
Founder @ZenGuildGames | Lead Contributor @axisroboticsph
Joined September 2022
- Tweets 8,114
- Following 3,916
- Followers 2,114
- Likes 27,375
889 Photos and videos















Pinned Tweet

May 28
Building a strong local community for one of the biggest robotics projects in Web3 is more than growth. It’s about creating a movement driven by innovation, collaboration, and vision. Proud to keep pushing forward with @axisrobotics 🇵🇭
#axisrobotics #axisroboticsph

The Filipino community continues to grow stronger every single day 🇵🇭
More builders, creators, and innovators are stepping into the future of Physical AI together with Axis Robotics. The energy, support, and engagement from the community have been incredible to witness.
This is only the beginning the Philippines is ready to become one of the strongest communities in the ecosystem 🚀
#AxisRobotics #AxisRoboticsPH #PhysicalAI
5
4
18
562

Acee retweeted

Jun 12
gm gamers ദ്ദി(。•̀ ,<)~✩‧₊
not every day you get a shot at a PS5 and a fully sponsored trip to Dubai 👀
> June 21, 2026
> SMX Convention Center
> Manila, Philippines
> Free entry
see you there 👇
85
7
189
5,850
Acee retweeted

Jun 10
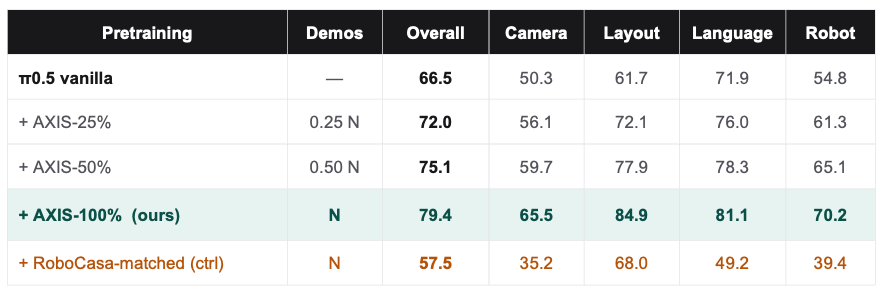
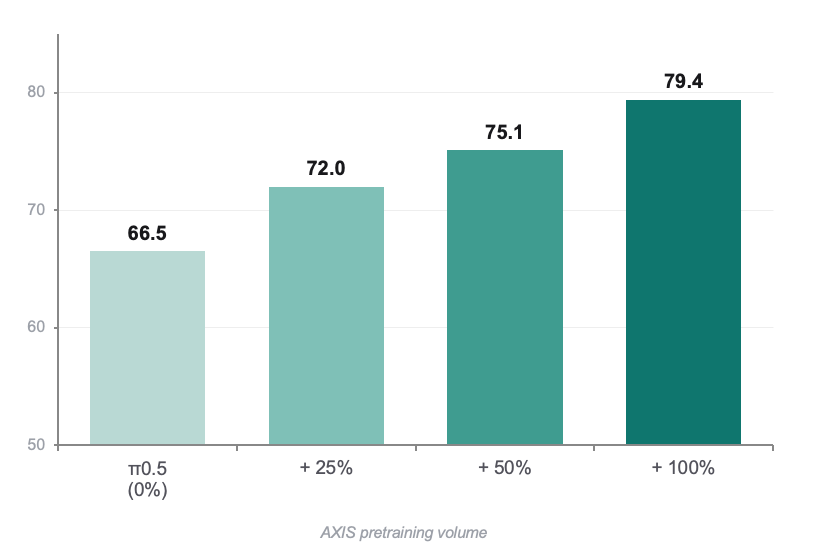
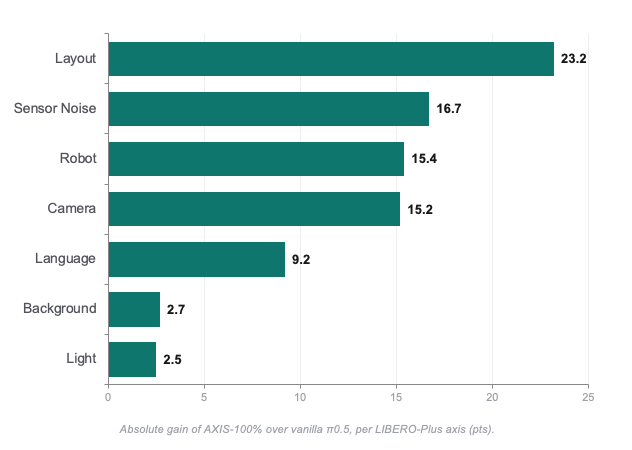
In our conference submission, we evaluate AXIS as a growable data engine for robot manipulation through three questions:
1. Does AXIS pretraining improve π0.5 on downstream LIBERO-Plus robustness tasks, beyond a matched-volume baseline?
2. Does the gain scale with AXIS data volume, from 25% to 50% to 100% of data volume?
3. Which perturbation axes benefit the most, and do they match the diversity targeted by our augmentation pipeline?
Here, “AXIS” refers to our growable manipulation dataset snapshot built around a Franka Research 3 robot: 207 tabletop tasks across 7 scene categories, 50k human demonstrations, and 60k task/scene variants produced through cleaning and semantic-preserving augmentation.
Findings below 🧵

