
Climbing the energy-information gradient. VP Product at ZoomInfo (AI, ML) - bad takes are my own. 🇺🇸
Joined May 2022
- Tweets 604
- Following 1,807
- Followers 282
- Likes 552
70 Photos and videos










Pinned Tweet

28 Nov 2025
As a grateful immigrant to this country, the country where my daughter was born, thank you. I'm thankful for everything this great nation has given me.
God Bless America 🇺🇸
4
247
May 9
That's not how economics or value creation works.
Firstly it's not zero sum. If it was we'd all be fighting over the nicest sticks and nicest caves. Wealth is created not stolen.
Secondly, wealth accumulation is not purely a function labor arbitrage. I'm sure exploitation does happen, but to state that's the only, or even main function of wealth accumulation is outright wrong.
Wealth accumulation happens because risk needs to be rewarded. Risk must be taken to resolve uncertainty, information production. What works and what doesn't. Without risk information cannot be produced and we can't coordinate effectively.
Socialism doesn't work because it believes it can compute centrally what needs to be computed in a distributed manner.
Cc @PalmerLuckey

Almost all of a billionaire's worth is from collecting the difference between the value of labor and the market price for labor. Is it exploitation? In a market where the gap between rich and poor is huge and expanding, I'd say there is some exploitation happening.
17
May 2
Unobvious and often glossed over point: how your data and context layer handles time is what actually kills many serious AI use cases.
Most enterprise stacks operate as a set of state machines without memory. And most applications only maintain current state, a lossy snapshot of right now. When a state transition happens, the system literally overwrites the previous value.
Think about a sales pipeline. A deal moves to "Negotiating". CRM captures that destination state and maybe a timestamp. What it completely drops is the reasoning, the gate criteria that were met, the actual conversation, or the exceptions you carved out. The entire decision chain collapses into a single, static field value.
Current state without history is completely stripped of context. A customer who converted smoothly is a fundamentally different relationship than one who churned, fought with your team, re-engaged, and forced a custom pricing tier. Their current state in the database is identical; their transition history is not. And that transition history is often where the most valuable context lives.
Because most systems discard this temporal provenance, you force it to be externalized. It gets pushed out into the unstructured hinterlands of email threads, call transcripts, and Slack channels.
Mostly, this gets pushed into "meat storage" - people's memory's, tribal knowledge. Not helpful for AI.
12
May 1
There is an existential threat looming for many SaaS vendors and it isn't vibe coding killing their UI.
Look at what many enterprise software vendors actually sell you. Most enterprise software is just a visual workflow wrapper over basic CRUD operations and a narrowly defined set of state transitions.
A CRM is a proprietary state machine layered on a specific slice of the Organization and Contact entity types, concerned exclusively with the sales lifecycle.
A customer support system takes a different slice: an intersection of the Organization and Task types, with a distinct state machine optimized for issue resolution.
A project management tool is yet another slice: Project, Task, and Person entities bundled with state machines for tracking completion.
The foundational architectural flaw crippling your systems is that each vendor claims ownership over its own functional shard. Every application introduces its own proprietary metadata schema, state definitions, user interface, and pricing model.
Consequently, the exact same Organization entity—your customer—is blindly replicated across the CRM, the support desk, the marketing automation platform, and the billing system. The same Project entity lives separately in the task tracker, the time-tracking software, and the reporting dashboard.
This creates a massive, enterprise-wide fragmentation problem. You are left with redundant copies, divergent schemas, and decentralized sources of truth that consistently fail to agree on the current state of a given entity.
If your own software stack cannot even agree on the current state of your business, your AI has zero chance of figuring it out.
The problem for SaaS vendors is, the pull and promise of AI is much stronger than the pain of ripping them out if they get in the way. A certain class of SaaS (lack of data moat and machine readable interfaces) will find the next 5 years very difficult.
15
May 1
If you want to build enterprise AI that works, you have to look past the surface-level SaaS workflows and reduce business data down to its absolute base level.
