
Joined March 2023
- Tweets 132
- Following 57
- Followers 242
- Likes 24
42 Photos and videos















Jun 9
We rebuilt the Agenta Playground from scratch. It is now the main workspace for your AI apps.
Attach evaluators to score outputs as you edit, and load test sets to work on your evals and add test cases without leaving the Playground.
Check out the demo
1
87
May 18
Annotation queues are live in Agenta.
Filter your traces, send them to annotation queues, assign reviewers, and score them with your own schema. Export the reviewed batch as a labeled test set.
Reading traces, finding failures, and turning them into evals is now one workflow.
2
1
78
Mar 13
Webhooks and GitHub automations are live in Agenta!
You can now connect your Github repo (or any webhook) to Agenta so that when a prompt version is saved, you run an automation.
You can see in the demo how to create a PR or each prompt change in Agenta.
9
15
1,790
Feb 27
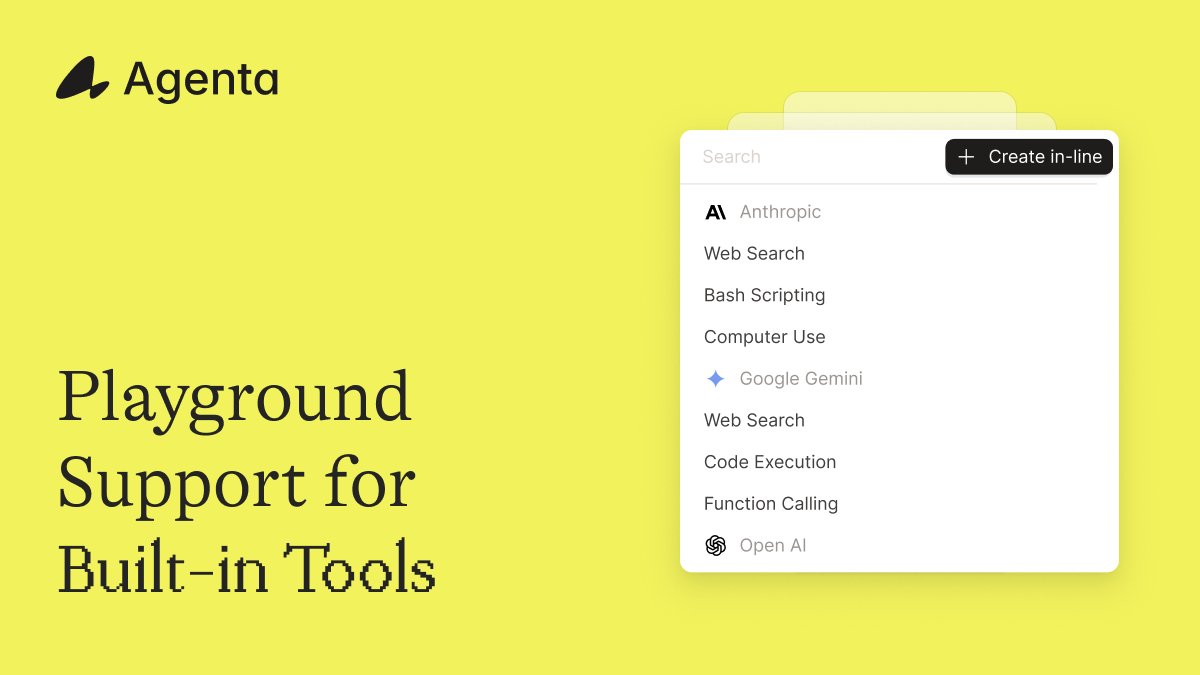
New in Agenta: 150 tool integrations in the Playground. Connect Gmail, Slack, Notion, Google Sheets, GitHub. Authenticate via OAuth, attach actions to prompts, execute tool calls with one click.
3
3
288
Feb 25
New in Agenta: AI prompt refinement in the Playground.
Click the wand icon, describe what you want to change, get a refined prompt back. Iterative. Diff view. Editable before applying.
2
4
190
Feb 17
Agenta has new enterprise features: multi-org support, SSO with any OIDC provider, domain verification with auto-join, and a US region.
