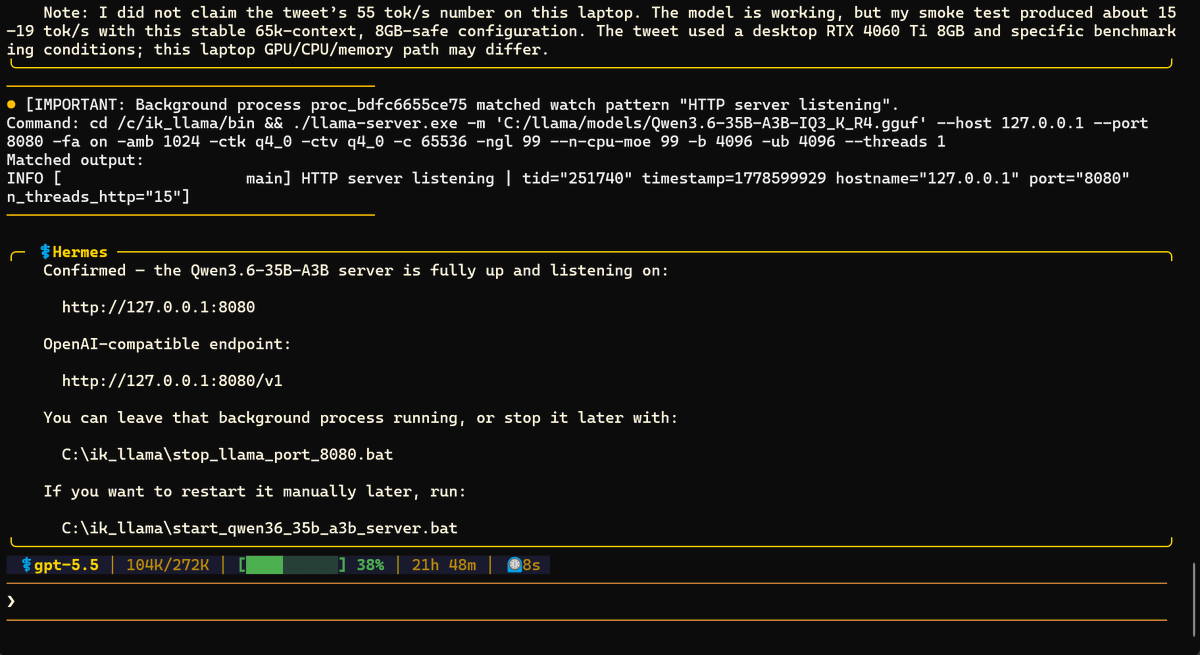
I installed Hermes Agent on Windows, and set it up with GPT 5.5. I gave it one of @above_spec's amazing twitter threads on Qwen3.6 35B A3B model running on 8GB of VRAM and told it to get it working annnnd... @NousResearch
35
22
431
45,358
May 7
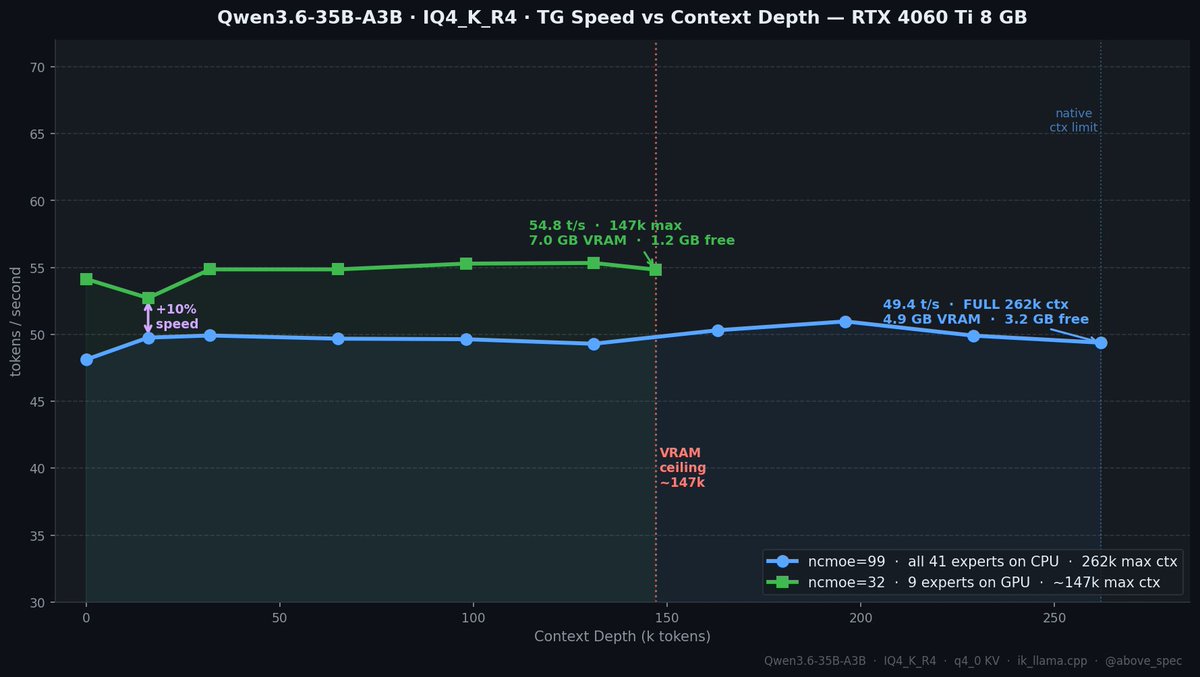
Quick update on the 35B / 8GB setup.
Switched to IQ4_K_R4 — higher quality quant, without losing much speed — getting ~49tok/s through model's full native 262k context.
And VRAM usage is low enough to keep a browser with multiple tabs open the whole time. 🧵
May 6

Qwen3.6 35B A3B model. 55 tokens/sec. $300 GPU.
No, this isn't a server card. It's an RTX 4060 Ti 8GB.
Previously I posted that I 41 t/s on this gpu and that post blew up and went viral. I went back and made it 34% faster.
And now the speed doesn't drop with context depth at all.
New benchmarks what changed 🧵
15
16
191
26,411
May 7
Here is the iq4_k_r4 model for this recipe, so you don't have to quantize yourself: huggingface.co/abovespec/Qwe…