You need to find the minimal structural primitives that actually compose an enterprise.
Everyone loves to insist their company's internal operations and data models are uniquely complex. They almost never are.
Every enterprise operates on a defined set of ontological types. While the specific types might vary slightly depending on your exact domain, core primitives like Organization, Person, Task, and Artifact show up in nearly every single enterprise.
At the end of the day, your entire business is simply a semantic graph built from these recurring building blocks.
The real engineering insight is how this graph behaves over time. What MBAs dress up as a complex "business process" is literally just a state machine moving these underlying entities through defined transitions.
Take your go-to-market motion. Sales teams treat a "prospect" and a "customer" as fundamentally different things. Architecturally, they are not different entities at all; they are identical types (an Organization) simply occupying different states. The "customer lifecycle" is just the state machine governing the transitions between those states.
The exact same logic applies to engineering and ops. A "project" isn't a bespoke workflow. It is merely a container of Task entities moving through a simple state machine from backlog, to in-progress, to review, and completion.
The underlying informational structure of business is remarkably simple. Recognizing this simplicity is the key to understanding what incumbent software vendors are really selling.
7
May 1
The easy way to understand where the alpha in AI is (outside of foundational labs).
Every knowledge work task breaks down into three components.
First, you need competence, which covers cognitive skills like writing, analysis, and judgment. AI models already handle this at or above human levels for many tasks. The labs own this.
Second, you need effectors. These give you the ability to actually act on the world, like sending an email or updating a record. Since effectors rely on APIs and programmatic interfaces, they are just a solvable engineering problem.
Third, you need context. Context provides the situated business knowledge that turns a generic skill into a specific, appropriate action. It tells you things like exactly who a customer is, what state they occupy, and why past decisions happened. This knowledge is the only thing that separates a generic command like "write a professional email" from a targeted action like "follow up with the VP of Engineering about their stalled implementation". This is not solved for 95% of use cases yet.
These three pieces live in completely different places. The AI model provides the competence. The integration layer handles the effectors. But your enterprise data architecture dictates the context. Models scale rapidly and engineers solve the integrations, leaving context as the main structural bottleneck.
AI at the enterprise level gets stuck because decades of architectural decisions prevent companies from actually exposing their operational reality. Massive amounts of opportunity exist in fixing this.
27
Apr 27
is SaaS dying or are millions of people vibe coding integrations into the existing stack?
harder to churn out if 80 people will complain because it breaks their agent.
17
Apr 27
LLMs can already write, analyze, reason, and operate tools through APIs. What they can't do, in most enterprises, is figure out what's actually true about the business.
Competence is a property of the model. Context is a property of your data architecture. And decades of buying specialized tools have left most enterprises with the same customer represented four different ways across the CRM, the billing system, the support desk, and the marketing platform, with conflicting values and no shared timeline of how anything got to its current state.
I wrote a working paper on this. It reduces enterprise data to ontological primitives (typed entities moving through state machines), shows how the software stack fragments that ontology across vendors, and argues that human workers have been quietly serving as the integration layer this whole time, holding metadata in their heads and reconciling it through meetings and Slack.
The framework assesses AI readiness across two layers (current state and transition history) and four dimensions (completeness, coherence, legibility, operability). Coherence is the load-bearing one because its failure mode is non-linear.
The proof case is software engineering, where coding agents already work at scale. A codebase is a complete, coherent, legible, operable ontology with full version history in git. That's the bar, and almost no other enterprise function meets it yet.
