
Director of AI/ML, @NYCOfficeOfTech. ai@nyc.gov. Opinions mine
Joined October 2007
- Tweets 21,132
- Following 2,998
- Followers 4,109
- Likes 23,744
1,809 Photos and videos















Jiahao Chen @NeurIPS retweeted

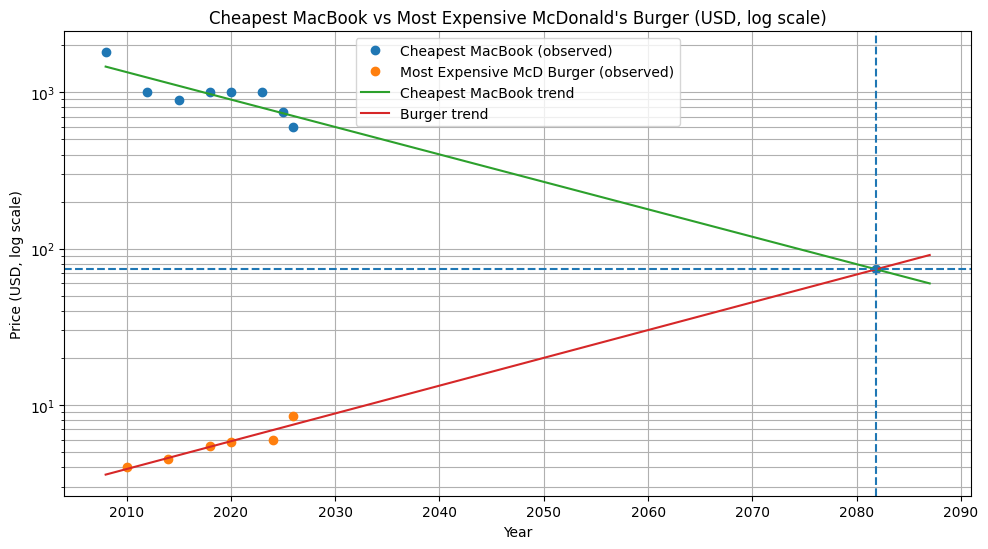
I've plotted the most expensive McDonald's burger and the least expensive MacBook over time. This analysis projects that the most expensive burger will be more expensive than the cheapest laptop as soon as 2081
404
2,464
37,283
1,141,638
Jiahao Chen @NeurIPS retweeted

Dr. Gladys West, Mathematician Whose Work Made GPS Possible, Dies at 95
thezebra.org/2026/01/18/dr-g…
118
3,483
10,794
206,099
Jiahao Chen @NeurIPS retweeted

6 Jun 2025
Can you train a performant language models without using unlicensed text?
We are thrilled to announce the Common Pile v0.1, an 8TB dataset of openly licensed and public domain text. We train 7B models for 1T and 2T tokens and match the performance similar models like LLaMA 1&2

