
Joined October 2023
- Tweets 33
- Following 130
- Followers 84
- Likes 92
7 Photos and videos





Apr 22
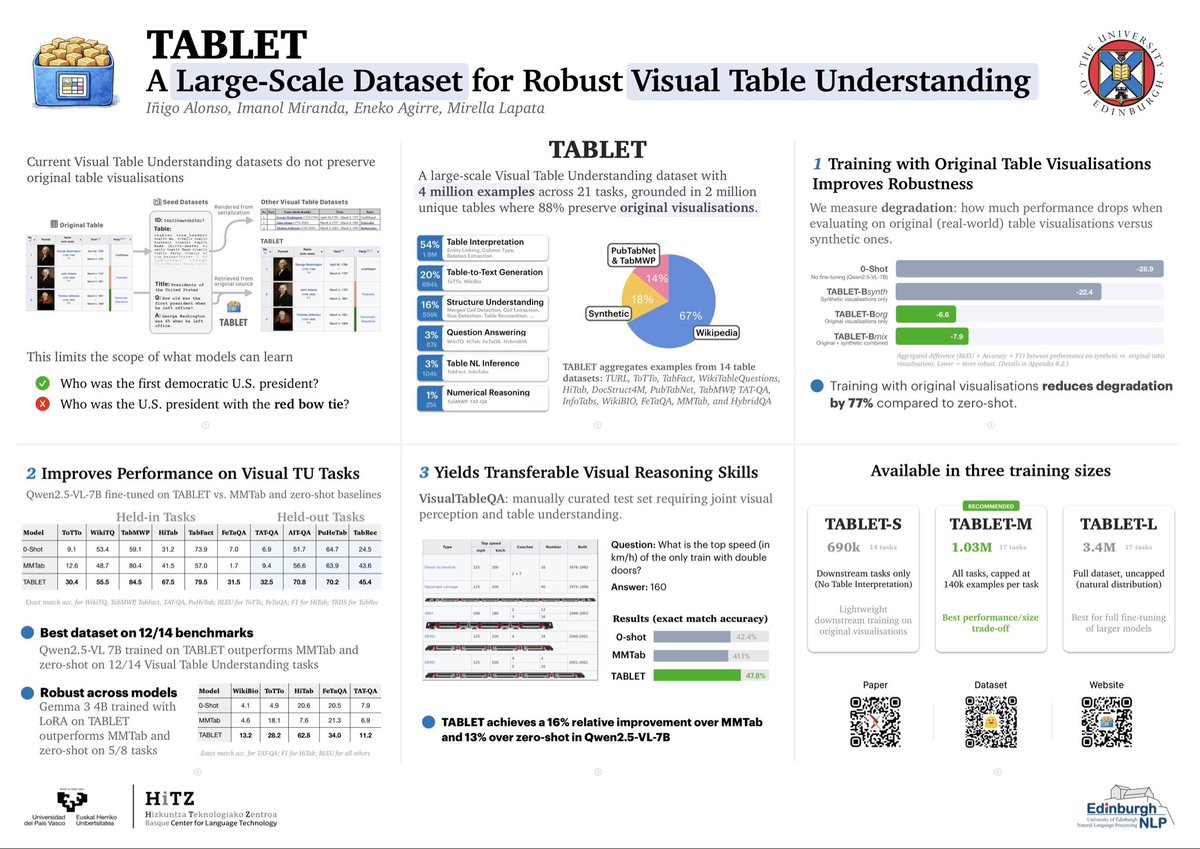
I’ll be presenting TABLET at #ICLR2026 this week! Our 4 million example Visual Table Understanding dataset with original table visualisations! Come and say hi! :D We’ll have actual Scottish tablets 👀
See you all on Friday at 7:15 PM Pavilion 4 P4-#3606
alonsoapp.me/tablet/
1
6
11
480
Apr 22
Built alongside the wonderful people at @EdinburghNLP and @hitz_center
Read more about our paper here:
arxiv.org/abs/2509.21205
1
60
Iñigo Alonso retweeted

17 Dec 2025
Reasoning models are powerful, but they burn thousands of tokens on potentially wrong interpretations for ambiguous requests!
👉 We teach models to think about intent first and provide all interpretations and answers in a single response via RL with dual reward.
🧵1/6

