
Humanist, Systems Thinker, Safety Nerd, Senior Director of Engineering @totalexpertinc, Devopsdays MSP Organizer, Chaos Engineering Book Contributor, he/him
Joined June 2008
- Tweets 6,973
- Following 427
- Followers 774
- Likes 11,743
1,015 Photos and videos















Pinned Tweet

28 Feb 2018
“Work is an adaptive phenomenon, workers deal with what they have in front of them and adaptively create success” “Leadership is an emergent property of the system” From Leading a Complex Organization - Jim Barker preaccidentpodcast.podbean.c…
1
5
17
1 Mar 2023
Missing my friend today. I read my grief stricken stream of consciousness that's on the next page in my notebook and that brought back A LOT of feelings. But I also caused some good trouble today in a meeting like he would, and that felt good.
4
260
10 Feb 2023
If you aren't talking to people, you've failed.
9 Feb 2023

👀@samnewman explains why creating a platform should NOT be the purpose of a "Platform Team" (and thus we shouldn't use that term)
samnewman.io/blog/2023/02/08…
175
14 Jan 2023
I think it's finally time to start telling the story. If anyone wants to chat about Internal Developer Platforms, like really, the good, the bad, and the silly hmu. I think I'm ready to go past shitposting about it..well...maybe.
1
234
Andy Fleener retweeted

Suspending my twitter break just to announce a new blog post: surfingcomplexity.blog/2022/…
5
7
19
4,230
Andy Fleener retweeted

27 Nov 2022
.@LFISoftware Newsletter — Issue #1
mailchi.mp/45080001a51c/lear…
1
5
12
22 Nov 2022
Ok I've settled on a mastodon account/server you can find me at hachyderm.io/@andyfleener
22 Nov 2022
*[Citation needed]*

Software Engineers don't realize that 95% of production outages come from code changes.
Twitter has been on a code freeze for almost 3 weeks now which explains how it has stayed up and running with only skeleton crew.
1
2
16 Nov 2022
I would argue failed chaos experiments have been the norm in organizations for decades otherwise taylorism would have died years ago.
15 Nov 2022

I've been asked A LOT of questions about Chaos Engineering over the years, and #3 FAQ is "Have you ever considered doing Chaos Engineering at an org level? Like just have some people not show up to work and see what happens?" Well, this week Twitter is relevant to my interests.
2
14 Nov 2022
Maybe Elno should consult with Taleb. I bet he could help him with this mess. 😎😎
13 Nov 2022
Tell me you don’t have enough operations experience without telling me.
13 Nov 2022

One of my cofounder friends asked me how much downtime we have when deploying code and I looked her dead in the eye and said, "What downtime? We don't have any downtime when we deploy. If we do, something's gone wrong." So I prodded her for more context on why she asked...
4
8 Nov 2022
I had the pleasure of working with @TheJewberwocky for several years. I don’t think I’ve ever worked with someone as thoughtful and empathetic about building humane and effective systems as Josh. Hire him as fast as you can!
8 Nov 2022

I'm not entirely sure if I'm ready for this, but who knows if my network will still be here next week. I'm putting myself back on the job market.
If you're hiring or intending to hire SRE/Ops/devops/Platform managers in the next few months, I'd love to chat with you!
3
Andy Fleener retweeted

