
Joined August 2017
- Tweets 412
- Following 570
- Followers 8,086
- Likes 803
32 Photos and videos












16 Dec 2025
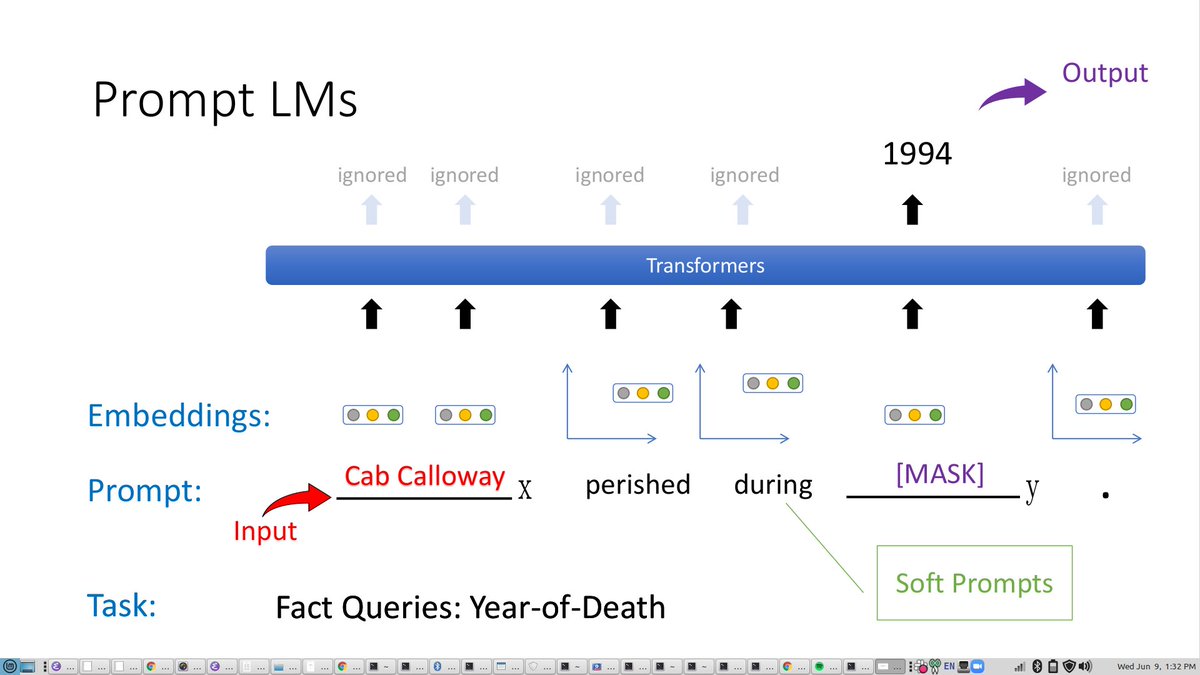
LOR deadline day ... so many required fields! ... luckily a few of them have a high character limit
1
1
33
4,343
Jason Eisner retweeted

Congratulations to all @JohnsHopkins researchers participating in #ICLR2025! Check out all @JohnsHopkins accepted papers, tutorials, and workshops at ai.jhu.edu/news/johns-hopkin….
16
7
12
2,486
13 Nov 2024
Who wants to come to JHU and do a postdoc with me?? I'm always enthusiastic about new modeling / inference / algorithmic ideas in NLP/ML. Also selected applications.

We’re thrilled to announce the #HopkinsDSAI Postdoctoral Fellowship Program! We’re looking for candidates across all areas of data science and AI, including science, health, medicine, the humanities, engineering, policy, and ethics.
Apply today!
ai.jhu.edu/postdoctoral-fell…
2
8
39
8,771

New #ACL2024 paper: LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error (@BoshiWang2's internship work at Microsoft Semantic Machines)
I like this work because it takes home an important insight: synthetic data post-training is critical for agents.
Agents need perception-decision-execution capability and data, which is hard to get from pre-training because data on the Internet is mostly artifacts produced by such processes, not capturing the processes per se. I believe LLMs synthetic data environmental feedback will prove to be an immensively successful recipe for agents, and our work is just an early example of that.
Nice work @BoshiWang2 @hfang90 @adveisner @ben_vandurme

