
Filmmaker / AI x Creative Technologist / Founder
Joined December 2010
- Tweets 89
- Following 406
- Followers 131
- Likes 165
13 Photos and videos

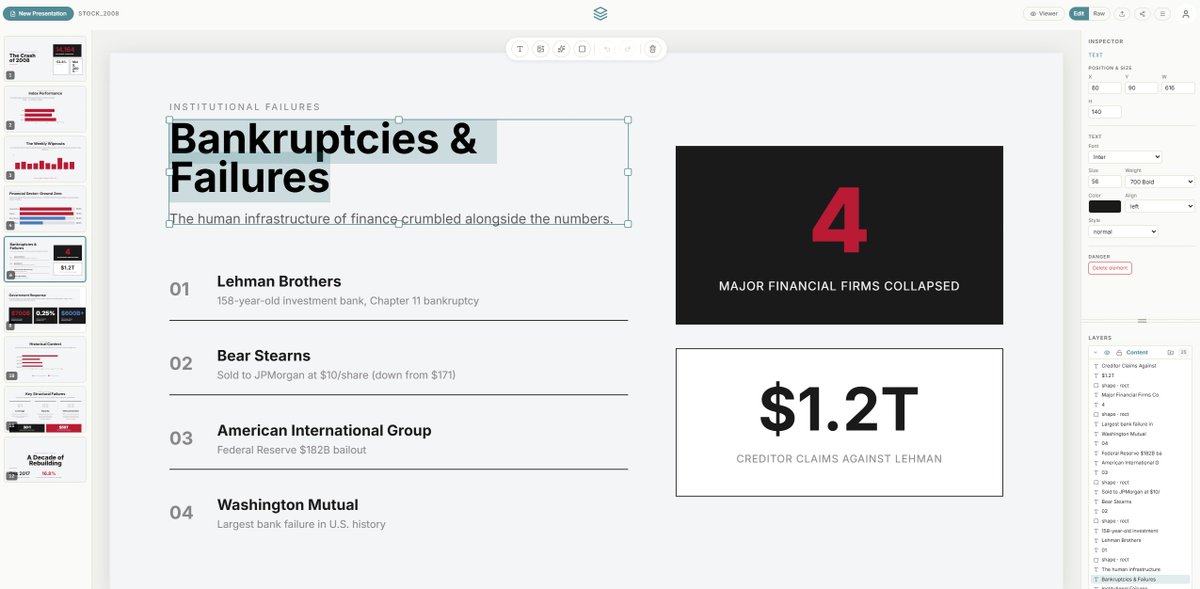










Pinned Tweet

Jan 8
Bringing our original craiasa.com creations to life.
The Workflow: Custom trained LoRA, Midjourney Nano Banana @grok Imagine.
From static design to cinematic motion all in support of our brand's vision.
#GenerativeAI #Cinema #SocialMediaMarketing #storytelling #FashionTech #Grok @xai
1
3
328
Jun 11
This is a status update, what’s important: the video.
Name found? For now, temporary. But we run with this philosophy: wabisabee.app
I was recently working on this PoC, built on opensource, human enhanced, and focused on privacy. We achieve this by running a serverless, zero data retention architecture.
One full generation: 2min
From PoC to MvP: Almost there…
Planning this as a research project. Will launch anyway, testing in production 🙂
Meanwhile, I present to you: the first sketch of this app video showcase
What do you think, am I getting there?