I'll break down the individual ideas in follow-up posts over the next couple of weeks.
papers.ssrn.com/sol3/papers.…
10
Mar 5
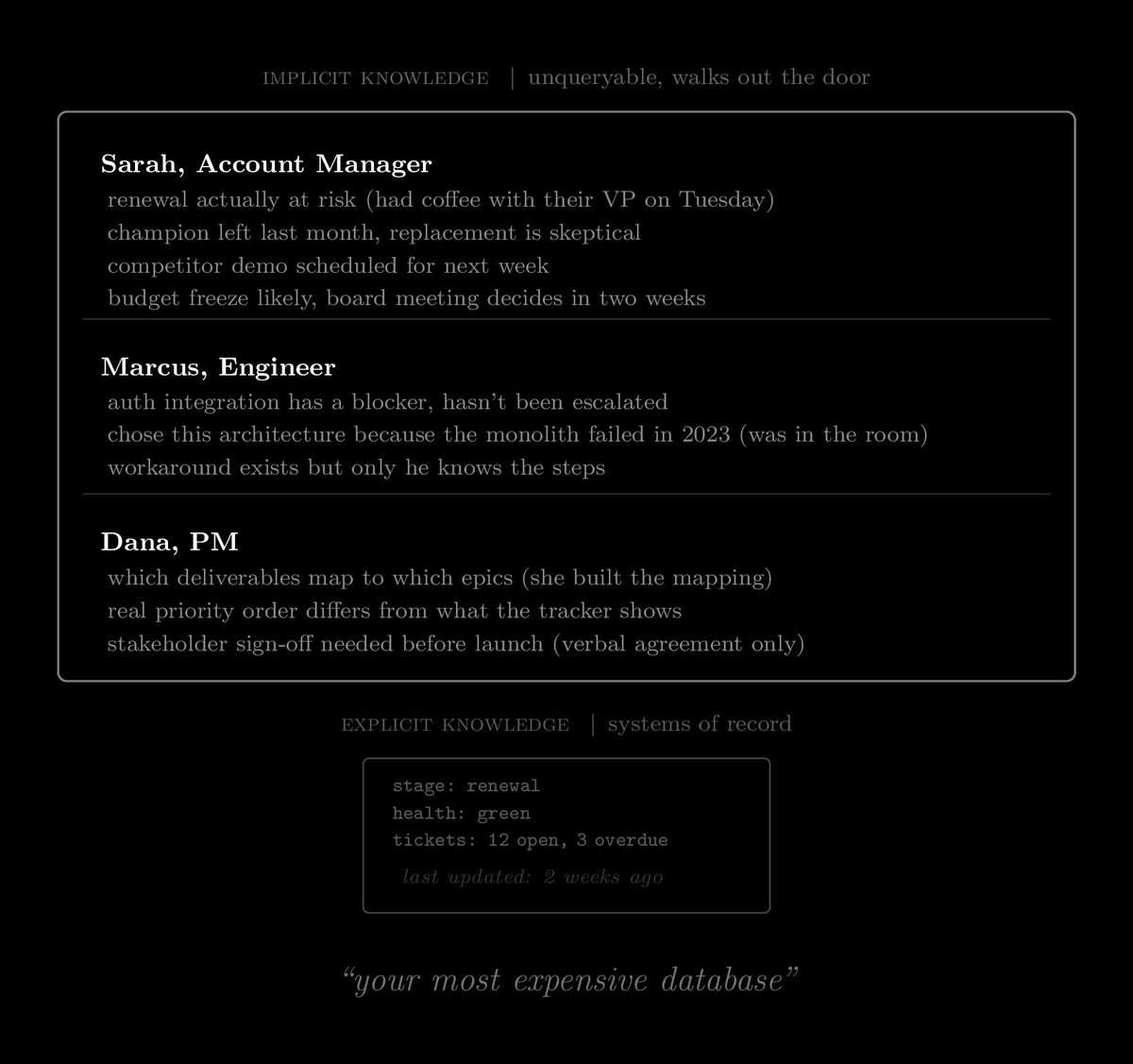
Your most expensive database is probably your payroll, because every employee stores business state that exists nowhere else. The account manager knows the real status of the renewal because she had coffee with the VP last week, and the engineer knows why that architecture decision was made because he was in the room, and all of that took months to embed through onboarding and hallway conversations.