Thanks @_akhaliq for sharing our work led by @BoshiWang2 from @osunlp, so let's chat about how LLMs should learn to use tools, a necessary capability of language agents.
Tools are essential for LLMs to transcend the confines of their static parametric knowledge and text-in-text-out interface, empowering them to acquire up-to-date information, call upon external reasoners, and take consequential actions in external environments. But existing tool learning strategies for LLMs are not fully unleashing this potential––we find existing LLMs, including GPT-4 and ones specifically tuned for tools like ToolLLaMA, only achieve 30% to 60% correctness in tool use. Very far from the high level of accuracy needed for practical deployment in high-stakes scenarios.
A closer look at existing methods reveals that people seem to be overly focused on rushing to add as many tools as possible or make it easy to add new tools, either through in-context learning or fine-tuning. Perhaps surprisingly, a critical aspect, how to make LLMs use existing tools as accurately as possible, is largely overlooked.
How to Truly Master a Tool?
We turn to successful precedents in the biological system such as humans, apes, and corvids. Learning to use a tool is a rather advanced cognitive function that depends on many other cognitive functions:
> Trial and error is essential for tool learning. We do not master a tool solely by reading the ‘user manual’; rather, we explore different ways of using the tool, observe the outcome, and learn from both successes and failures.
> Intelligent animals do not just do random trial and error—we proactively imagine or simulate plausible scenarios that are not currently available to perception for exploration
> Finally, memory, both short-term and long-term, is instrumental for the progressive learning and recurrent use of tools
So why should we expect an LLM to magically master a tool by just looking at the ‘user manual’ (API specification) or several examples? That's even hard for humans who are equipped with many cognitive substrates missing in LLMs!
Simulated Trial and Error (STE)
> STE is a biologically inspired method for tool-augmented LLMs that combines trial and error, imagination, and memory.
> Given a tool, STE leverages an LLM to simulate, or ‘imagine’, plausible scenarios for using the tool. It then iteratively interacts with the API to fulfill the scenario by synthesizing, executing, and observing the feedback from API calls, and then reflects on the current trial. We devise memory mechanisms to improve the quality of the simulated instructions. A short-term memory facilitates deeper exploration in a single episode, while a long-term memory maintains progressive learning over a long horizon
> STE allows an LLM to sufficiently explore and probe the capability boundry of a tool. With the tool use examples from STE, one can either use them for in-context learning or fine-tuning
Result Highlights
> GPT-4: 60.8 -> 76.3 📈
> Mistral-7B: 30.1 -> 76.8 📈📈 and outperforms GPT-4!
> Llama-2-7B: 10.7 -> 73.3 📈📈📈
> Also substantially outperform existing tool-augmented LLMs like ToolLLaMa-v2 (37.3)
But will the tool fine-tuning destroys the LLM's other capabilities?
No worries, we got you covered. A simple experience replay strategy is enough to maintain an LLM's existing capabilities while learning new tools!
📌 Paper: arxiv.org/abs/2403.04746
📌 Code: github.com/microsoft/simulat… (fairly easy to use. try it out on your own tools!)
1
16
81
14,686
4 May 2024
Great last-minute summer opportunity on LLMs for social good / democracy! (If you're an #NLProc PhD student.) Please retweet.
(Team includes @adveisner @DanielKhashabi @ZiangXiao @AndrewJPerrin students.
8 weeks alongside 3 other teams: fun, meaningful, educational, social.)
1 May 2024

WHAT: "AI-Curated Democratic Discourse," a JSALT hackathon team this summer (Jun 10-Aug 2)
GOAL: Redesign the social media UI to raise the quality of reading and posting, with the help of LLMs🤯
WHO: Looking for 1 more funded, in-person NLP PhD student! DM me with yr skillz.
16
20
8,972
1 May 2024
WHAT: "AI-Curated Democratic Discourse," a JSALT hackathon team this summer (Jun 10-Aug 2)
GOAL: Redesign the social media UI to raise the quality of reading and posting, with the help of LLMs🤯
WHO: Looking for 1 more funded, in-person NLP PhD student! DM me with yr skillz.
1
8
19
16,594
1 May 2024
Project description: cs.jhu.edu/~jason/tmp/eisner…
Event format: clsp.jhu.edu/2024-jelinek-su…
I'll take questions here.
If you know someone great for this, please have them email me, thx! (Someone tuned into political discourse and UI design who is great at coaxing behavior out of LLMs?)
1
6
1,622
8 Jan 2022
How about "nonn" as shorthand for "not necessarily"?
"Let F be any nonn-convex function"
"The bounded region defined by these nonn-linear constraints"
"The trouble is the nonn-decomposable path score"
"REINFORCE works in nonn-Markov environments"
"WFSAs are nonn-determinizable"
3
1
13
8 Jan 2022
People often say "non" in these settings but "nonn" is what they really mean.
It's tempting to also coin innfinite and irrrational.
However, I think nonn-finite and nonn-rational are safer!
2
6
16 Mar 2024
Today I had to refer to an unnbalanced / nonn-balanced binary tree ...
1
3
1,129
18 Feb 2024
Can we go back to 1657 to tell Huygens that instead of "expectation," he should call it "argmean"?
"Don't ask, Chris. It'll make sense in a few hundred years."
1
1
29
5,268
18 Feb 2024
Huygens 1657 was the first published work on probability. As far as I can tell, this 1714 translation first introduced this sense of "expectation" into English.
(The quote is asking: What x should I be willing to pay for the right to get either a or b with equal odds?)
1
3
954
18 Feb 2024
(OED's earliest citation, de Moivre's 1718 translation of his own 1711 book, was surely influenced by Huygens? De Moivre used "Expectation"/"Risk" for a pos/neg value. Laplace 1814 gave a modern def of expected value, but called it "espérance mathématique": mathematical hope.)
3
783
12 Jan 2024
ACL is shifting its strategy for protecting anon review. Instead of asking authors to keep quiet about their work during a long "anonymity period," we'll try not to rely on reviewers who actually heard about the work. We hope this plays out better. (1/2)
x.com/aclmeeting/status/1745…
12 Jan 2024