Jun 8

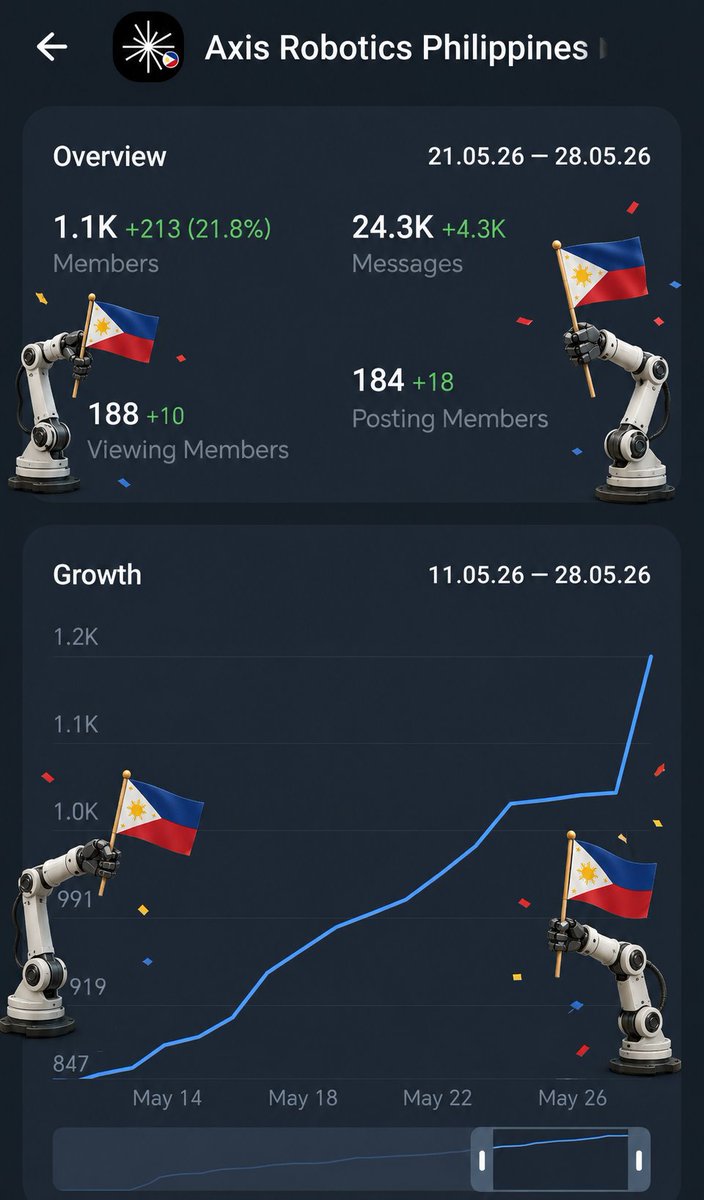
Axis Weekly
This week was about making the AXIS loop more scalable end to end: automating data-to-model workflows, testing recovery-driven training, expanding TaskGen coverage, and preparing the dataset and model stack for release.
Key updates:
- Data-to-model automation: We used scripts to speed up and standardize several repetitive but critical workflows.
- Continuous-growth training: We completed multi-data-scale training and success-rate comparisons across several failure tasks.
- Failure task expansion: A new batch of failure tasks has been pushed to test, expanding the evaluation range for ablations across data scale, data quality, and randomization.
- TaskGen: Articulated-object generation is now merged into the automatic generation pipeline.
- Model and release prep: We finished the first round of fine-tuning, evaluation, and benchmarking, completed the dataset’s conference submission, and are now improving experimental results for release.
Details below 🧵
63
25
128
4,864
Jun 7
A huge milestone for the entire @axisrobotics ecosystem! 🚀
Reaching 1 million trajectories on Base is a testament to the team's dedication, innovation, and the collective effort of the community.
#axisrobotics #axisroboticsph
Isang napakalaking tagumpay para sa buong komunidad ng @axisrobotics ! 🎉
Ang pag-abot sa 1 Milyong Trajectories sa @base ay patunay ng dedikasyon, inobasyon, at sama-samang pagsisikap ng team at komunidad. Nakakatuwang maging bahagi ng paghubog ng kinabukasan ng Physical AI at robotics.
#AxisRobotics #axisroboticsph #Robotics