It walks out the door every time someone leaves, and you can't query it with an AI system because none of it was ever written down. We built a whole data architecture around human memory and then wondered why the AI can't find anything useful to retrieve.
The companies I see getting ahead on AI started capturing decisions and context as a byproduct of how people already work, so when the model goes looking for institutional knowledge, it's actually there.
4
2
51
Mar 3
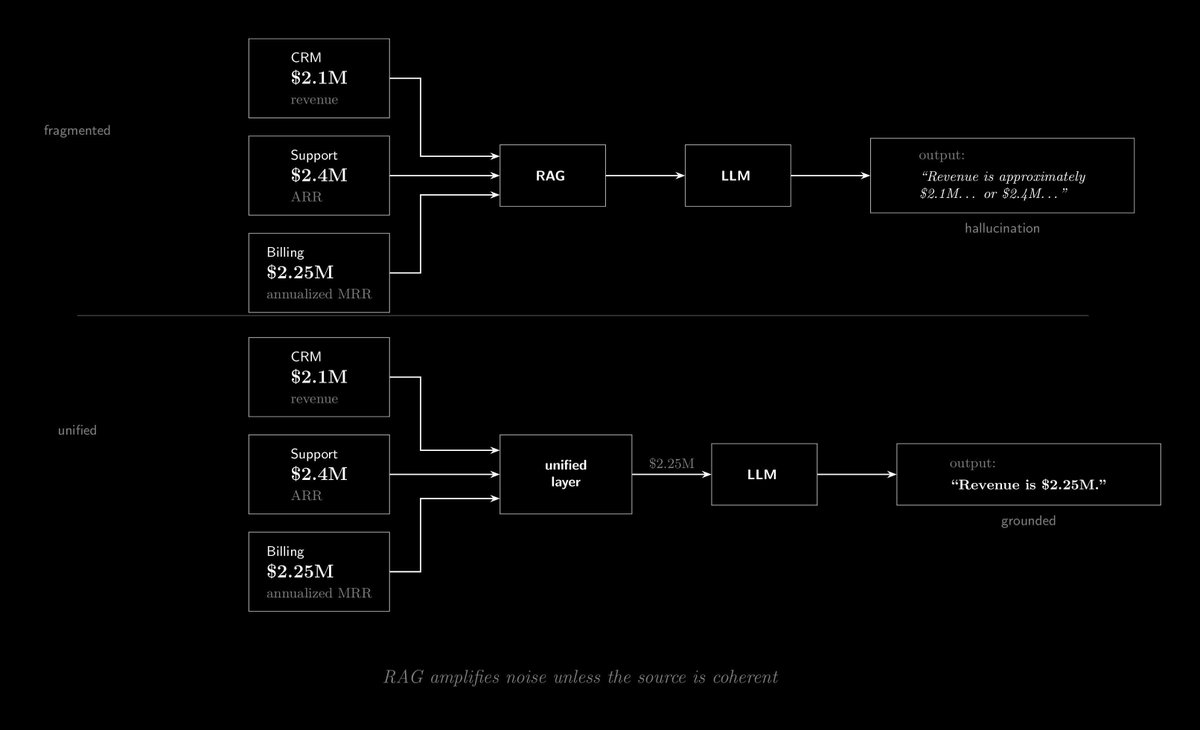
The default enterprise AI play right now is RAG, where you pull context from your systems and feed it to a model, and it makes sense until you look at what's actually being retrieved.
Your CRM says the customer is worth $2.1M, billing says $2.25M annualized from MRR, support says $2.4M in ARR. You retrieve all of that and the model gets three conflicting numbers with no way to know which one is right, so it fills the gap from training data instead of your actual business state, and that's where the hallucinations come from.
I keep seeing teams spend months on model selection and prompt engineering when the actual problem is upstream. RAG just moves fragmented data into the model faster, which means the contradictions arrive faster too.
The teams getting real value from this figured out which source is canonical for what and cleaned up the conflicts before they started building, which is tedious but it's where the results actually are.