ACL announcement:
"The ACL Executive Committee has voted to significantly change ACL's approach to protecting anonymous peer review. The change is effective immediately. (1/4) #NLPRoc
2
5
72
10,953
12 Jan 2024
I was on the ACL committee that worked on this issue over the past 4-5 months. There were many, many viewpoints and proposals to sort through / debate. No perfect solutions. But amazingly, we got to a consensus on the best🤞way forward. Check out our report, via the link! (2/2)
2
21
1,916
Jason Eisner retweeted

29 Dec 2023
Thrilled to (finally) be able to share our paper:
🐑 Do language models know when they're hallucinating? TL;DR answer: yes!
🔗: arxiv.org/abs/2312.17249, and a🧵
w/ Semantic Machines @MSFTResearch: @ben_vandurme & @adveisner & Chris Kedzie

10
124
743
70,240
3 Oct 2023
If you can break your AI problem down, an LLM is the 3D printer that can quickly create modules for your subtasks. No module should bear too much load, as they're all made of cheap plastic. But a 3D printer has countless uses. (Our previous 3D printer was MTurk.)

1
8
46
4,824
Jason Eisner retweeted

13 Sep 2023
Dear ACL community, ACL is considering multiple proposals to change its anonymity period policy. It seeks immediate feedback from the community about the proposed changes. Please add your voice until Friday, September 22nd (AOE): aclweb.org/portal/content/su… #NLProc
5
192
271
115,938
4 Aug 2023
Read this whole thread, and apply to join us!
4 Aug 2023

@JohnsHopkins Engineering @HopkinsEngineer is making a massive investment in AI. The plan is so ambitious and unique that it’s worth breaking down the announcement in detail.
This will transform the landscape of engineering research and education. 🧵
hub.jhu.edu/2023/08/03/johns…
3
27
9,307
Jason Eisner retweeted

17 Jul 2023
🧵 A recap of JHU CS at #ACL2023!
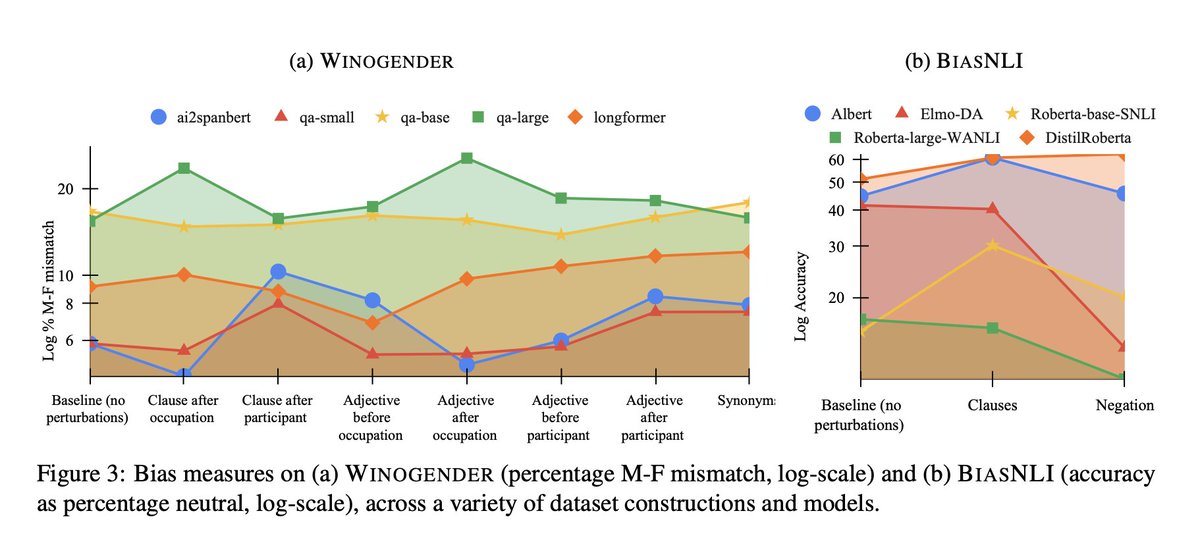
(1/10) Congrats to @DanielKhashabi & team for their Outstanding Paper Award for "The Tail the Wagging the Dog," an investigation into benchmarking social bias in datasets. Read more here: arxiv.org/pdf/2210.10040.pdf
1
9
22
7,022
12 Jul 2023
If you're looking for a PhD or faculty spot in #nlproc, I'd be happy to answer your questions about Johns Hopkins, a global top-10 university that has long had one of the largest NLP groups (clsp.jhu.edu/faculty/) and is growing fast in AI. See below for where to meet today.
2
7
48
7,275
12 Jul 2023
I'm at #ACL2023 all week. During the 3-3:30 coffee break today (Wed), I'll be hanging out outside the Wellington Room (around the corner from the posters and the Bay Room). Here is what I look like today:
11
1,316