#design #genai #build #vibecoding #datavis
15
Jun 4
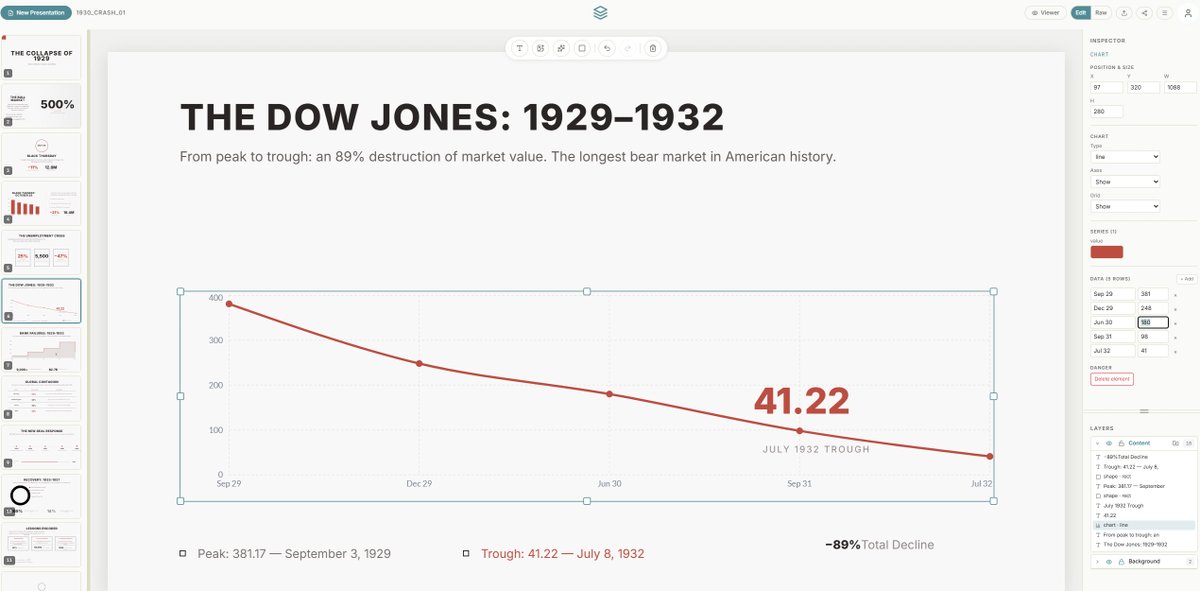
For the past couple of weeks, I’ve been working on a Proof of Concept (PoC) and personal research project to assess the current boundaries of open source LLMs for coding and advanced product building.
My focus? Build a design web app and editor for text2presentations.
Recently there was a lot of buzz with the launch of Claude Design in this space.
Other industry giants like Adobe, Canva, Google together with dozens of other start-ups have highly optimized generative AI slide deck builders. However, the tradeoff usually falls between slow, high token cost premium models or fast, heavily templated alternatives that lack true design finesse.
So my initial product brief was simple: build an application that generates great looking, creative diverse presentations in under 2 minutes, using a fraction of the token budget of frontier models on open source LLM’s infrastructure. Also, use all available open source and frontier models on the project to assess their cost and viability.
The results from the initial PoC exceeded my expectations.
By leveraging a custom orchestration layer that is the "secret sauce" constraint engine (“the harness”) that I designed around the models, I was able to get the app running on just 50k tokens using serverless cloud hosted models like MiniMax 2.7, generating high-quality, fully editable presentations in under 120 seconds.
To test the true limits of vibe coding and local infrastructure, I ran a local setup on an RTX 4090 - 24GB VRAM using llama.cpp and opencode web UI, handling the bulk of the early architecture with Qwen 3.6 27B running at 40 tk/s with a 200K context window made possible by Turboquant.
The beauty of this architecture is that the entire generation pipeline can run locally with 100% privacy on high-end GPUs.
I treated this as a rigorous multi-model research experiment on development efficiency (cost vs performance):
Orchestration & Code Base: Primarily built utilizing open source models like DeepSeek V4 Pro/Flash, GLM, Qwen and MiniMax via Ollama.
Frontier Model Comparison: Used Claude Code with Opus 4.7 and Gemini 3.1 Pro for roughly 10-15% of the codebase to see how these models compare with the open source ones.
The whole journey is a massive learning experience and it feels incredibly fun building things in a way that was never possible before.
Once the core generation engine was stable, I put my Product Manager hat on to move toward a launch ready MVP.
Over the past week, I focused heavily on system resilience, security, and user data flows.
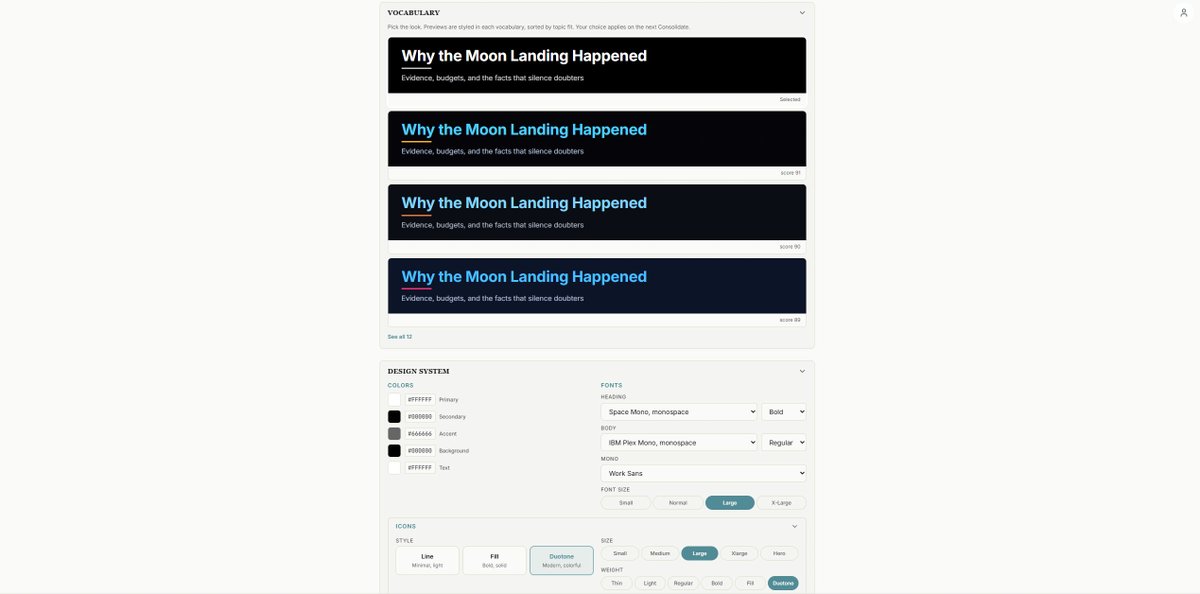
Brand Guidelines via Vision
Users can upload reference images or documents to establish custom branding guidelines and automated asset summaries.
