
Set up your winning prediction market strategy in under 5 minutes. Official @polymarket partner
Joined March 2024
- Tweets 312
- Following 7
- Followers 5,553
- Likes 1,062
43 Photos and videos












Pinned Tweet

Feb 5
Escape the permanent underclass.
Introducing Alpha Whale, the best way to trade on Polymarket.
RT Comment ALPHAWHALE for a chance to win $1,000
alphawhale.trade
107
57
195
64,313

Everyone's scrambling to find a moat in the new AI world.
I read Chamath's 138 page report to find what that means at every layer of the stack:

3
3
11
1,981
Multi Agents are FINALLY working.
Everyone thinks multi-agent = throw 10 AIs at a problem and let them cook in parallel.
That doesn't work in pratice.
When multiple agents write code simultaneously, they make conflicting decisions — different styles, different edge case handling. It's chaos.
Cognition and Anthropic independently discovered the same architecture. One agent writes. The others contribute intelligence.
Anthropic calls it orchestrator-worker. Cognition calls it "single-threaded writes with multi-agent intelligence."
Here are the 3 patterns that actually work:
1. The Self-Review Loop Devin reviews its own code with a separate clean-context agent.
Why? Context rot — models make worse decisions at longer context lengths and The fresh reviewer catches what the coder can't see.
Result: 2 bugs found per PR, 58% of which are severe.
2. Smart Friend
Two frontier models (say Opus 4.7 and GPT 5.5) working together. Different models excel at different subtasks — some debug better, some reason visually better. The unlock is routing to each model's strengths.
I personally use Codex to review code made by Claude Code and it catches critical issues constantly.
3. The Research Swarm Anthropic's version: one lead researcher (Opus) spawns parallel search agents (Sonnet) that fan out, gather info, and report back. these workers are read-only
90% improvement over single-agent. 15x more tokens but handles parallel research beautifully.
The pattern everyone's converging on isn't "more agents." It's the right agents doing the right jobs, with one clear decision-maker.
If you're interested in the full research, follow comment AGENT and i'll send you the links :)
5
2
11
896
Alpha Whale retweeted

Apr 16
We've teamed up with @alphawhaletrade — an official @polymarket partner — for a special campaign.
Copy the smartest traders in 2 clicks and get rewarded for it.
✅ 0.5x rewards boost
🎰 $500 raffle for completed predictions
Check the Rewards tab to get started 👇
lootgo.app/app

10
8
56
6,023
Alpha Whale retweeted

Apr 14
you're not gonna make it to whale if you keep losing money on fees
@alphawhaletrade has a tier system where the more you trade the lower your fees and the higher your cashback
if you want to try it use my link so i can be a whale one day
9
2
47
1,635
Alpha Whale retweeted
This Friday. We're drawing ALL RAFLI winners LIVE 🔥
5 raffles. Real winners picked by code, announced in real time.
🏝️ 7-Night Resort Stay from @staynexcom
🃏 Kabuto PSA 10 1st Edition
🐋 $500 in Prediction Market Credits from @alphawhaletrade @0xAndros
🥇 $500 in Gold
🥈 $500 in Silver
📅 April 10 · 3PM CEST / 9AM EST
If you haven't entered raffles yet, this is your window. Once the Space starts, it's too late!
🔗 x.com/i/spaces/1dKrPEMQQdqJX…

242
110
280
3,985
Alpha Whale retweeted
Mar 31
i almost got out of the permanent underclass...
20
3
89
2,577

