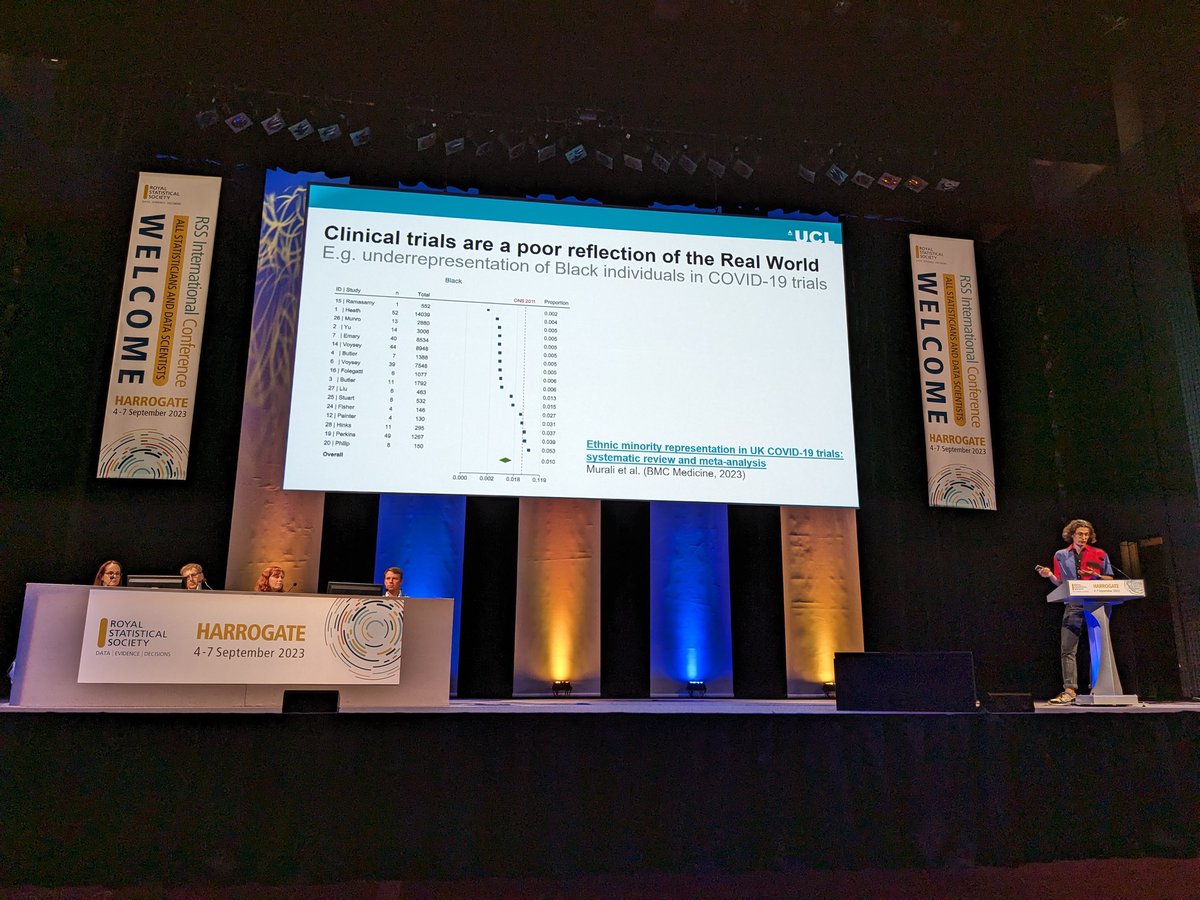
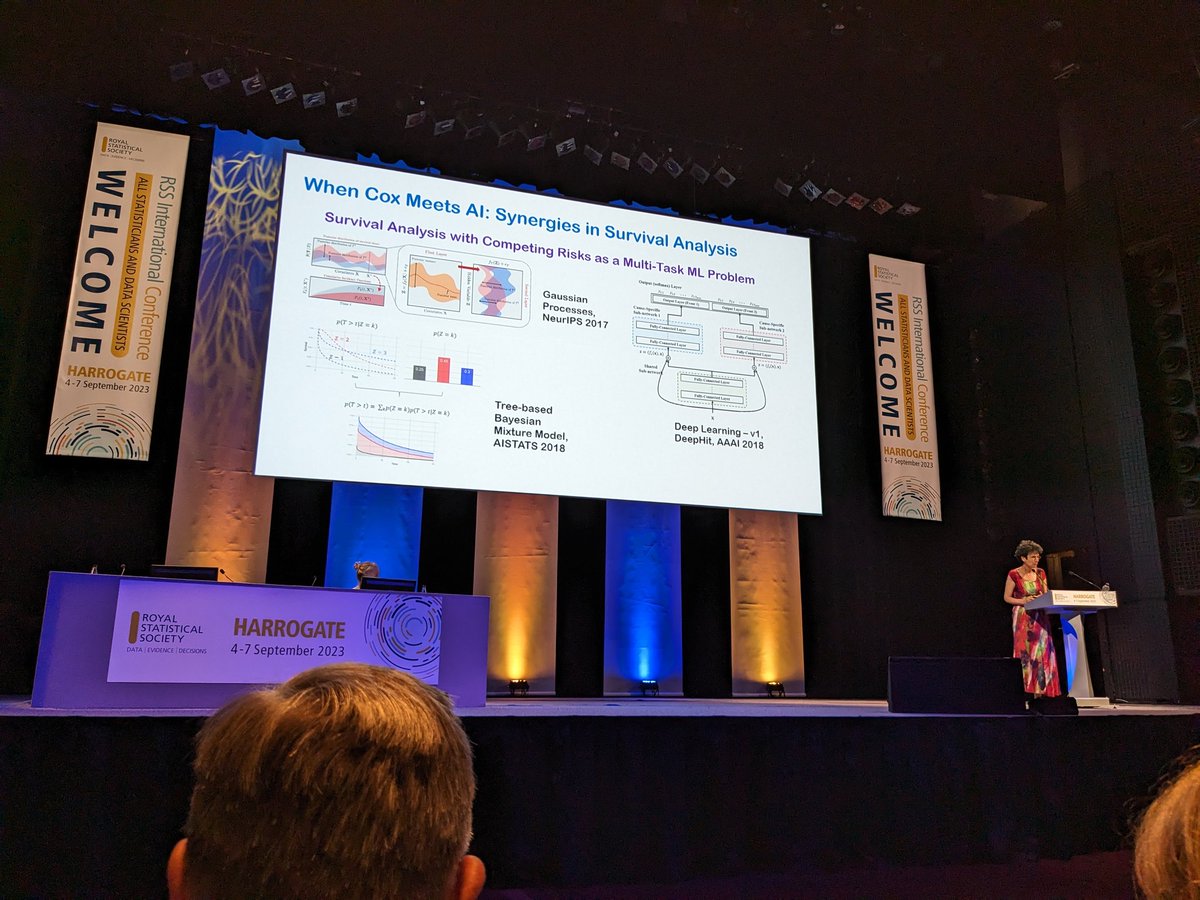
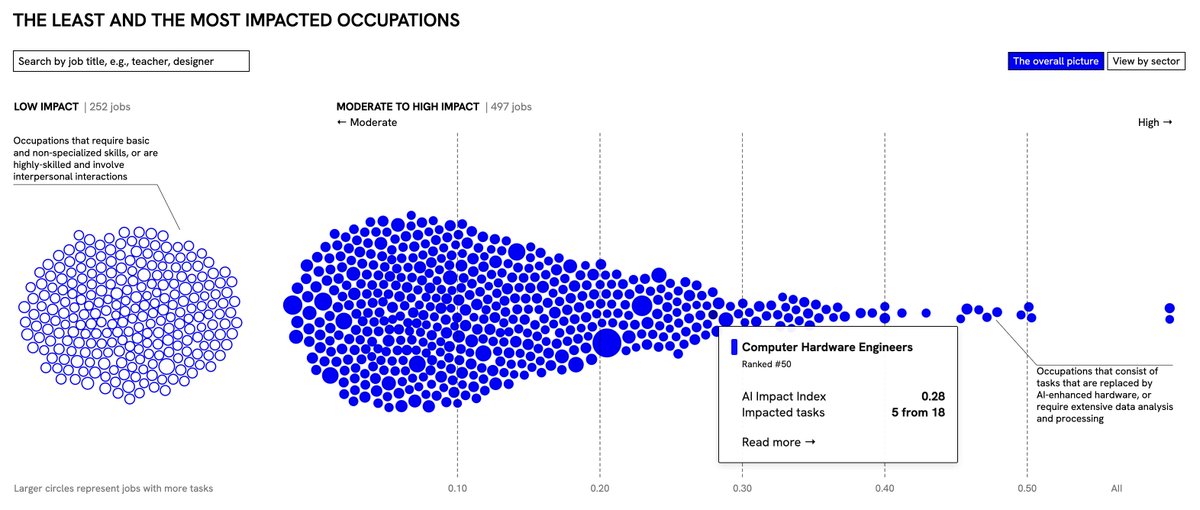
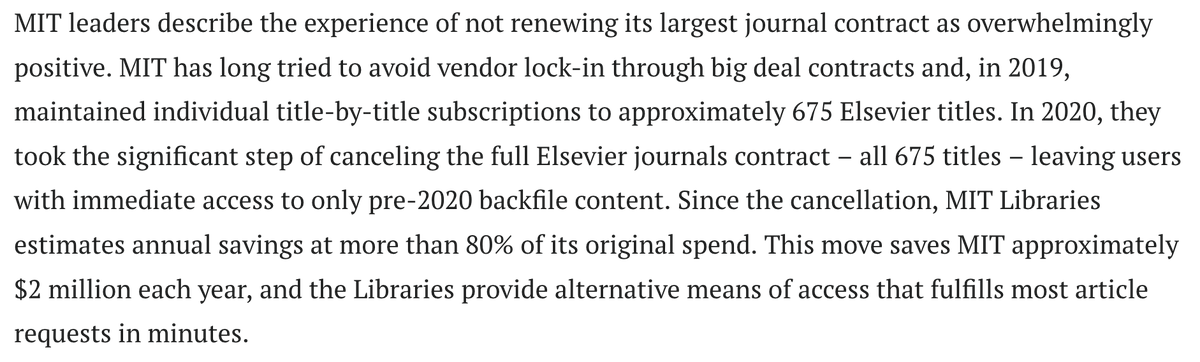
# explaining llm.c in layman terms
Training Large Language Models (LLMs), like ChatGPT, involves a large amount of code and complexity.
For example, a typical LLM training project might use the PyTorch deep learning library. PyTorch is quite complex because it implements a very general Tensor abstraction (a way to arrange and manipulate arrays of numbers that hold the parameters and activations of the neural network), a very general Autograd engine for backpropagation (the algorithm that trains the neural network parameters), and a large collection of deep learning layers you may wish to use in your neural network. The PyTorch project is 3,327,184 lines of code in 11,449 files.
On top of that, PyTorch is written in Python, which is itself a very high-level language. You have to run the Python interpreter to translate your training code into low-level computer instructions. For example the cPython project that does this translation is 2,437,955 lines of code across 4,306 files.
I am deleting all of this complexity and boiling the LLM training down to its bare essentials, speaking directly to the computer in a very low-level language (C), and with no other library dependencies. The only abstraction below this is the assembly code itself. I think people find it surprising that, by comparison to the above, training an LLM like GPT-2 