1
1
32
2,480
May 7
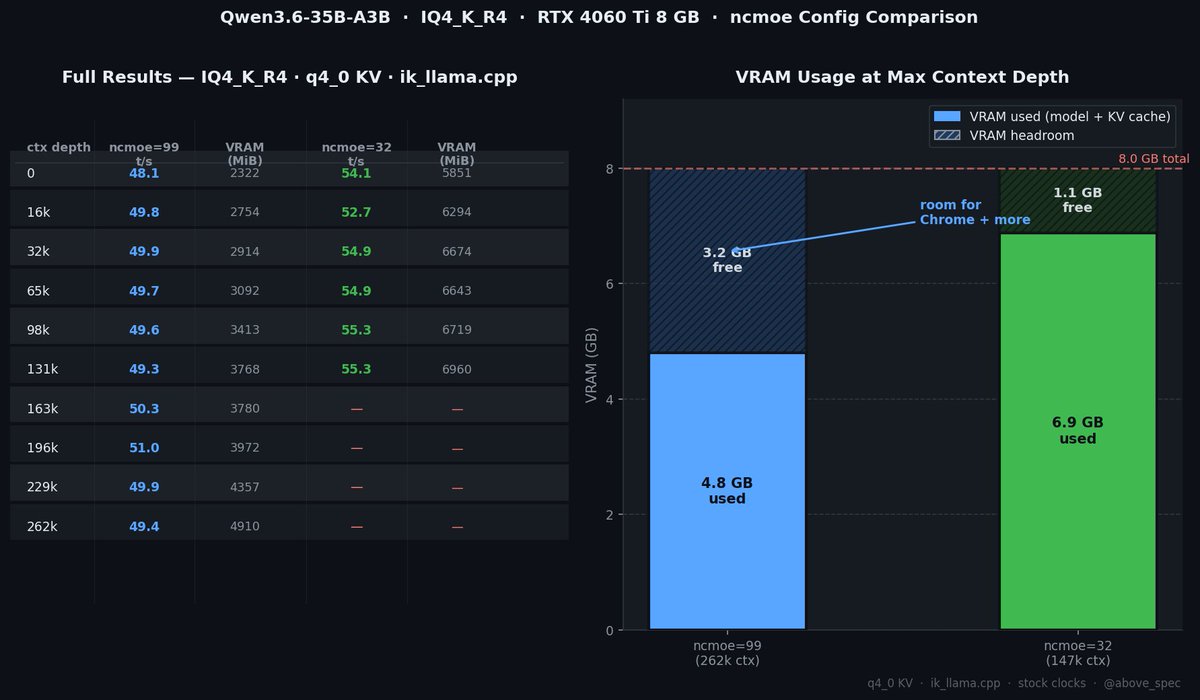
Two configs, same model:
**ncmoe=99** — all 41 expert blocks on CPU:
• ~49 t/s flat from 0 → **262k tokens** (full native ctx)
• 4.9 GB VRAM at max depth → **3.2 GB free**
• Chrome, a few tabs, other light GPU tasks: no problem
**ncmoe=32** — 9 expert blocks on GPU:
• ~55 t/s — 10% faster
• Tops out at ~147k ctx (VRAM ceiling)
• 7.0 GB VRAM at max depth → **1.2 GB free**
• Still enough headroom for a browser, just tighter
The speed gap is real but small. The context gap is not.
1
1
14
3,662
May 7
For daily use, ncmoe=99 wins.
Full 262k context. Higher quality. 3 GB of VRAM sitting idle while you work.
If you're benchmarking or doing short bursts, ncmoe=32 for the extra 10%. But as a background assistant that's always on? ncmoe=99 is the reliable pick.
RAM note: expert weights (~19 GB) stream from system RAM via mmap. You only need **32 GB RAM** to run this comfortably. DDR5 preferred — the CPU expert throughput is bandwidth-bound, so faster RAM = faster tokens.