1
1
57
Jun 7
It's exciting to see the progress being made as we continue building the future of Physical AI and robotics.
Congratulations to the Axis Robotics team and every community member who contributed to this achievement. Looking forward to many more milestones ahead! 🤖💪
24
Jun 6
Jun 5

Your Data is Important
Your Privacy Matters
Multi-Model Access is Essential
Take AI seriously 👉 askjune.ai

1
2
65
Acee retweeted

Isa itong mahalagang hakbang tungo sa paghubog ng kinabukasan ng Physical AI.
Sa pagpapalawak ng long-horizon at cross-embodiment tasks, patuloy na bumubuo ang Axis ng mas mayaman at mas scalable na mga dataset na mas sumasalamin sa mga totoong hamon sa larangan ng robotics. Ang pagtutok sa task adaptation, teleoperation, at iba't ibang robot morphologies ay magiging susi sa paglikha ng mas mahusay, mas matalino, at mas adaptable na robotic systems.
Nakakatuwang masaksihan kung paano patuloy na itinutulak ng mga inobasyong ito ang hangganan ng kung ano ang kayang matutunan at maisakatuparan ng mga robot sa hinaharap.
#axisrobotics #axisroboticsph
Jun 5
We recently launched a new set of robotic data collection tasks, with a focus on long-horizon tasks (LH) and cross-embodiment tasks (Multi Embodiment). These include bimanual teleoperation and task adaptation across different robot morphologies.
Why this matters:
1. Axis is moving toward more complex, real-world robotic tasks.
2. Long-horizon tasks make complex data collection more scalable in simulation.
3. Staged checkers turn long tasks into clearer training signals.
4. Cross-embodiment tasks help Axis support multiple robot forms and control modes.
5. Axis is improving both the diversity and complexity of data.
6. The goal is not just more data, but more valuable data.
Details below. 🧵


14
12
22
1,289
Acee retweeted
AI is leaving the data center.
@NVIDIA is betting on local, personal compute.
Edge-agent research is showing why that matters: the closer the agent is to the user, the more usable it becomes.
That is the OptimAI Claw thesis.
Search brings the signal.
Claw turns it into action on your device.
The network keeps intelligence distributed.
This is what agent-native infrastructure looks like when it is built for the edge.