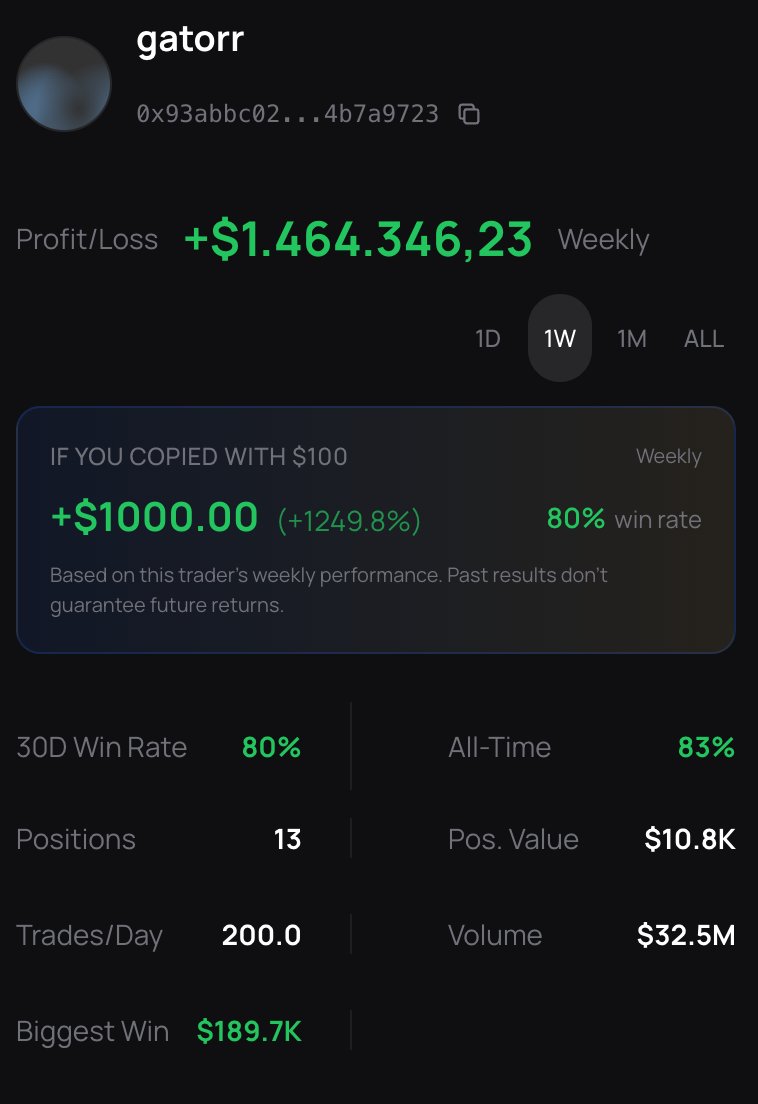
Mira esta locura que encontré en @alphawhaletrade
Este trader ("gatorr") se llevó $1.4 MILLONES en una sola semana.
¿Lo más absurdo de todo? Su tasa de acierto es del 80% en los últimos 30 días, manejando un volumen de $32.5M. Casi no falla.
Si le hubieras hecho copy trading con solo $100 al empezar la semana, ya tendrías un 1249.8% de retorno sin mover un dedo.
Su mayor victoria hasta ahora es de $189.700 Las oportunidades están ahí.
21
4
67
3,442
Alpha Whale retweeted

