
Joined April 2023
- Tweets 7,196
- Following 4,001
- Followers 12,631
- Likes 1,727
368 Photos and videos


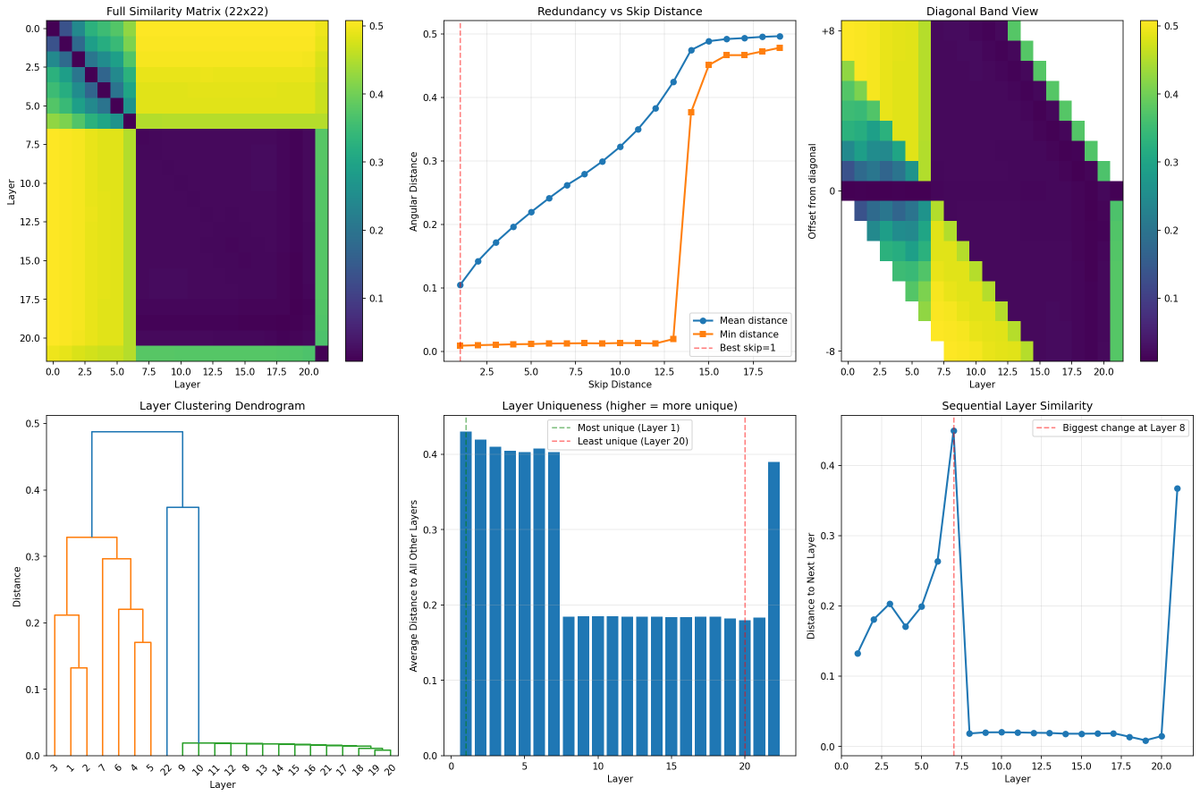







Pinned Tweet
Enormous, imo.
Mar 5

New lecture drop 🎓
In our latest "Learning from Bio to AI" session, Andrew Coward explores Procedural Memory—how the brain learns skills and sequences.
Join us tomorrow 7pm EST for a live Q&A on X Spaces to dig deeper.
🎥 Watch now
6
4
12
2,249
Alignment Lab AI retweeted