22
149
631
179,233
Jiahao Chen @NeurIPS retweeted

3 Dec 2025
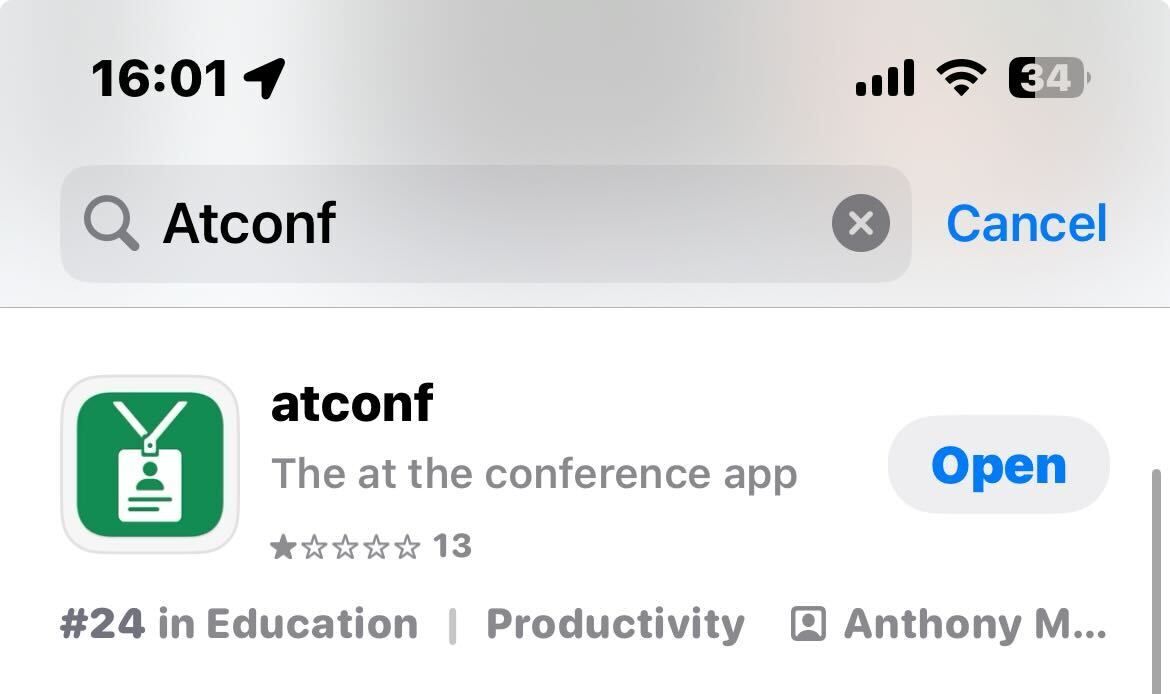
We have been made aware of several fake apps pretending to be the NeurIPS official app. To clarify, NeurIPS is using atconf. We advise attendees to carefully check thet they are downloading the correct app.
27
11
125
62,328

2 Dec 2025
I'll be at @NeurIPSConf - hmu to talk about new AI developments, applications to public sector or regulated industries, ethics reviews, AI safety and/or AI governance!
1
1
6
505
Jiahao Chen @NeurIPS retweeted

28 Nov 2025
a key lesson from this is that looking at the data should be the first thing you do, not a last resort after you try to debug some surprising low scores. it really amazes me how many people neglect to do this very obvious thing, and how unintuitive this advice is to them.