1
2
42
Feb 27
if your AI initiative isn’t working it’s not the models. the models are good enough, they’ve been good enough for a while. the bottleneck is fragmentation.
you have the same customer represented differently across six (or sixty) systems. the CRM says “Acme Corporation,” support says “ACME Corp,” billing says “Acme Inc.” a human pattern-matches through that without thinking. an AI system hits conflicting records and starts guessing. guessing is hallucination.
think about it as a signal problem. your business data is signal. fragmentation introduces noise in two ways: gaps in coverage, where the model fills in from its training data, and conflicting information across systems, which degrades the signal further. more fragmentation, noisier channel, less reliable output.
this is also why bolting on RAG keeps disappointing people. retrieval-augmented generation works when the retrieved context is coherent. retrieve conflicting information from three systems and you’ve amplified the noise.
before you fund another AI pilot, audit where your institutional knowledge actually lives. how much is in systems vs. in people’s heads? how consistent is it across sources? the strategic priority is data and state coherence. everything else depends on it.
1
50
Jan 2
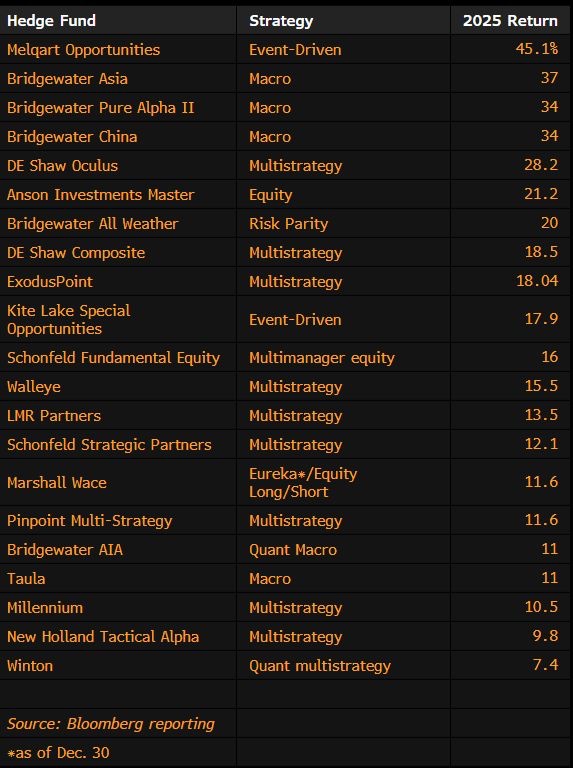
2025 fund returns, doesn't include fees.
My personal portfolio return was 21.4%
1
1
53
23 Dec 2025
The best investment any company can make right now is upskilling and releveling talent to be AI-first. If the people in your business can’t leverage AI, your business can’t leverage AI. AI isn’t going to just show up, replace everyone, and take over. It will be integrated collaboratively with our existing workflows and teams.
Over time, yes, you’ll need fewer people to get the same amount of work done. But that’s exactly what happened with computers, the internet, and networked information systems. They all created massive leverage, but none of it worked without people. AI will follow the same pattern.
Forget about hypothetical AGI or superhuman intelligence for now. The real question is the next 5 to 10 years. How will your business succeed and take advantage of this technology? It comes down to one thing: investing in talent.
2
79
23 Dec 2025
Every single-player tool eventually loses to a multiplayer tool.
What’s interesting about the current state of applied AI, especially in the enterprise, is that most applications are either:
1. Single-player by design, or
2. Multiplayer by legacy, meaning AI is being plugged into an existing multiplayer system and doing the best it can.
But the AI itself usually isn’t “multiplayer” in those contexts. It feels like we haven’t yet seen the biggest companies or the top players in most verticals, the ones that will truly embrace multiplayer AI.
Who’s actually building multiplayer AI today?
2
96
22 Dec 2025
There are basically two dominant stories being told about AI right now, and neither of them is right.