Mar 24
Meet the Founder
Rachel St. Clair spent years solving a problem most AI teams live with daily but rarely name: the data-compute lock-in that makes building AI slow, expensive, and inaccessible.
Her path here wasn't linear. PhD in Complex Systems and Brain Sciences at FAU. Postdoc at the Center for Future Mind. Computer vision systems for the Department of Homeland Security. Innovation Lab Director managing 25 researchers. 20 peer-reviewed papers. Work spanning compressed sensing networks, GANs, quantum ML, and bio-inspired architectures.
But the throughline across all of it: the belief that AI's biggest bottleneck isn't intelligence. It's infrastructure.
She founded Servamind to fix that at the architecture level — not with another tool, but with a new standard.
The .serva standard.
Free 1TB beta launch → coming soon!
servamind.com
2
3
11
636
Alignment Lab AI retweeted
Mar 26
Meet our CTO. The person who helped us figure out how to hyperscale our stack.
Austin Cook (@alignment_lab ) currently serves on the Board of Directors of the Active Inference Institute and has spent the majority of his career contributing to open-source AI, focusing on Optimization and Representation research. Those open-sourced contributions have been adopted across the industry from LAION through Intel to Nvidia as key milestones for state of the art openly accessible AI
His take on what we're building: "Every model, every framework, every hardware target, they've all been operating on incompatible data dialects. .serva is the universal language they've been missing."
servamind.com
3
6
614
Alignment Lab AI retweeted
Mar 26
Great work from GoogleResearch on TurboQuant. Strong results — 3-bit KV cache quantization, 8× attention speedup, zero accuracy loss. Solid theoretical foundations.
Worth noting the distinction: quantization optimizes what happens inside the model. .serva operates at the data layer — before the model ever sees the input.
.serva is universal and lossless. When downstream tasks are unknown — which they often are in general AI pipelines — you cannot know in advance what information will matter. We preserve everything and defer relevance to the learning system.
We're also operating at a different layer entirely: ~44× speedup at the data layer in fine-tuning. We’ve built across any model, at any stage — pretraining, fine-tuning, inference — with no retraining required.
The efficiency stack is being built from multiple directions at once. That's a good sign for the field.
3
5
683
Alignment Lab AI retweeted
Mar 26
Meet the researcher who designed the foundation ServaEncode and Chimera from the ground up.
@PeterSutorJr is a PhD candidate in Computer Science at University of Maryland — one of the world's leading experts in Hyperdimensional Computing, with 7 peer-reviewed papers including a publication in Science Magazine.
He worked with the Army Research Laboratory under an ORAU Fellowship, collaborating on Hyperdimensional Computing and Vector Symbolic Architectures. His thesis is built on the same theoretical foundations that power .serva.
His take: "I joined Servamind to make Hyperdimensional Computing the lifeblood of modern AI — to fully capitalize on efficiencies that classical machine learning cannot take advantage of."
That's not a vision statement. It's already in the benchmarks: 30–374× energy efficiency. 68× compute payload reduction. Same accuracy.
servamind.com
2
2
595
Alignment Lab AI retweeted
Mar 27
Meet the engineer who takes our research from theory to production.
@VictorCavero has spent his career doing one thing really well: making complex systems actually work at scale. Embedded systems. IoT. Automotive. Military R&D. Combat-critical systems design.
Before Servamind, he took a compression algorithm from research-stage into a production-grade C implementation — from scratch. That's exactly what we needed someone to do with .serva.
At Servamind he owns the architecture design of our core technology — responsible for turning the encoding and compute engine into infrastructure that works in the real world, on real hardware.
His take: "Obsessed with making things more efficient — there's still so much to build and explore, but better technology shouldn't come at the planet's expense."
That's the Servamind ethos in one sentence.
servamind.com
3
5
517
Alignment Lab AI retweeted

Mar 20
Learning to write kernels might be the highest-ROI activity for displaced SWEs:
→ prereq: reasonable engineering ablity
→ six to twelve months of study
→ millions of dollars, mark zuckerberg showing up at your house to hire you, etc.
i wish this were an exaggeration
40
62
1,862
124,222
Alignment Lab AI retweeted

Mar 14
Need more Claude, need more Codex, need more OpenCode or Pi? Gemini, Kimi? You got this
3
1
13
3,087
Alignment Lab AI retweeted

Mar 14
so it turns out
the fast inv sqrt trick from Quake III Arena, (according to the internet from either or both of Greg Walsh and @ID_AA_Carmack )
entirely critical for some work im doing building linear models out of pretrained nonlinear ones.
rmsnorm and softmax both would have gone unsolved if not for it.
the unlock here is extremely op, im stoked
2
3
609
Alignment Lab AI retweeted