Got burned by an Apple ICLR paper — it was withdrawn after my Public Comment.
So here’s what happened. Earlier this month, a colleague shared an Apple paper on arXiv with me — it was also under review for ICLR 2026.
The benchmark they proposed was perfectly aligned with a project we’re working on.
I got excited after reading it. I immediately stopped my current tasks and started adapting our model to their benchmark.
Pulled a whole weekend crunch session to finish the integration… only to find our model scoring absurdly low.
I was really frustrated. I spent days debugging, checking everything — maybe I used it wrong, maybe there was a hidden bug.
During this process, I actually found a critical bug in their official code:
* When querying the VLM, it only passed in the image path string, not the image content itself.
The most ridiculous part? After I fixed their bug, the model's scores got even lower!
The results were so counterintuitive that I felt forced to do deeper validation. After multiple checks, the conclusion held: fixing the bug actually made the scores worse.
At this point I decided to manually inspect the data. I sampled the first 20 questions our model got wrong, and I was shocked:
* 6 out of 20 had clear GT errors.
* The pattern suggested the “ground truth” was model-generated with extremely poor quality control, leading to tons of hallucinations.
* Based on this quick sample, the GT error rate could be as high as 30%.
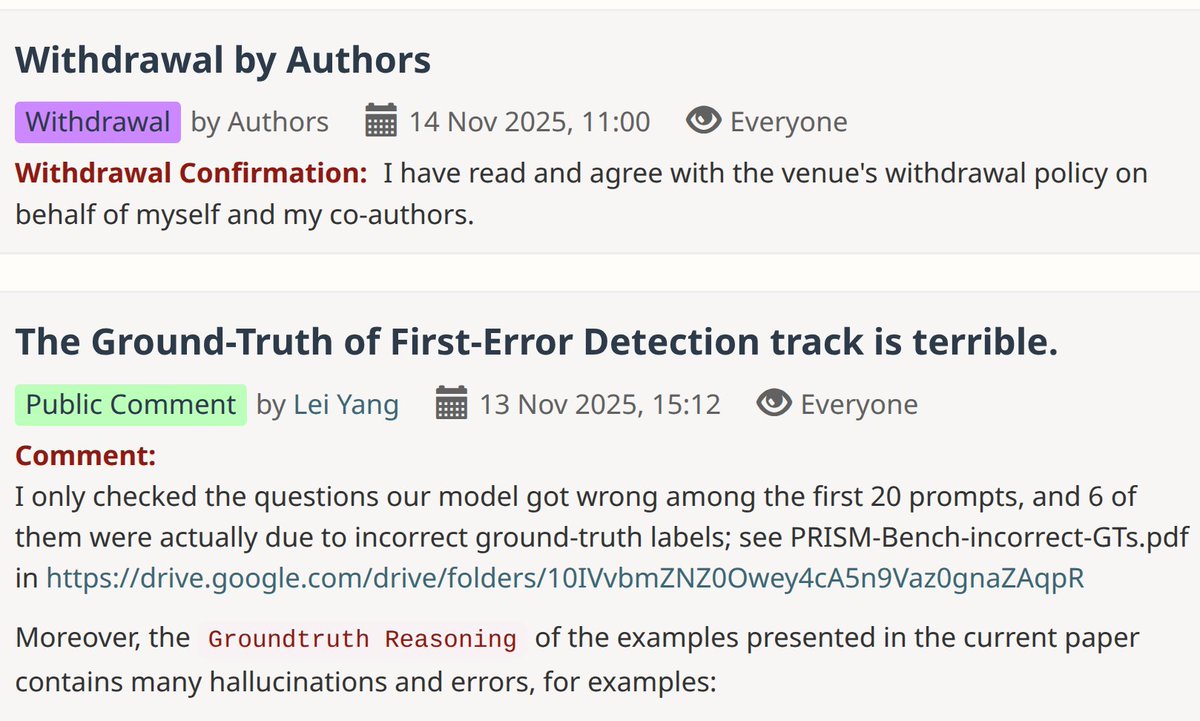
I reported the data quality issue in a GitHub issue. After 6 days, the authors replied briefly and then immediately closed the issue.
That annoyed me — I’d already wasted a ton of time, and I didn’t want others in the community to fall into the same trap — so I pushed back. Only then did they reopen the GitHub issue.
Then I went back and checked the examples displayed in the paper itself.
Even there, I found at least three clear GT errors.
It’s hard to believe the authors were unaware of how bad the dataset quality was, especially when the paper claims all samples were reviewed by annotators. Yet even the examples printed in the paper contain blatant hallucinations and mistakes.
When the ICLR reviews came out, I checked the five reviews for this paper.
Not a single reviewer noticed the GT quality issues or the hallucinations in the paper's examples.
So I started preparing a more detailed GT error analysis and wrote a Public Comment on OpenReview to inform the reviewers and the community about the data quality problems.
The next day — the authors withdrew the paper and took down the GitHub repo.
Fortunately, ICLR is an open conference with Public Comment. If this had been a closed-review venue, this kind of shoddy work would have been much harder to expose.
So here’s a small call to the community:
For any paper involving model-assisted dataset construction, reviewers should spend a few minutes checking a few samples manually. We need to prevent irresponsible work from slipping through and misleading everyone.
Looking back, I should have suspected the dataset earlier based on two red flags:
* The paper’s experiments claimed that GPT-5 has been surpassed by a bunch of small open-source models.
* The original code, with a ridiculous bug, produced higher scores than the bug-fixed version.
But because it was a paper from Big Tech, I subconsciously trusted the integrity and quality, which prevented me from spotting the problem sooner.
This whole experience drained a lot of my time, energy, and emotion — especially because accusing others of bad data requires extra caution.
I’m sharing this in hopes that the ML community remains vigilant and pushes back against this kind of sloppy, low-quality, and irresponsible behavior before it misleads people and wastes collective effort.
#ICLR #ICLR2026 #NeurIPS #CVPR #openreview #MachineLearning #LLM #VLM
7
27
356
119,312
Jiahao Chen @NeurIPS retweeted