is actually only a ~1000 lines of code in C in a single file. I am achieving this compression by implementing the neural network training algorithm for GPT-2 directly in C. This is difficult because you have to understand the training algorithm in detail, be able to derive all the forward and backward pass of backpropagation for all the layers, and implement all the array indexing calculations very carefully because you don’t have the PyTorch tensor abstraction available. So it’s a very brittle thing to arrange, but once you do, and you verify the correctness by checking agains PyTorch, you’re left with something very simple, small and imo quite beautiful.
Okay so why don’t people do this all the time?
Number 1: you are giving up a large amount of flexibility. If you want to change your neural network around, in PyTorch you’d be changing maybe one line of code. In llm.c, the change would most likely touch a lot more code, may be a lot more difficult, and require more expertise. E.g. if it’s a new operation, you may have to do some calculus, and write both its forward pass and backward pass for backpropagation, and make sure it is mathematically correct.
Number 2: you are giving up speed, at least initially. There is no fully free lunch - you shouldn’t expect state of the art speed in just 1,000 lines. PyTorch does a lot of work in the background to make sure that the neural network is very efficient. Not only do all the Tensor operations very carefully call the most efficient CUDA kernels, but also there is for example torch.compile, which further analyzes and optimizes your neural network and how it could run on your computer most efficiently. Now, in principle, llm.c should be able to call all the same kernels and do it directly. But this requires some more work and attention, and just like in (1), if you change anything about your neural network or the computer you’re running on, you may have to call different kernels, with different parameters, and you may have to make more changes manually.
So TLDR: llm.c is a direct implementation of training GPT-2. This implementation turns out to be surprisingly short. No other neural network is supported, only GPT-2, and if you want to change anything about the network, it requires expertise. Luckily, all state of the art LLMs are actually not a very large departure from GPT-2 at all, so this is not as strong of a constraint as you might think. And llm.c has to be additionally tuned and refined, but in principle I think it should be able to almost match (or even outperform, because we get rid of all the overhead?) PyTorch, with not too much more code than where it is today, for most modern LLMs.
And why I am working on it? Because it’s fun. It’s also educational, because those 1,000 lines of very simple C are all that is needed, nothing else. It's just a few arrays of numbers and some simple math operations over their elements like and *. And it might even turn out to be practically useful with some more work that is ongoing.