One says AI is overhyped, unreliable, and basically vaporware. The other says we’re on the verge of post‑AGI, that it’s the most transformative technology we’ve ever seen, and everything will change in the next couple of years. I think both of those takes are wrong.
There are two other stories that I think better capture where we're at. First, foundational AI research is progressing incredibly fast. We’ve seen multiple orders of magnitude in performance improvements and cost reductions over just the last few years. Second, applied AI, the part that actually drives productivity, economic growth, and real value, is lagging.
One big reason is that the talent needed to translate raw model capabilities into enterprise value is scarce. OpenAI, Anthropic, Google DeepMind, they’ll capture some value, of course. But most of the long‑term value will come from the businesses that figure out how to build on top of this technology and make it useful. Think of the early internet: right now, we’re basically in the pre‑2000s phase. The tech is revolutionary, but the applications haven’t fully caught up yet.
Both things can be true: AI can be disappointing today in many ways, and at the same time, it can be a revolutionary technology whose impact is inevitable once the foundational progress and the applied use cases converge.
3
5
18,528
22 Dec 2025
Over the next couple of years, 2026 and 2027, we’re going to see the rise of more verticalized, hyperfocused AI and intelligence systems. I’m talking about small language models, fine-tuned architectures, and federated model systems.
It feels similar to what happened after the cloud transition. When software “ate the world,” we saw a Cambrian explosion of SaaS, every conceivable type of software for every use case and vertical. That kind of verticalization hasn’t really happened in AI yet. So far, we’ve mostly seen legacy SaaS vendors bolting AI onto their products, rather than true ground-up vertical AI systems.
Part of the reason is that foundational AI research is moving faster than enterprises can apply it in real time. And the talent to build these specialized systems just isn’t widespread yet. But I think the next two years will mark the early stages of that wave.
That’s basically what ZoomInfo is doing right now, building a federated intelligence system specifically for GTM.
2
76
22 Dec 2025
The biggest friction for AI over the next two years will be at the applied level, not the foundational level. The models and core capabilities are advancing quickly, but enterprises are struggling to actually integrate them into workflows and get real leverage.
The gap is mostly on the talent side. There just aren’t enough engineers or architects who know how to work with these models and meaningfully embed them into business processes. That’s where adoption will lag.
1
23
22 Dec 2025
I wouldn't say we celebrate the startup over the small business owner, but raising $4m is an event, whereas earning it is a process.
Generally as a society we don't celebrate processes, but we love to make noise about events.
Think about all major life celebrations, they usually the culmination of a process (graduation) or the start (marriage).
No one cares about the startup after the raise until there's some other event that must be bigger and better than the one before.
The process is what matters fwiw.
20 Dec 2025

We strangely celebrate the startup that raises $4M more than the small business owner who earns $4M.
1
39
21 Dec 2025
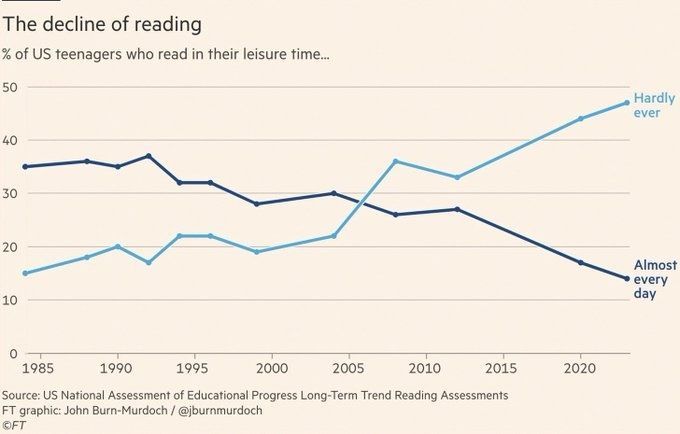
We're doing kids a disservice if we let them fry their brains with short form media and emotionally manipulative social content, and miss the joys and depth of reading.
20