26 Nov 2025
斜めに見えるやつ
+大丈夫+大丈夫+大丈夫
+大丈夫+大丈夫+大丈夫
+大丈夫+大丈夫+大丈夫
夫丈大+夫丈大+夫丈大+
夫丈大+夫丈大+夫丈大+
夫丈大+夫丈大+夫丈大+
+大丈夫+大丈夫+大丈夫
+大丈夫+大丈夫+大丈夫
+大丈夫+大丈夫+大丈夫
1,031
22,794
258,040
15,366,306
Jiahao Chen @NeurIPS retweeted

25 Nov 2025
INTs 199-A, 926-A, and 1024-A, sponsored by @CMJenGutierrez and @CMJulieMenin, create one of the nation’s first comprehensive municipal frameworks for oversight and transparency in the City’s use of AI by establishing an Office of Algorithmic Accountability and setting basic standards for agency use.

ALT Graphic announcing passage of INT 199-A, INT 926-A, and INT 1024-A, establishing an Office of Algorithmic Accountability and setting standards for city use of AI. Includes a ‘Passed’ banner and photos of Council Members Jennifer Gutiérrez and Julie Menin.
1
4
5
844
Jiahao Chen @NeurIPS retweeted

22 Nov 2025
I've had a surprising amount of people ask me about Copilot and the stick I'm poking it with. Copilot is a hot topic, so I assume people are genuinely interested in how it works?
I can't really give a good tl;dr because I'm still poking it with a stick. There is a lot of stuff I don't quite understand (as is tradition), so I can only share some of my insights and speculations
Copilot.exe (the main binary) is just a .NET runtime host. MSDN has some articles about it. Basically the .exe you execute does a bunch of fancy shit, it modifies some stuff in the .exe itself (Thread Environment Block) for custom error handling to be all fancy, or whatever. It eventually invokes the Windows Library Core Language Runtime library (libcoreclr) function "coreclr_execute_assembly" and the "real" Copilot runs from Copilot.dll.
Copilot.dll (I'll just call it Copilot, whatever) is a big ass fuck off C#.NET application with what feels like over 9000 dependencies and libraries. It's a big heavy bloated son of a bitch.
Copilot determines the .NET version it's supposed to run on from a JSON file in the current directory titled "runtimeconfig.json".
Copilot uses Microsoft UI Xaml (WinUI 3?) so it is ridiculously heavy and feels like it lags constantly.
Copilot does all AI stuff server side at Microsoft at "copilot-dot-microsoft-dot-com/c/api". It looks* like it authenticates to the Copilot servers using the Microsoft account you make when you first setup Windows 11. It looks like it may also support Apple and Google, but I haven't poked it enough.
Every action taken in Copilot is a "view" and goes through a URI thingy. It's some C#.NET bullshit. I barely understand it. You can easily see all the different "views" and the URI it goes through in Copilot to load different "views" (different parts of Copilot?)
Even simple acts as viewing a different "view", scrolling up to see previous messages sent to Copilot, etc. all go through API requests to Microsoft. It is all stored over on their stuff. Hence, Copilot can feel ridiculously slow when scrolling up to review message history. It goes through stuff like "GetConversationHistoryEndpoint" inside of CopilotNative.Platform (1.25111,85.0 .NETCoreApp, v9.0).
So... anything you do is going to through their web API. It slows things down dramatically. Even renaming a conversation makes a web call.
Also, anytime you send a message to Copilot it goes through a fucking MASSIVE nested procedure that bounces all through all the dependencies. However, this is pretty standard stuff for big .NET applications.
To make a long story short-ish, each message you to Copilot is tokenized (or rather, placed into a "Dictionary"). This dictionary contains the data you're sending and any files you're attaching. Part of this process Copilot makes a very minor attempt at sanitizing data for "anonymity".
Copilot has different stuff in place for removing data and sensitive information but the actual act of sending a message to Copilot only censors file paths from your machine (if you send a file). In other words,
C:\Users\TommyPoop\File.txt
transforms into ..
C:\Users\<redacted>\File.txt
I haven't seen anywhere else where this logic is implemented, but it probably does more stuff somewhere. I doubt they'd include all this PII censoring logic for no reason.
Copilot also has stuff in place for advertisement identifiers, health and fitness, shopping habits, etc. I'm not sure what that's all about. I also see the gaming stuff but I haven't poked that yet either.
Copilot also also has a bunch of stuff for PicassoAI for "PicassoLabs", "PicassoFinance", "PicassoBriefings". I don't know if this is a 3rd party thing or something they made internally. I have no idea what I'm looking at.
Anyway, that is my scattered thoughts on Copilot. It is basically a really, really, really fancy web browser that can only be used to communicate with Microsoft's AI endpoints.
I quickly realized though that if you go to
C:\Windows\System32\drivers\etc\hosts
... and make an entry that makes the Microsoft Copilot AI domain resolve to localhost, Copilot implodes and drops dead. It can no longer access any API endpoints hence it cannot exist.