WYSIWYG & Canvas State
Workspace management system where past decks can be stored, shared via public links, exported to disk, or tweaked directly in a live editor.
System Hardening & Security Audit
Built comprehensive guardrails against attack vectors inherent to prompt-driven apps, including aggressive prompt injection and various code injections.
Scalable Cloud Architecture
Architected a 3-Tier setup, completely decoupling the presentation canvas, the orchestration logic, and the data layer. To ensure high availability and keep database transactions lightning-fast, I decoupled the primary metadata database from an S3 object storage bucket (used for storing heavy slide assets). This is paired with a serverless routing model for LLM calls that completely discards prompt inputs to preserve absolute user privacy.
The most important takeaway from this sprint? In just a few weeks I was able to cover a lot of ground in terms of app building, as my main focus was to see how far I can go in developing a full fledged working app using mainly open sourced models.
We are entering a world where I see local LLMs rising to compete head to head with frontier models, as this project revealed.
They are surely at least 95% percent of the way there.

2
1
5
517
Feb 3
If AI replaces humans, we are in for a dystopian future.
If AI empowers people, we are heading towards a revolution.
AI can do both.
It only depends on what WE prompt it to do!
27
Jan 13
#generativeAI is threatening human developers as much as it threatens artists, arguably, even more.
Yet, what I see the developer community discussing regarding their use of AI is always focused on the outcome, not on the process and certainly not on the training.
Rarely have I seen an #antiAI dev looking down on vibe coders with moral outrage.
Instead, I’ve seen practical arguments on why various vibe coding tools are not yet production ready or how much importance falls on having strong programming knowledge in order to use code generating tools with success.
I also saw great arguments on why the whole AI landscape might grow to be a bubble or why it’s not yet clear how Gen AI companies turn their efforts into profit.
Developers are looking at Gen AI as a tool and are actively discussing the hidden costs and tons of drawbacks that using generated code might bring, the risk of slim comprehension of complex systems, how to orchestrate your AI agents for better results, and many other great discussions around how to achieve better serving output from Gen AI.
Almost all the developers that I know are embracing some sort of vibe coding ranging from tools like Cursor or Claude Code to one prompt wonders like Lovable or Replit.
But they all agree on one thing: The seniority of the human using these tools is paramount.
They position themselves as tamers of the AI. They embrace it while demonstrating their utmost importance as thinking, intent driven human beings in the mix.
Meanwhile, my fellow artists…
They do what they know best: Try to appeal to emotions.
Unfortunately, for any visual creator, the future is already set, and no emotion, no matter how big, will change the tides back to the old ways.
Markets move forward and embrace AI based solely on cold, hard facts, and no amount of emotional outcry is going to change that.
I believe the best course of action is to start thinking more like our fellow developers and approach Gen AI as a tool that needs our expertise in order to be of any use to the people holding the budgets.
And in order to do that we must return to the essence of any great art: curiosity.
#SoftwareDevelopment #CreativeIndustry #FutureOfWork #VibeCoding
1
1
62
Jan 8
Filmmakers should be first and foremost storytellers.
Yes, even in the era of AI. Or better said, especially now.
The language used? Cinema (Cinematography: Writing with moving pictures.)
Story is what keeps the viewer glued to the screen, any screen, be it an IMAX theater or a smartphone in your hand.
It is what connects us as humans and it is the backbone of any cinematic product, be it a motion picture, ad, music video or even a 10s TikTok video.