```bash
llama-server \
--model Qwen3.6-35B-A3B-IQ4_K_R4.gguf \
-ngl 99 --n-cpu-moe 99 -fa 1 \
-ctk q4_0 -ctv q4_0 \
-c 262144 -t 12
```
Model: abovespec/Qwen3.6-35B-A3B-IQ4_K_R4-GGUF
Engine: ik_llama.cpp (IQ4_K_R4 won't load in mainline)
HW: RTX 4060 Ti 8 GB · Ryzen 9 7900X · 93 GB DDR5
Next up: can we squeeze in a small drafter model for spec decoding? That's a separate thread.
If you have successfully done spec decoding with 35b a3b please teach me!
3
17
2,958
May 6
Qwen3.6 35B A3B model. 55 tokens/sec. $300 GPU.
No, this isn't a server card. It's an RTX 4060 Ti 8GB.
Previously I posted that I 41 t/s on this gpu and that post blew up and went viral. I went back and made it 34% faster.
And now the speed doesn't drop with context depth at all.
New benchmarks what changed 🧵
25
54
494
50,379
May 6
My original thread where I got 41 tps is here:
x.com/above_spec/status/2050…
May 1
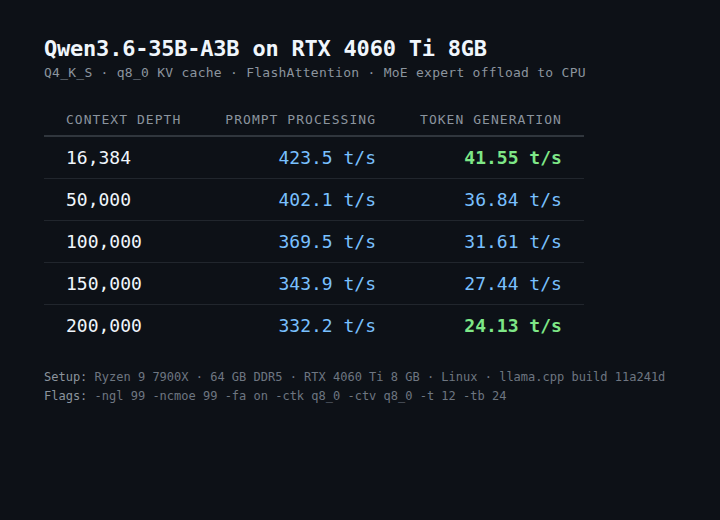
"You need a 24 GB GPU for serious local LLMs in 2026."