Mar 10
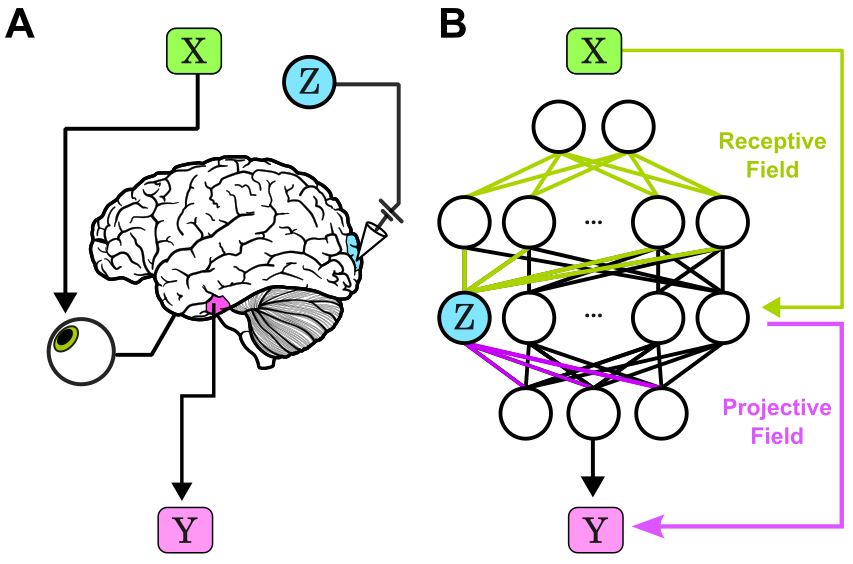
Trying to interpret how a neural-network does what it does? Activations tell you if a neuron responded. Contributions tell you if a neuron mattered!
New paper from myself, @Zaki_Alaoui1, @sunnyliu1220 , @SuryaGanguli, and Steve Baccus: arxiv.org/abs/2603.06557
1
25
113
27,852
Alignment Lab AI retweeted
Mar 6
Procedural Memory -- Lessons from Bio to AI x.com/i/spaces/1MJgNgVjvbPGL
1
2
4
258
Alignment Lab AI retweeted
Mar 5
New lecture drop 🎓
In our latest "Learning from Bio to AI" session, Andrew Coward explores Procedural Memory—how the brain learns skills and sequences.
Join us tomorrow 7pm EST for a live Q&A on X Spaces to dig deeper.
🎥 Watch now
2
5
2,821
Alignment Lab AI retweeted
Feb 26
Your brain doesn't retrieve memories. It reconstructs them — partially, emotionally, from fragments. No AI system does this. That gap is the whole problem.Gave a keynote today on Software, Memory & Language at @ekkolapto.
Listen to our founders talk today at
luma.com/bioprompting
1
3
8
559
Alignment Lab AI retweeted
Feb 11
Building multimodal AI? You know the pain:
Separate pipelines for images, text, audio
Format conversions eating 80% of dev time
Data locked to single model architectures
Serva Encoder solves this. One universal format (.serva) for all modalities. Any model. No retraining.
More energy efficient. Zero accuracy loss.
Sign up for our beta
servamind.com/join-the-beta
1
2
3
324
Alignment Lab AI retweeted
Feb 17
🚀 Serva Encoder is launching in beta soon and we're offering 1TB free encoding to early users.
One universal format for all your multimodal data. Images, text, audio, sensor streams. Encode once, use anywhere.
No more pipeline chaos. No more format lock-in.
Claim your 1TB → servamind.com/join-the-beta
2
3
312
Alignment Lab AI retweeted
join! dont miss it! Andrew Coward and @servamind new secrets about neuroscience, AI, and the shared index that spawned some crazy tech
Feb 6
Types of Memory -- Lessons from Bio to AI x.com/i/spaces/1lPJqvObwWmxb
1
3
556
Alignment Lab AI retweeted
x.com/servamind/status/20199…
Brains, Bytes, and brand new technological frontiers, im in here, definitely join
Feb 5
Watch Andrew Coward Discuss Types of Memory in our Lessons from Biology for AI series before our X space tomorrow at 4pm PST!
1
6
545
Alignment Lab AI retweeted
Feb 5
Watch Andrew Coward Discuss Types of Memory in our Lessons from Biology for AI series before our X space tomorrow at 4pm PST!
1
1
288