The stories we choose to tell and the echo they produce in an audience are deeply human experiences.
Story is intent. Nothing exists without a story to tell.
Throughout the years I’ve seen projects succeed or fail strictly based on story. Producers threw money at bad stories, thinking there were other shinier ways to impress an audience. But no matter how good everything else built around that story was, be it sets, actors, budgets, equipment, VFX, you name it, it could never fix it.
What you capture follows the shape of the story just as meat follows the shape of bones.
It does not matter what spectacle you put on the screen and it matters even less how you capture it.
What remains is pure emotion distilled from a great story.
We used to shoot on film stock, then video, digital, and now we capture images from latent space using just prompts.
Technology evolves and using AI we are yet again facing a shiny new toy.
But, as was the case with countless other tools in the past, AI is nothing without a human led story.
And surely it is nothing without a skilled human directing it all into place
#Filmmaking #cinematography #GenerativeAI #Storytelling
1
85
Jan 2
"There are people who burst into laughter in front of these objects. Personally, I am saddened by them. These so-called artists style themselves intransigents, impressionists; they take a piece of canvas, colour, and brush, daub a few patches of colour on them at random, and sign the whole things... It is a frightening spectacle of human vanity straying into dementia." Albert Wolff (1876) - Reviewing the Second Impressionist Exhibition for Le Figaro.
AI art should be judged by the output, not by the process or by the creators.
The AI tools are the same for every creator. Yet what can be achieved with these tools varies wildly.
The human in the mix remains the only differentiator.
He is the one following his inner vision: making the choices, prompting the tools, curating the outputs, mixing the results.
AI slop is prevalent now because experimentation is the prevailing phase of AI. The dust will settle and better outputs will start to filter out to the surface naturally.
If we get stuck like Albert Wolff in analyzing novelty by what we think art standards should be, we are blinding ourselves to understanding and accepting the real artistic merit that these new types of tools could bring.
One path to acceptance is to realize Wolff’s critiques were thrown against Monet, Renoir, Degas and Pissarro.
1
74
Jan 1
Gen AI might not replace cinema, but maybe it can evolve its own branch in parallel.
In the early years of cinema, the art form was very limited. For a few decades, it wasn’t seen as an art form at all. Merely a distraction, burlesque entertainment for the masses usually associated with country fairs, cheap laughs and seen as a new type of circus.
Progress was slow. For years, even decades, there was no meaningful way to move the camera, edit the shots, light them with intent in a controllable way or use sound. All of this while shooting only in black and white for half a century.
Pioneers dedicated their lives to the art and craft of cinema and so, one by one, decade by decade, they overcame all these obstacles and gave cinema all the pillars needed to give birth to a new form of art.
20 years ago I entered film school in Bucharest. For my admission exams I shot stills in BW 35mm film. I shot all my student films in 16mm and 35mm film stock BW and color, but when I graduated in 2010 my thesis paper spoke about the digital revolution and how the new Canon 5D would revolutionize the way films would be made.
I have never shot anything on film stock since. The same is true for perhaps 99% of the industry.
In the meantime, the medium has changed a lot as well. Enter social media feeds, streaming service, and so cinema theatres slowly lost their place.
To me, AI does not seem like the disruptor anymore, as the disruption happened way earlier than this by the changing habits of media consumers.
AI is just here to capitalize on the enormous changes that have already happened.
So, I now believe that there is a huge potential for AI to evolve in the same way that cinema did.
I think we are just in the early stages, in the burlesque era, where the real power of this new way of generating visuals has not yet been tamed.
We don’t yet have all the means of expression using generative AI at our disposal in the same way we have them in cinema.
Because they are not yet discovered.
In order to discover them, we need to be the pioneers who can make it happen.
53
30 Dec 2025
In 1991 Francis Ford Coppola said this: “To me, the great hope is that now these little 8mm video recorders and stuff have come out, and some… just people who normally wouldn’t make movies are going to be making them. And you know, suddenly, one day some little fat girl in Ohio is going to be the new Mozart, you know, and make a beautiful film with her little father’s camera recorder. And for once, the so-called professionalism about movies will be destroyed, forever. And it will really become an art form.”
The video recorders turned to DSLRs and the DSLRs to phones, and the possibility of any random person picking up a camera and shooting a masterpiece film increased 1000x.
Yet the success stories are few and far between. What we got instead is TikTok and mindless scrolling. A new form of entertainment was born, but not a new art form as Coppola was predicting.
Since the advent of genAI, the hype and sentiment resurfaced. Anyone can now be an artist, illustrator, filmmaker.