1
1
103
Feb 4
Folders for prompts are live in Agenta. Create folders, drag prompts between them, share folder URLs.
1
1
1
95
Jan 20
We have added test set versioning in Agenta:
→ Every edit creates a new version
→ Evaluations link now to specific versions
This mean you can now compare results knowing test data didn't change
Plus: we've rebuilt the UI to handle 100K rows
agenta.ai/docs/changelog/tes…
1
240
Jan 14
Three Playground improvements in Agenta:
- See provider costs per million tokens in the model dropdown
- Run evaluations directly without leaving the Playground
- Collapse test cases when working with large test sets
1
1
91
Jan 9
We just shipped Chat Sessions in Agenta.
You can now group traces from multi-turn conversations together. All traces with the same session ID are automatically grouped.
See complete conversation flows with cost, latency, and token metrics per session.
1
1
1
179
16 Dec 2025
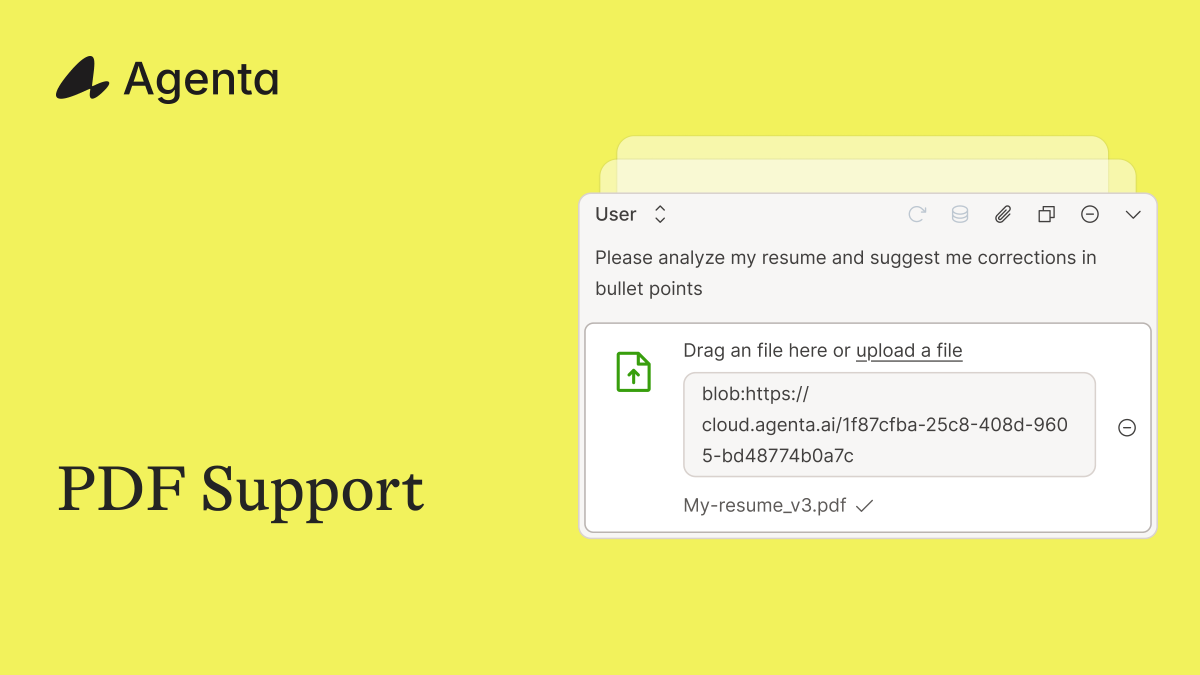
We just shipped PDF support in Agenta 🎉
Attach PDFs to chat prompts in the playground. Works with OpenAI, Gemini, and Claude.
PDFs work in evaluations and observability too. You can now systematically test document processing apps like invoice analysis or contract review.
1
2
110
15 Dec 2025
No one reads docs anymore.
Sad but true. Most docs are now read by agents.
Over the weekend, we built a doc MCP service for Agenta.
Now you can feed all Agenta context to your agent (Cursor, Claude) and ask it to set up prompt management, instrumentation, or evals.
Links 👇
1
1
2
96