
Cowo/Male | Kotlin Lover | 鞠婧祎 (Ju Jingyi) 💕 | 🇮🇩
Joined October 2021
- Tweets 3,368
- Following 941
- Followers 1,111
- Likes 293,330
573 Photos and videos











Pinned Tweet

16 Jul 2023
✨Semua thread tentang android dan kotlin bisa di lihat disini
1
14
75
17,217
beli raspberry buat run hermes 24 jam worth it gk yh? 😞
1
71
Anap 🔫 | Native Android Dev retweeted

Jun 8

Jun 8

Vibe-coding is just a gambling addiction for SWEs
72
1,783
13,434
565,356


Anap 🔫 | Native Android Dev retweeted

I'm a Malaysian so I can only watch from.the sidelines. The only thing I can say is I hope things go better for you. And please pick a better president in 2029, don't let Prabodoh have a second term.
18
276
3,752
54,841
Anap 🔫 | Native Android Dev retweeted

Jun 4
kalian sedih gak kalo jadi "et al." saat disitasi orang
382
2,060
28,839
709,381
Anap 🔫 | Native Android Dev retweeted

Kalau lo masih bayar API untuk parsing PDF, mungkin lo perlu lihat ini dulu.
Project open-source ini bisa memproses 100 halaman PDF per detik tanpa GPU, tanpa cloud, dan tanpa biaya langganan.
Namanya OpenDataLoader PDF.
Dan semakin gue baca, semakin sulit dipercaya kalau ini gratis.
Kenapa?
✅ Gratis 100%
✅ Jalan di CPU biasa
✅ Tidak butuh GPU
✅ Tidak perlu cloud
✅ Tidak perlu API key
✅ Open-source
Di benchmark, performanya juga bukan kaleng-kaleng:
1️⃣ Dictionary punya akurasi bagus, tapi sekitar 15x lebih lambat.
2️⃣ Marker membutuhkan GPU dan bisa sampai 1000x lebih lambat.
3️⃣ Pymupdf4llm memang cepat, tetapi skor ekstraksi tabelnya hanya sekitar 0.40.
Yang bikin project ini makin menarik adalah siapa yang membuatnya.
OpenDataLoader PDF dikembangkan oleh tim di balik PDF Association dan veraPDF.
Artinya, ini dibuat oleh orang-orang yang membantu menetapkan standar PDF yang dipakai industri selama bertahun-tahun.
Saat ini project tersebut sudah mengumpulkan:
⭐ 8.6K GitHub Stars
📜 Apache 2.0 License
🚫 Tanpa ketergantungan komersial
Kalau lo sedang membangun:
• AI Agents
• RAG Pipelines
• Knowledge Bases
• Document Intelligence Systems
• Local AI Workflows
Project ini layak masuk daftar bookmark.
Repo 👇
github.com/opendataloader-pr…

4
17
61
2,089
Anap 🔫 | Native Android Dev retweeted

Jun 2
Gw kenapa, orang” kenapa, kek gw cuma mau tenang aja susah banget dah. Apa haris mati dulu baru tenang???
4
1
1
276
Anap 🔫 | Native Android Dev retweeted

Jun 1
Boleh lah pilpres 2029 😔
May 31

Kira* apa ya, yg dibisikan ahok ke anis ini. Koq sampe keduanya pada ketawa lepas. Ada yg tahu ?
6
37
539
22,688

