Parent, Permaculture, Ukulist, ex-@replicate, ex-@planet, @OpenStack, UserScripts. I love the ocean, browsers, clouds & unicorns
- Tweets 6,567
- Following 1,524
- Followers 3,408
- Likes 15,965







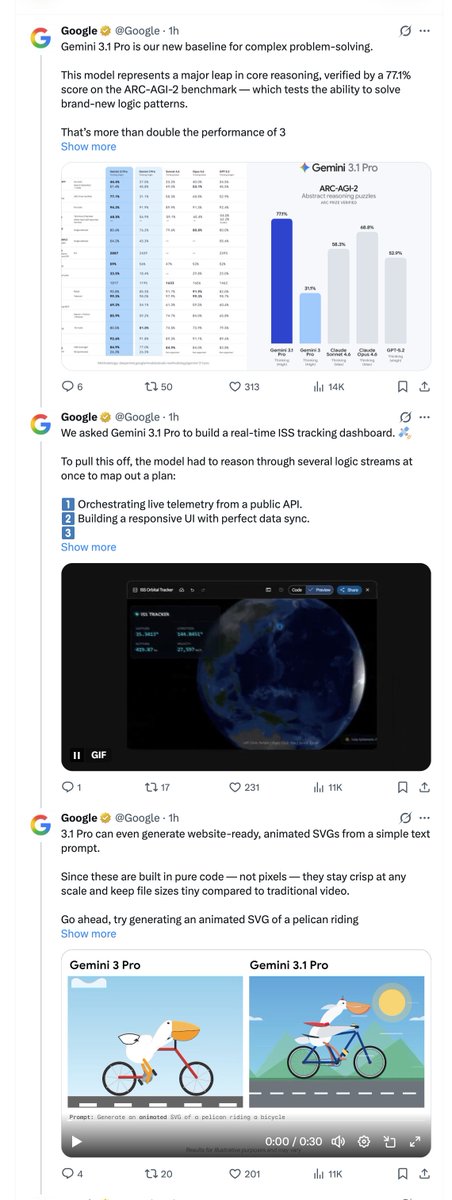




ALT #!/usr/bin/env -S llm -x -f Generate an SVG of a pelican riding a bicycle But you can also incorporate tool calls: #!/usr/bin/env -S llm -T llm_time -f Write a haiku that mentions the exact current time Or even execute YAML templates directly that define extra tools as Python functions: #!/usr/bin/env -S llm -t model: gpt-5.4-mini system: | Use tools to run calculations functions: | def add(a: int, b: int) -> int: return a b def multiply(a: int, b: int) -> int: return a * b Then: ./calc.sh 'what is 2344 * 5252 134' --td Which outputs (thanks to that --td tools debug option): Tool call: multiply({'a': 2344, 'b': 5252}) 12310688 Tool call: add({'a': 12310688, 'b': 134}) 12310822 2344 × 5252 134 = **12,310,822**