1
12
35
2,732
Iñigo Alonso retweeted

31 Oct 2025
Excited to share my first work as a PhD student at @EdinburghNLP that I will be presenting at EMNLP!
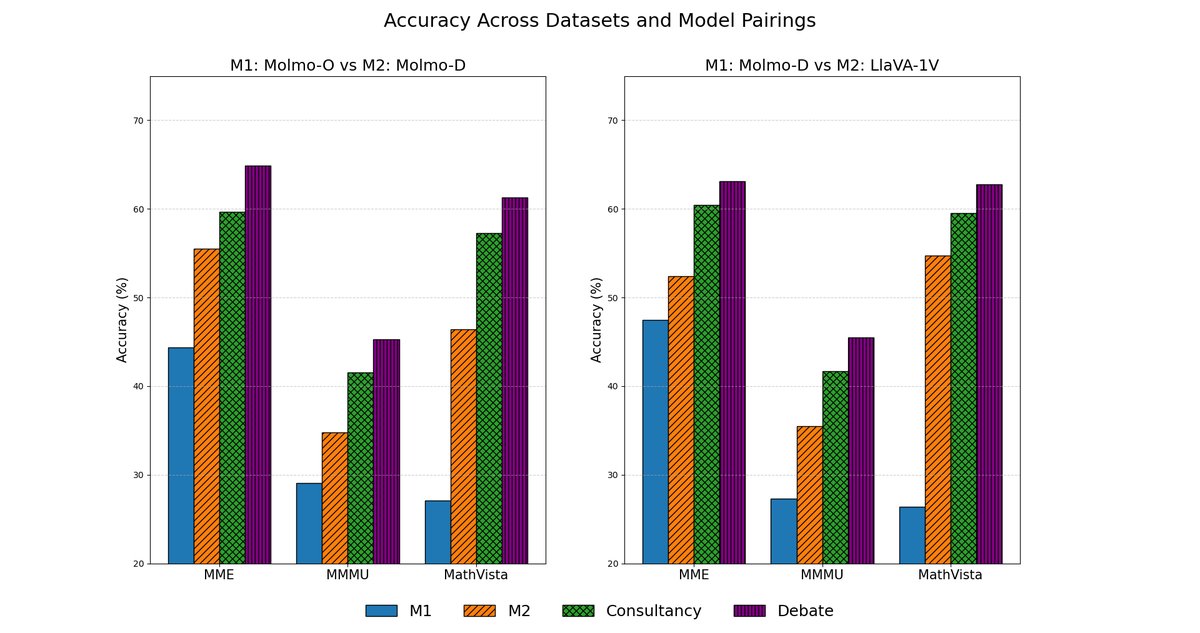
RQ1: Can we achieve scalable oversight across modalities via debate?
Yes! We show that debating VLMs lead to better model quality of answers for reasoning tasks.
1
7
14
1,313
Iñigo Alonso retweeted

8 Nov 2024
Atzo eta gaur euskarazko ereduen artean onena aukeratzen utzi diegu #IEB2024|ko parte hartzaileei. Mila esker deneri!!
Sistema komertzialez gain HiTZ garatzen ari den Latxa 🐑berri txikiena ere probatu dugu, 8B tamainakoa. Llama 3.1-en oinarritzen da.
Eta irabazlea… 🥁
1
15
15
3,729
Iñigo Alonso retweeted

2 Nov 2024
New paper: "What's New in My Data? Novelty Exploration via Contrastive Generation," w/ @iatitov at @EdinburghNLP
arxiv.org/abs/2410.14765
With no access to the data, but only access to the pre-trained and fine-tuned model, we can reveal novel aspects of the fine-tuning dataset.
2
6
26
4,037
Iñigo Alonso retweeted
21 Oct 2024
WE ARE HIRING!!
The HiTZ Center (hitz.eus) at the University of the Basque Country (UPV/EHU) invites applications for several funded research engineering and pre/postdoctoral positions in Natural Language and Speech Processing.
hitz.eus/job-offers
19
19
1,652