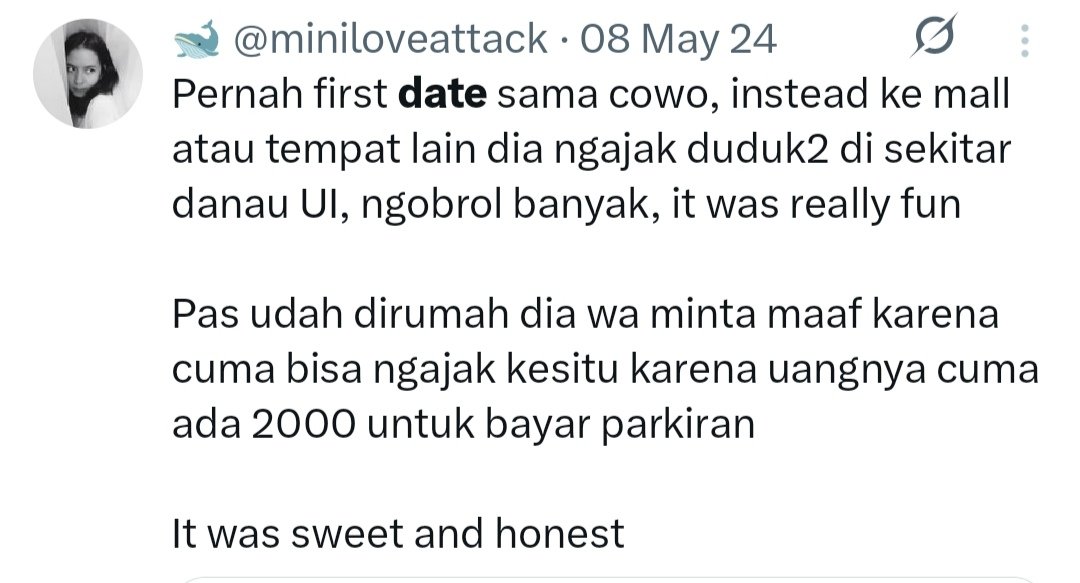
I honestly dont get why some people are hating on this... kalau ada orang yang mau ngobrol sama aku berjamjam without any distraction aku mah seneng ya :// romance is dead omg
"This isnt sweet" mungkin kamu terbiasa melihat act of love sebatas bentuk benda doang??

222
7,321
31,726
4,714,129
Anap 🔫 | Native Android Dev retweeted

May 24
FALLING IN LOVE WITH SOMEONE JUST BCS THEY DO BASIC OR NORMAL THINGS FOR US JG KNP GW TANYA. mngkin itu BASIC buat lu, tapi buat orng yg baru ngerasain HAL BASIC itu dri orng lain gmn? lagian gw bingung kt hrs suka sm orng pas orng tsb ngelakuin apasih ke kt? bangun seribu candi?
73
2,302
14,468
314,869
Anap 🔫 | Native Android Dev retweeted

May 25
Seberapa hebat agent-mu di cybersec? Cobain CTF khusus buat agent, masih BETA testing, quota max 50:
agent-ctf.nuwaira.org/?from=…
9
3
50
11,904
Anap 🔫 | Native Android Dev retweeted