45
229
2,151
811,385
Jiahao Chen @NeurIPS retweeted

18 Nov 2025
I am working to address an apparent error for a data point I cited in my book about the water footprint of a proposed data center in Chile. I’d like to explain what happened, what I’m doing to remedy it, and provide more recent data on the water footprint of data centers. 1/
66
139
1,777
662,261

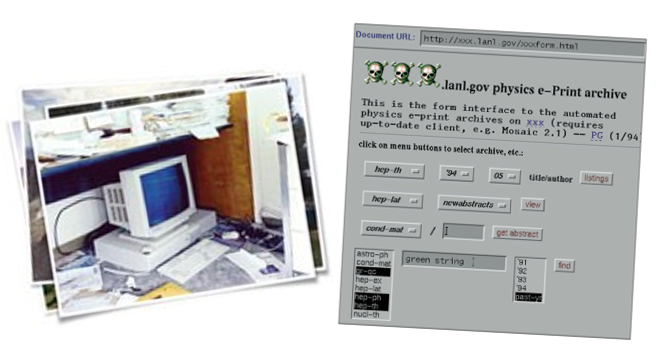
#HBD to arXiv!🎈
On August 14, 1991, the very first paper was submitted to arXiv. That's 34 years of sharing research quickly, freely & openly!
Some baby pictures to show how far we've come . . . when we were just a computer under desk . . . & in our 1994 punk phase . . . 👶💾
15
174
752
33,057
21 Jun 2025
It's that time of year again! @NeurIPSConf is seeking ethics reviewers for -four- review periods in July and August. If you're interested and available, please review our Call for Reviewers and sign up there!
neurips.cc/Conferences/2025/…
2
4
1,002