Mar 25
IT'S TIME 🎰🎉
RAFLI IS OFFICIALLY LIVE.
Five raffles. Open now:
🌴 7-Night Vacation (@staynexcom)
🃏 PSA 10 Kabuto (PSA 10)
📈 $500 Prediction Credits (@alphawhaletrade)
🥇 $500 Gold
🥈 $500 Silver
Buy your ticket. Win something real!
👉 rafli.win
308
174
433
25,525
Alpha Whale retweeted
Mar 23
Here's everything you can WIN when RAFLI launches:
🌴 7-Night Vacation (@staynexcom)
🃏 PSA 10 1st Ed. Kabuto
📈 $500 Prediction Market Credits (@alphawhaletrade)
🥇 $500 Gold
🥈 $500 Silver
Five raffles. 9 winners. Why not you? 👀
Launching March 25 🔥
287
122
314
4,042
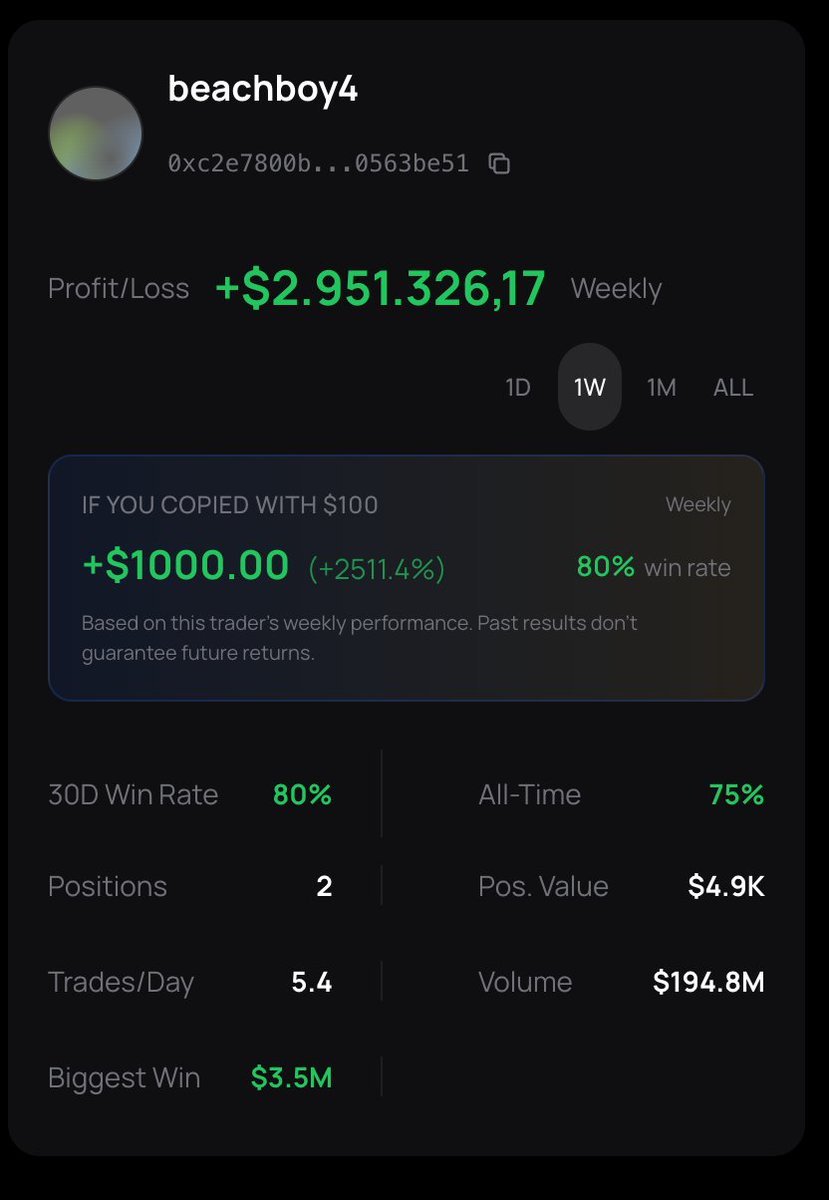
Miren los números de este insider: $2.900.000 de ganancia en una sola semana con un 80% de win rate. Su trade más grande le dejó 3.500.000
Pero el dato que te interesa es este: si hubieras puesto solo $100 a copiar esta cuenta, en 7 días tendrías $1,100( 2511%).
Con @alphawhaletrade no necesitas ser el genio que hace la operación. Solo buscas a las ballenas que ya están haciendo millones y configuras tu cuenta para copiarlas en piloto automático.
Deja que los millonarios trabajen por ti.
24
6
105
7,378
Mar 20
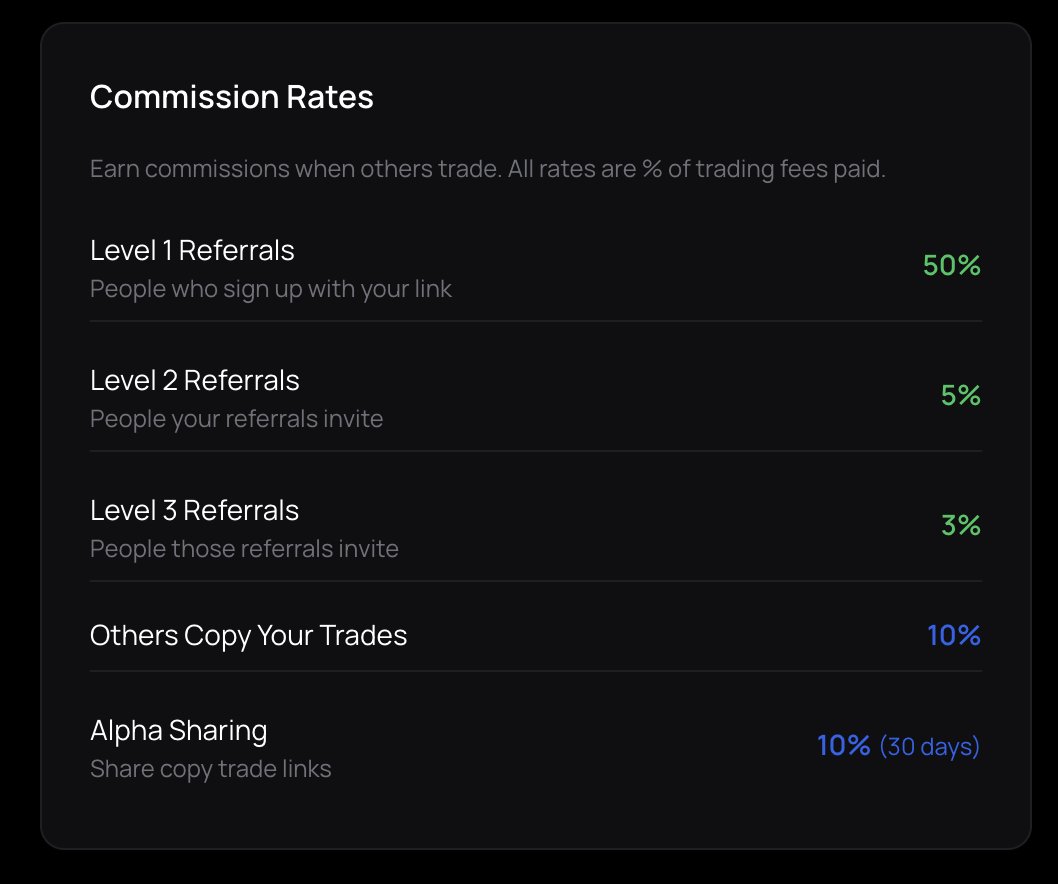
We give 50% referral rates for anyone who shares Alpha Whale.
Our competitors call it crazy. We call it community
2
3
10
508
Alpha Whale retweeted