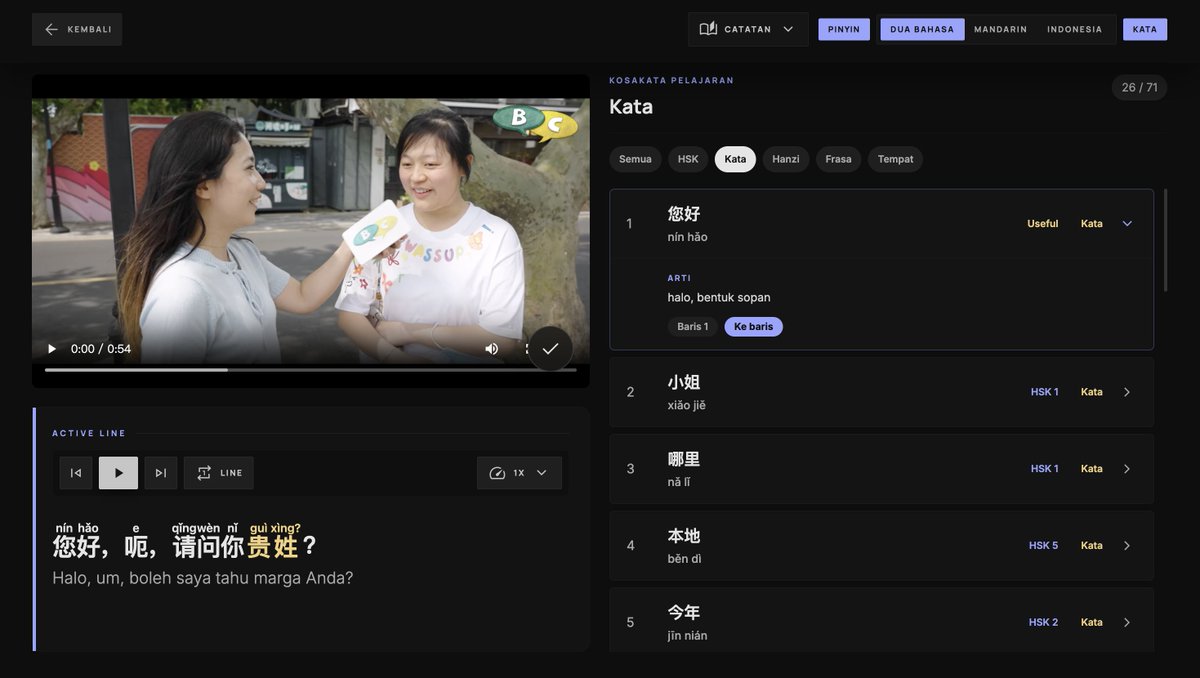
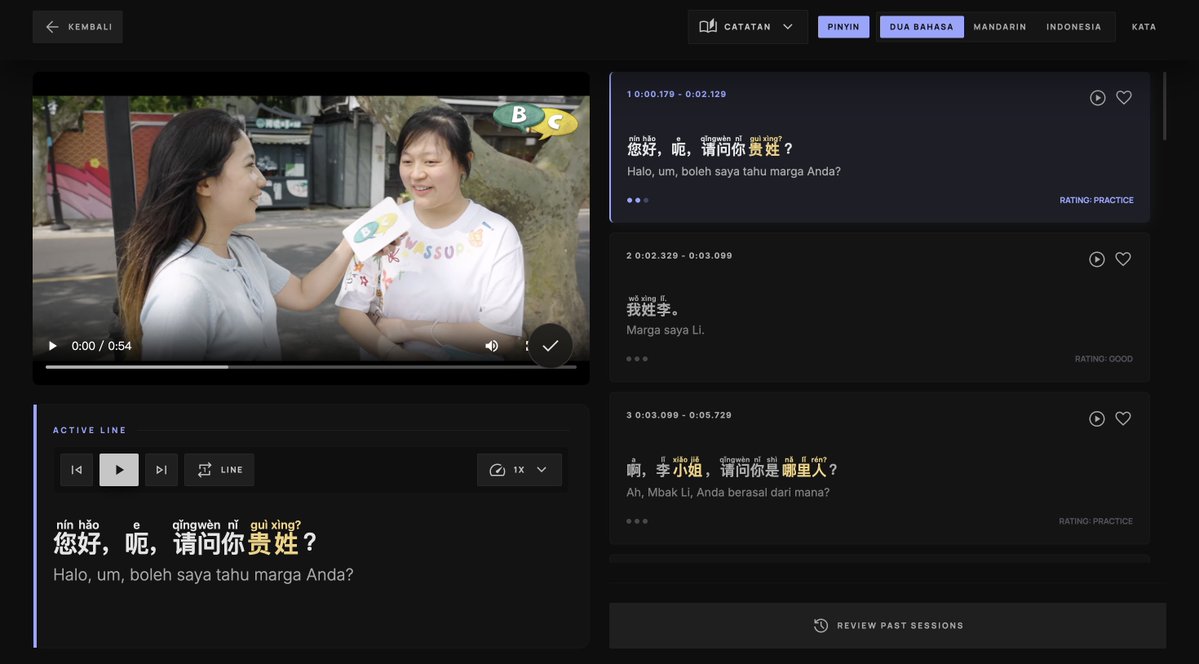
May 24
To: all users
Important Update!🥰🥰🥰
Indonesian subtitles are now available on the platform 🇮🇩
speakcn.com
I really want to thank all the Indonesian users who have been supporting and trying the website recently. Seeing learners from different countries use something I built as a solo student developer honestly means a lot to me.
I’m still improving translations, subtitles, and learning tools step by step — not just for Indonesian, but for other languages as well.
Thank you all for the patience and feedback while the project is still growing ❤️
#langtwt #studytwt #learnmandarin #learnchinese
9
60
206
34,466
Anap 🔫 | Native Android Dev retweeted