3 years have passed since then and I am yet to see success in that way. Someone who wouldn’t normally be making movies, picking up an AI and creating cinema, art, something meaningful.
Maybe we are too early and that day will come sooner rather than later.
But in the meantime we need to understand that genAI needs to be seen only as an exoskeleton, a tool with great leverage that can only be as good as the real people using it.
It can speed up execution, but it will have a hard time replacing intent, experience or the fundamental skills of the cinematic language.
There seems to be an interesting future ahead, and this technology will only be useful as long as real artists experiment, understand and innovate ways to use it with real impact.
42
31 Jul 2025
Used a combination of AI tools and human creative direction for this #ai #ad #directresponsemarketing
53
15 Jan 2016
Shooting my 1st #bollywood movie. Awesome experience. #dop #indianfilm #REDEPIC #dragon #india #cinematography
1
11
Andrei Goaga retweeted

3 Dec 2015
The emotional power of Stallone's "Rocky" character comes from his complete earnestness. This one still hits hard. youtube.com/watch?v=QrmQqEg4…

2
1


Andrei Goaga retweeted

23 Aug 2015
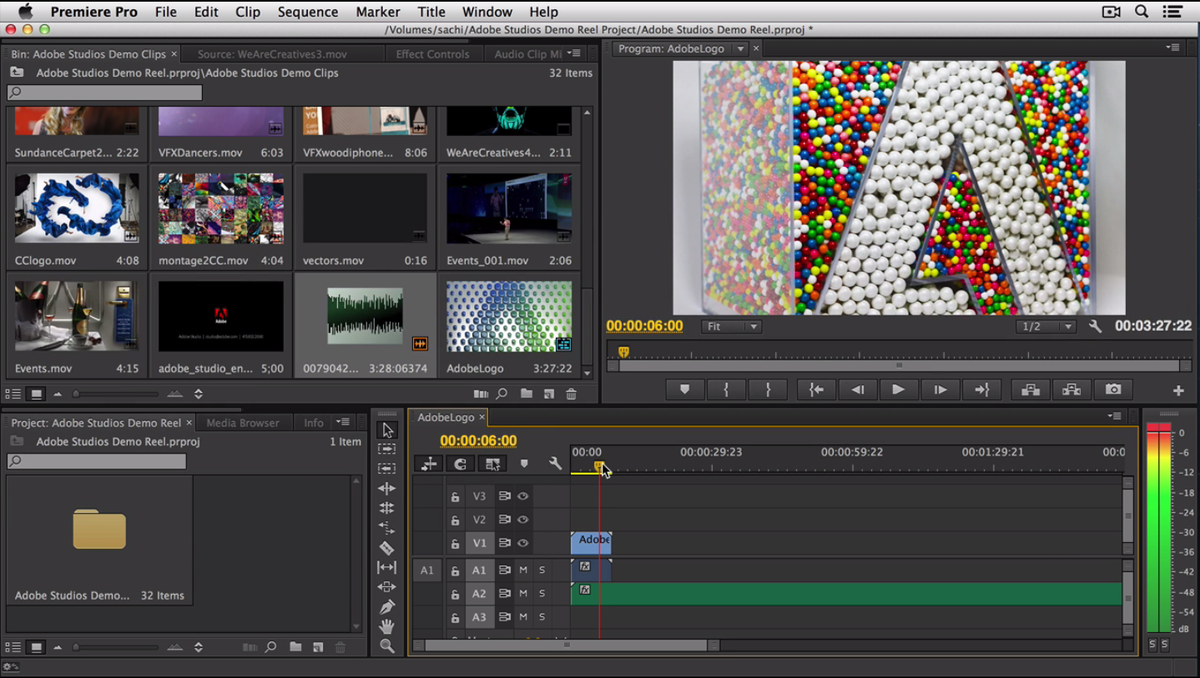
HOW TO assemble your demo reel: bit.ly/1KEH9id
Using #PremierePro to showcase your best work
#CreativeCloud
2
19
37
21 Aug 2015
Just now, shooting a flash mob for a new #punjabifilm in Victoria Square, #flashmob, #DOP, #cinematography
1
5
14 Aug 2015
Getting good coverage! Good time filming this #indianmovie here in the UK, m.facebook.com/story.php?sto…, #punjabicinema, #BBC, #DOP, #bollywood
Andrei Goaga retweeted
10 Apr 2015
Creativity is about to get a lot more colorful: adobe.ly/1DpNFtJ
#CCNext
amp.twimg.com/v/8b38c039-a36…
1
10
8
1 Apr 2015
What is the best approach/best leads to look for as an experienced DP/Director if you just relocated to the UK? #getintoTV
1
2