The 40th Annual AAAI Conference on Artificial Intelligence (AAAI-26), will be held in Singapore at The Singapore EXPO, January 20-27, 2026. The Main Track of the Technical Program will take place January 22-25, 2026.
➡️ Please note the updated timeline for AAAI-26 abstracts and paper submissions.
May 27, 2025 |Open Review submission site opens for author registration
June 3, 2025 | Open Review submission site opens for paper submission
July 25, 2025 | Abstracts due at 11:59 PM UTC-12
August 1, 2025 | Full papers due at 11:59 PM UTC-12
August 4, 2025 | Supplementary material and code due by 11:59 PM UTC-12
September 8, 2025 | Notification of Phase 1 rejections
September 28-30, 2025 | Author feedback window
November 3, 2025 | Notification of final acceptance or rejection (Main Technical Track)
November 13, 2025 | Submission of camera-ready files (Main Technical Track)
5
25
109
16,816
Jiahao Chen @NeurIPS retweeted
9 May 2025
This year's NeurIPS conference will initiate a position track. The position track paper deadline is May 22 AoE for all materials (abstract, full paper, supplementary, etc.). See Call for Paper for more details! neurips.cc/Conferences/2025/…
4
25
153
39,776
Jiahao Chen @NeurIPS retweeted
10 Mar 2025
NeurIPS 2025 is soliciting self-nominations for reviewers and ACs. Please read our blog post for details on eligibility criteria, and process to self-nominate: blog.neurips.cc/2025/03/10/s…
4
27
127
39,768
7 Mar 2025
The most Wikipedia thing I've seen in awhile is the warning on the ChatGPT logo page not to give it orders like it's actual ChatGPT and then have a prompt underneath the warning
2
2
23
2,367
22 Feb 2025
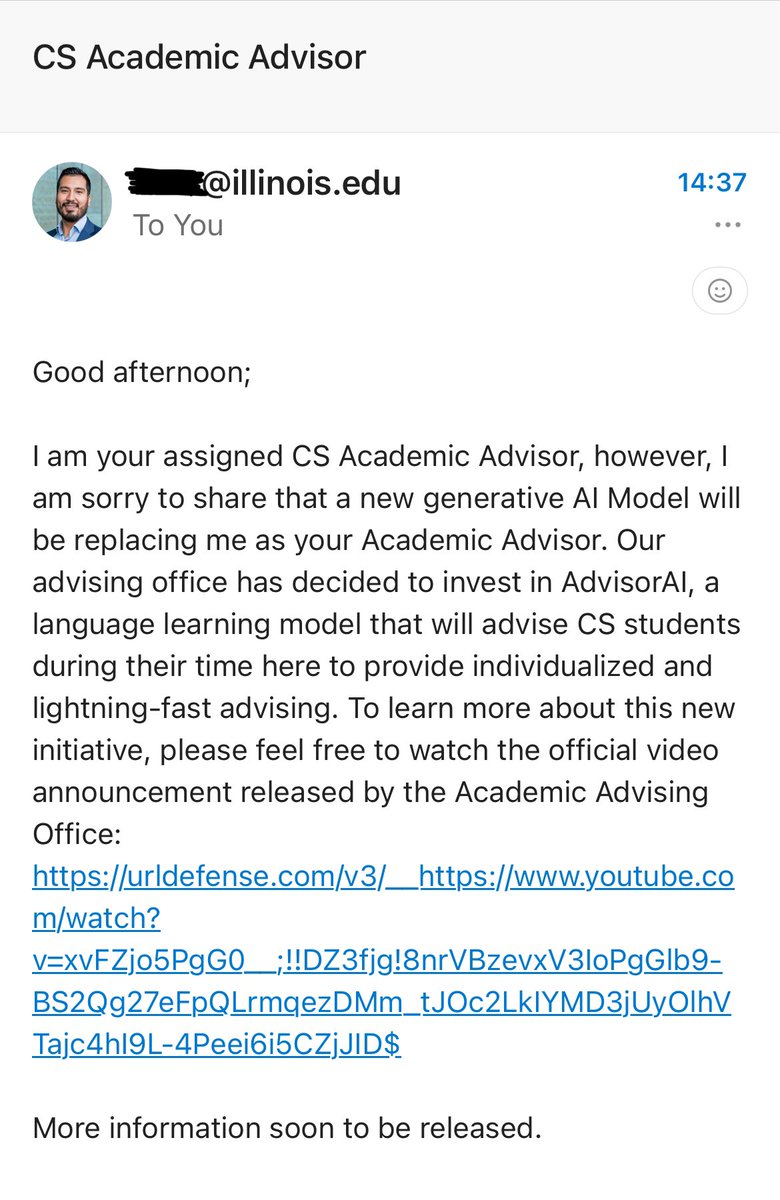
Shame on my alma mater

1
1
3
1,052
Jiahao Chen @NeurIPS retweeted
15 Dec 2024
Please read our statement on the remarks made by Dr. Rosalind Picard at her NeurIPS 2024 invited talk and our commitment to respect, inclusivity, and upholding our values:
neurips.cc/Conferences/2024/…
87
117
644
279,352
24 Nov 2024
RT @_austrian: Dear guests, you can stay connected with us on Instagram, TikTok, Facebook & LinkedIn. Feel free to reach out anytime via ou…
528