May 22
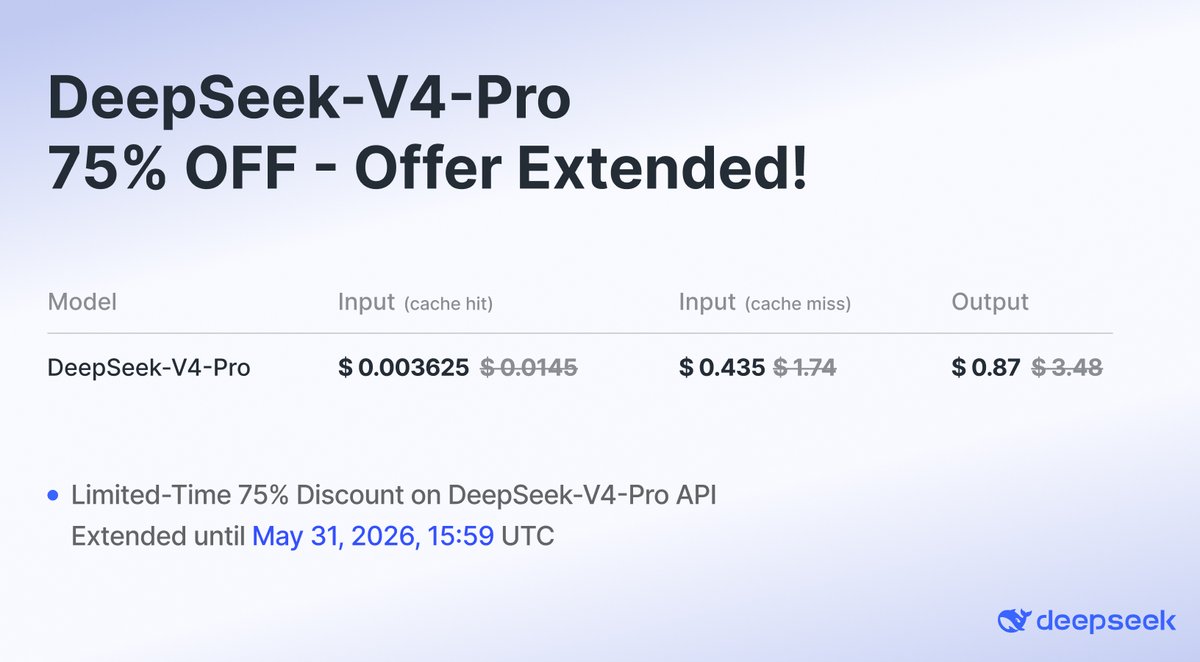
We are making our discount permanent! 🎉
Enjoy building with DeepSeek-V4-Pro and bring your innovative ideas to life! 🚀

Apr 29

The DeepSeek-V4-Pro discount has been extended until May 31, 2026, 15:59 UTC!
1,408
2,772
23,889
6,660,607
Anap 🔫 | Native Android Dev retweeted

May 22
one good girl is worth a thousand GPUs
185
510
5,613
222,208
Anap 🔫 | Native Android Dev retweeted

May 19
ada yg namanya hedging kak. jd hrs dikunci dlu nilai kurs nya saat kesepakatan awal. jd pas di akhir projek nanti pembayaran nya ttp pake kurs yg sdh dikunci itu
6
1,282
32,710
ajggg, rupiah naik hampir Rp150 dalam 2 hari. Perasaan kemarin masih 400an :|
6
147