Iñigo Alonso retweeted

12 Aug 2024
Happening today at 11, In-Person Poster Session 1 😀
9 Aug 2024

Excited to present StructSum 📊🧠 at #ACL2024 with Andreea Marzoca & Francesco Piccinno @nopper!
Come and say hi 🤝 if you'd like to chat about our paper, LLMs for generating structured outputs, or context-heavy NLP tasks. See you there!✨✨
arxiv.org/abs/2401.06837
1
3
16
1,102
Iñigo Alonso retweeted

11 Aug 2024
I will be presenting our work tomorrow at the Poster Session at 16:00 @ #ACL2024NLP
Feel free to come by and chat!
6 Aug 2024

New @hitz_zentroa paper! Accepted @aclmeeting 2024 on "Argument Mining in Data Scarce Settings: Cross-lingual Transfer and Few-shot Techniques"; joint work with @ragerri and @jiporanm #ACL2024NLP
Paper: arxiv.org/abs/2407.03748
Data code and models: github.com/anaryegen/few_sho…
1
4
10
860
Iñigo Alonso retweeted

12 Aug 2024
Today I will be presenting Latxa at @aclmeeting In-Person Poster Session 3 at 16:00-17:30. Come if you want to hear about our work. I will be giving out Latxa stickers too! #ACL2024NLP

10 Apr 2024

In our new paper, we introduce Latxa, a family of LLMs for Basque from 7 to 70B parameters that outperform open models and GPT3.5.
Models and datasets @huggingface hf.co/collections/HiTZ/latxa…
Code: github.com/hitz-zentroa/latx…
Blog: hitz.eus/en/node/343
Paper: arxiv.org/abs/2403.20266

10
27
3,533
11 Aug 2024
Hey! I will be presenting our work, PixT3: Pixel-based Table-To-Text Generation, tomorrow at Poster Session 1 at 11:00AM during #ACL2024NLP Come and say hi! :D
4 Jun 2024