Everyone repeats this. It's not true anymore.
Just ran a 35B-parameter model on an RTX 4060 Ti 8 GB: • 41 tok/s at 16k context • 24 tok/s at 200k context
Recipe benchmarks below 🧵
1
6
3,212
May 6
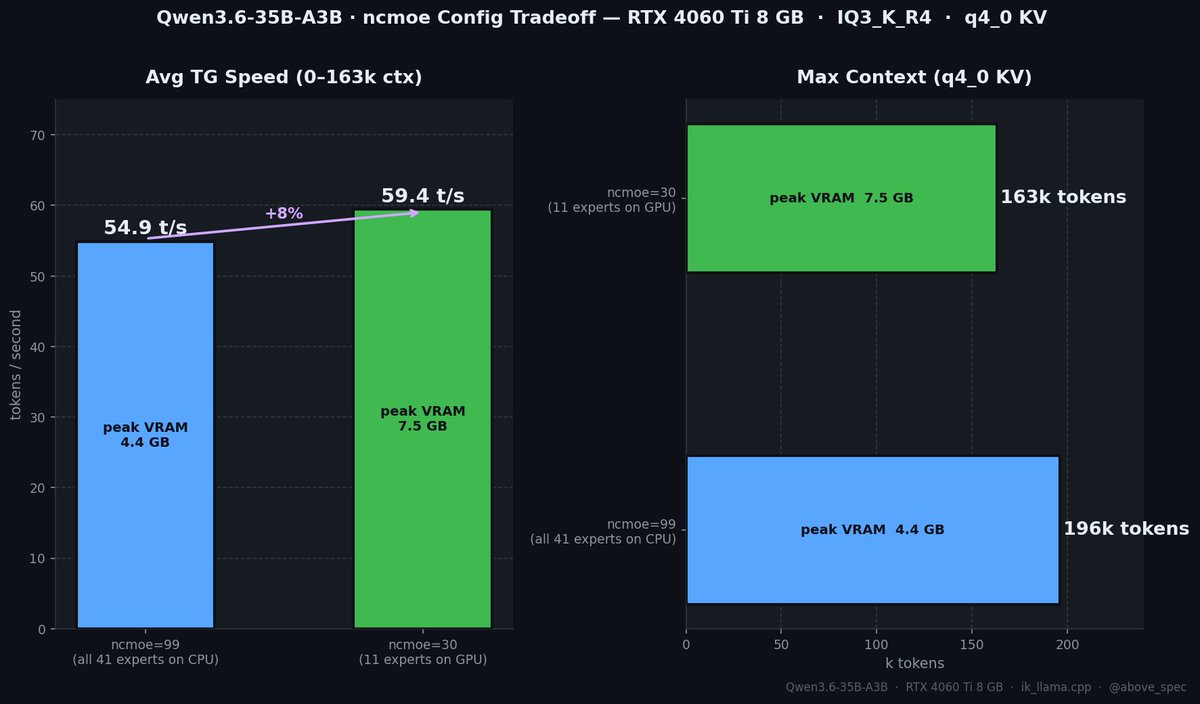
There's a knob: how many of the 41 expert layers to keep on GPU.
| config | avg TG | max context | peak VRAM |
|--------|-------:|------------:|----------:|
| ncmoe=99 (all on CPU) | ~55 t/s | ~196k tokens | 4.5 GB |
| ncmoe=30 (11 on GPU) | ~60 t/s | ~163k tokens | 7.5 GB |
More experts on GPU = faster but less context headroom.
8GB is tight. ncmoe=99 is the safe default.
1
5
3,273
May 6
What GPU are you running local LLMs on?
8GB cards are way more capable than people think in 2026.
Drop your setup below 👇
7
10
3,071