Mar 18
@alphawhaletrade is going deeper on execution.
Copy trading now gets full attention as the team works to build a system driven by real trader performance.
Bonding is on hold and all positions remain visible in your account.

7
6
11
702
Alpha Whale retweeted
Mar 17
Rafli Prize #4 🤝
We’ve partnered with @alphawhaletrade to bring something a bit different to the raffle 🤫
$500 in Prediction Market Credits 📈
If you’re into markets, narratives, and spotting trends early - this one’s for you!
What would you bet on first? Let us know and win 1 of the 5 EXCLUSIVE access codes 🔥

340
90
292
6,841
Mar 16
bro if only I copied this trader last week I would be up 60% 😭
6
8
16
942
Alpha Whale retweeted

Mar 12
This wallet hasn't lost a single trade in a month
its logic is stupidly genius
99 trades/day
volume $32M
profit $1.4M/week
found it in @alphawhaletrade every trade is the same:
takes a match where mid-tier team
plays at home market puts 55% on win
real stats say 38%
delta 17% he goes NO and waits
getafe, lazio, chelsea, lyon same thing every day
everyone looks for secret indicators
and this guy just subtracts one number from another
8
3
46
2,785
Mar 12
when people raw dog their trades instead of copy trading
10
13
28
2,807
Alpha Whale retweeted
Mar 10
Making money on wars without leaving your room sounds like a netflix plot
but someone is literally doing that
markets on real world events
“will the us strike Iran” - one guy goes in there
with $200k–$400k per position
and week after week pulls out
$221k profit in 7 days
positions on iran trump elections
he’s not an analyst not a journalist not a spy
just someone who sees probabilities
clearer than the whole market
i stumbled on him in @alphawhaletrade
the sim showed 67% in a week on $100
turned on copytrade and got my 67%
while the world argues about what’s next someone already made bank on it
best strategy is not to argue but to bet
9
4
33
1,593
Mar 10
I've doubled my money on @Polymarket this month.
How?
100% through copy trading on Alpha Whale.
I tried 5 different recommended traders, found two that were ripping, and turned off the other 3.
Now I've been seeing consistent increases every week.
Kind of crazy, it's high-performance trading on auto-pilot
12
11
29
3,129