Hey, tap-tap🎙️...we're back. Well, we never left, but we've been busy outside of Twitter (how's Twitter going these days?)
We have our first ever conference coming up this February. Are you doing interesting things with incidents? We want to hear from you register.learningfrominciden…
2
25
37
Andy Fleener retweeted
Wooo, the CFP for the first @LFISoftware (Learning from Incidents) conference is now up!
web.cvent.com/event/e3af0a43…
5
18
40
Andy Fleener retweeted
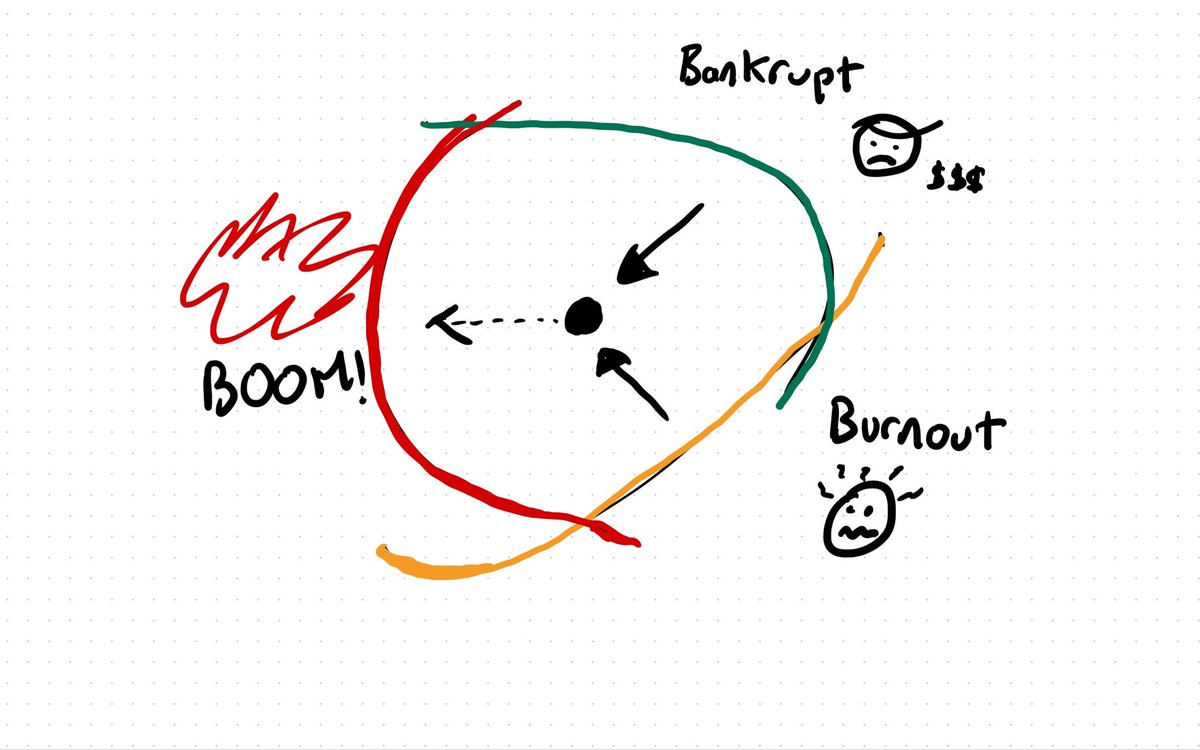
Sounds like Twitter’s going to provide us with an object lesson in Rasmussen’s safety model. If you’re cutting costs and people are burning out, the system gets pushed towards the safety boundary. Outages coming?

Here’s a doodle of Jens Rasmussen’s dynamic safety model.
* Bankrupt - boundary to economic failure
* Burnout - boundary to unacceptable workload
* BOOM! - boundary of fundamentally acceptable performance
6
17
55
3 Nov 2022
Shout out to @datadoghq for their predatory overage charges because of blue green deployments. And sending me back and forth between my AM and support to help me understand how the fuck they're calculating them 🙃🙃🙃
1
1
3 Nov 2022
I still don't have a real answer other than "they bill for a few hours after they're shut down" Anyone know how to not get charged insane amounts of money because you deploy 10 times in an hour?
18 Oct 2022
I mostly stay out of the “Platform Engineering” hype cycle discourse. But the frame in which it’s being used at my company is so far beyond anywhere I’ve been before, and let me tell you it’s fucking awesome. Seeing how far we’ve come in a year 🤯🤯
1