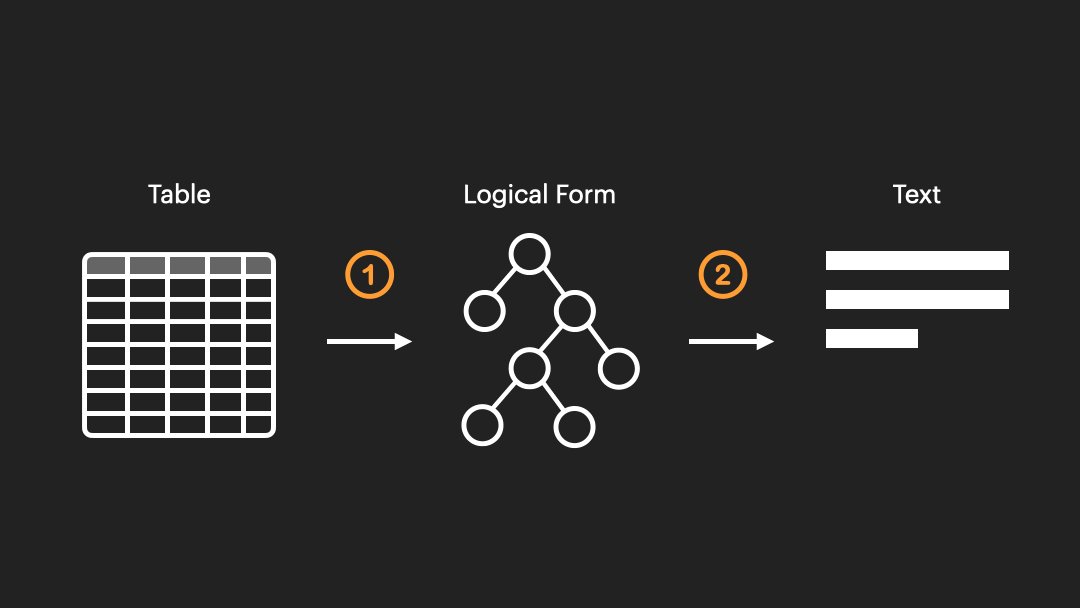
Reimagining table representation! In our new #ACL2024NLP paper we introduce PixT3: a family of image-based Table-to-Text Generation models that scale better at generating text from large tables, outperforming traditional text-based baselines.
arxiv.org/abs/2311.09808
4
22
1,610
7 Aug 2024
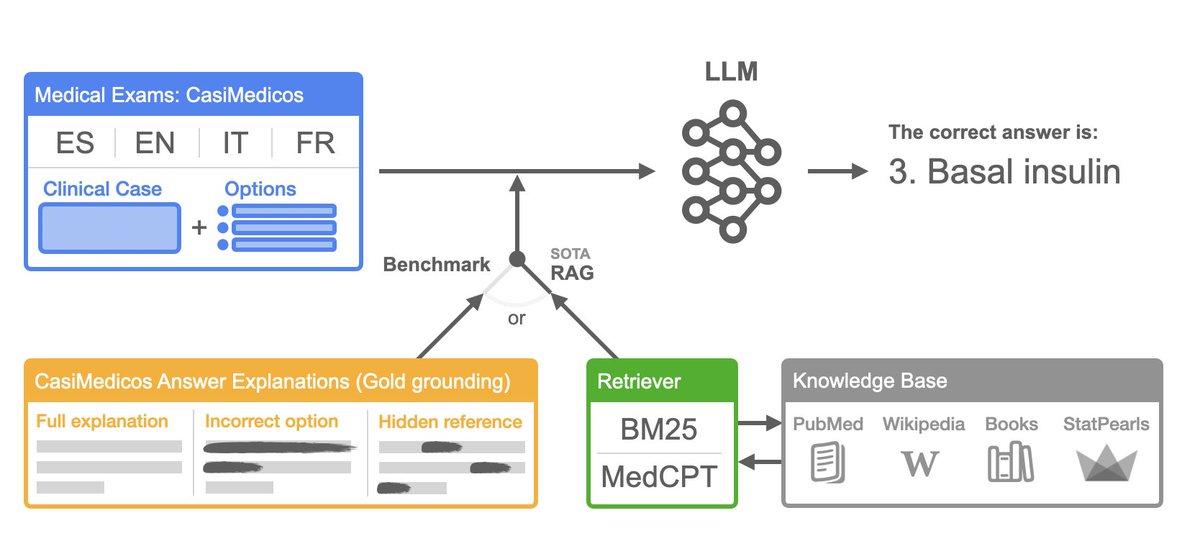
New @hitz_zentroa paper! "MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering"; w/ @ragerri and @jiporanm in Artificial Intelligence in Medicine (Elsevier)
Paper: doi.org/10.1016/j.artmed.202…
Resources: huggingface.co/datasets/HiTZ…
2
7
15
687
7 Aug 2024
Highlights: (i) MedExpQA: the first multilingual benchmark for MedicalQA including gold reference explanations; (ii) Exhaustive comparison of gold reference explanations with respect to automatically retrieved medical knowledge using state-of-the-art RAG techniques
1
1
2
180
7 Aug 2024
Conclusions: (i) Overall performance of LLMs with or without RAG still has large room for improvement; (ii) Performance for non-English languages substantially lower - stresses urgent need of advancing Medical QA in languages different to English
1
1
168
Iñigo Alonso retweeted
24 Jun 2024
Come and work with us!
24 Jun 2024

WE ARE HIRING!! 🥳The HiTZ Center for Language Technology (hitz.eus) at the University of the Basque Country (UPV/EHU) invites applications for predoctoral and postdoctoral positions in Natural Language and Speech Processing. CHECK IT HERE!!
hitz.eus/job-offers
15
8
1,064
Iñigo Alonso retweeted

3 Jun 2024
LLMs are the de facto building block in recent multimodal models. Yet, it is still unclear why text-only models can generalize to multimodal inputs!
We investigate why, and provide insights with practical implications on performance, efficiency and safety problems. (1/10)

2
32
137
16,206
4 Jun 2024
Reimagining table representation! In our new #ACL2024NLP paper we introduce PixT3: a family of image-based Table-to-Text Generation models that scale better at generating text from large tables, outperforming traditional text-based baselines.
arxiv.org/abs/2311.09808
1
9
21
4,775
4 Jun 2024
[3/4] Our approach also enables PixT3 to produce significantly more accurate texts according to human evaluation.
1
1
162
4 Jun 2024
[4/4] Made alongside @eagirre and @mlapata at @EdinburghNLP and @Hitz_zentroa
Check out our code, models, and datasets:
github.com/AlonsoApp/PixT3
Paper: arxiv.org/abs/2311.09808
1
125