OptimAI Core Node v2 is live.
And with it, the introduction of OptimAI Claw.
From nodes as infrastructure → to nodes as execution environments.
With Core Node v2, every device becomes a runtime for native personal agents.
👉optimai.network/optimai-node…
Get your node up and running.
No complex setup.
No fragmented tooling.
Just a few clicks... and your agent is live.
OptimAI Claw brings persistent, node-resident agents directly into your system:
• Multi-source research across web & social
• Real-time summarization and signal tracking
• Autonomous workflow execution
• Continuous learning through reinforcement
All running locally.
All under your control.
Supported on Windows & macOS.
This is beyond prompt-based AI.
Beyond isolated tools.
This is personal agent infrastructure.
Where every node thinks, acts, and evolves.
Claw is now part of the network.
And this is only the beginning.
Happy Building, Making Impact! 🔥
306
1,555
1,675
20,661
Jun 2
three free cards waiting for you every day on @PicksdotApp.
if you think you know ball, this is for you.
pull, predict, earn usdp. go.getpicks.app/r/aed5hyBHOA…
1
39
Acee retweeted
Jun 1
Axis Robotics is actively supporting and collaborating with leading researchers in Physical AI.
If you’re at ICRA or CVPR this week, come connect with our advisors and team at the workshops.
See you in Vienna and Denver.


Feb 26
We are thrilled to sponsor the 3rd MEIS Workshop at CVPR 2026!
As Generative AI redefines Embodied Multi-Agent Systems, Axis Robotics is proud to support the researchers pushing the boundaries of multi-agent collaboration, simulation, and robustness.
🏆 Best Paper & Demo Awards (Cash Recognition)
📅 Deadline: Apr 15, 2026
📍 Join us in Denver on June 3rd
Let’s build the future of collective intelligence together. Check out the details from Prof. Tu @_vztu below!
89
65
190
15,638
Jun 1
Currently sitting at 5,746 points on @PicksdotApp 🚀
There’s still plenty of time to grind during the beta phase and secure your spot on the leaderboard.
Register now, build your strongest team, and start earning points today:
go.getpicks.app/r/aed5hyBHOA…
#Picks
1
37
May 28
GM ☀️
• Focus
• Build
• Lead
• Inspire
Success starts with discipline and consistency. Keep pushing 💪
14
3
16
278
Acee retweeted

May 28
On-chain stocks give every timezone a seat.

14
13
171
3,741
Acee retweeted
Many tasks are now LIVE on the Axis Robotics Hub!
Complete the available tasks now and stay active before it’s too late 👌
Join here: hub.axisrobotics.ai/?tab=hub
Stay engaged. Stay ahead. ⚡
#AxisRobotics #AxisRoboticsPH
17
17
29
4,397
Acee retweeted

May 26
Summer is loading ☀️
Some people plan trips with 15 tabs, 3 group chats, and one emotional breakdown.
OptimAI Claw just needs one prompt.
Find the flights✈️ Compare the stays. Push the booking forward across @traveloka and @bookingcom without the tab chaos.
That’s the fun part of agentic AI:
less clicking, less stress, more “wait… we’re actually going?”
More freedom. More spontaneity. More time for beach plans, food hunts, and bad vacation selfies.
The best workflow is the one you barely notice.
💡optimai.network/ai-agents
372
2,192
3,088
26,983
May 26
Almost completed all task 👌
#axisrobotics #axisroboticsph
Many tasks are now LIVE on the Axis Robotics Hub!
Complete the available tasks now and stay active before it’s too late 👌
Join here: hub.axisrobotics.ai/?tab=hub
Stay engaged. Stay ahead. ⚡
#AxisRobotics #AxisRoboticsPH
2
3
39
Acee retweeted

May 26
🇵🇭 ❤️
May 26

EXCLUSIVE: Binance ties up with BlockShoals for Philippine market push
Binance — the world’s largest cryptocurrency exchange — and BlockShoals Technologies said on Tuesday that their collaboration in the Philippines follows more than two years of regulatory engagement with the Securities and Exchange Commission and is designed to bring practices into a compliant local framework.
READ: insiderph.com/binance-ties-u…

611
513
3,042
286,028
Acee retweeted

May 26
🇵🇭 JUST IN: Binance to enter the Philippines again via a BlockShoals partnership under the SEC’s sandbox framework.


209
320
1,739
235,711