
| Just another Army Grunt | Delivering decentralization @hlabs_tech | Spectrum: Decentralization.
Joined June 2009
- Tweets 8,241
- Following 2,482
- Followers 921
- Likes 16,122
605 Photos and videos















Mike retweeted

21h
One thing I learned spending time with @Cardano founders: Talent is strong, but scaling becomes the bottleneck.
What teams actually need are people who have successfully built before sitting next to them while they do it. That's why a venture studio sits at the center of how we structured @OrionFund, not off to the side.
Looking forward to introducing the team on the 22nd!

A key part of the Orion Fund's structure is Draper Dragon’s venture studio, the team responsible for incubating new products on Cardano and working directly with builders across the ecosystem.
On June 22nd at 8:00 AM PST, we'll be officially introducing the venture studio team and sharing more about how they'll build and collaborate on Cardano in the coming years.
Link to the space: x.com/i/spaces/1rGmqqznryVGy…

2
5
32
1,073
This 100%, even if you have to buy the hardware on credit, it's still better paying a monthly fee for something you own vs rent. And with how good open weights are getting the juice is worth a squeeze.

US AI bros say hardware for running local LLMs is expensive.
Your subscriptions and API bills vanish the moment you use them.
Hardware does not disappear.
Worried about depreciation? The 5-year-old Mac Studio M1 Max and RTX 3090 currently have higher used prices than their launch prices.
Hardware is just a deposit.
It is an asset of yours that never disappears.
52
Mike retweeted

The new political spectrum just dropped

5
8
35
785

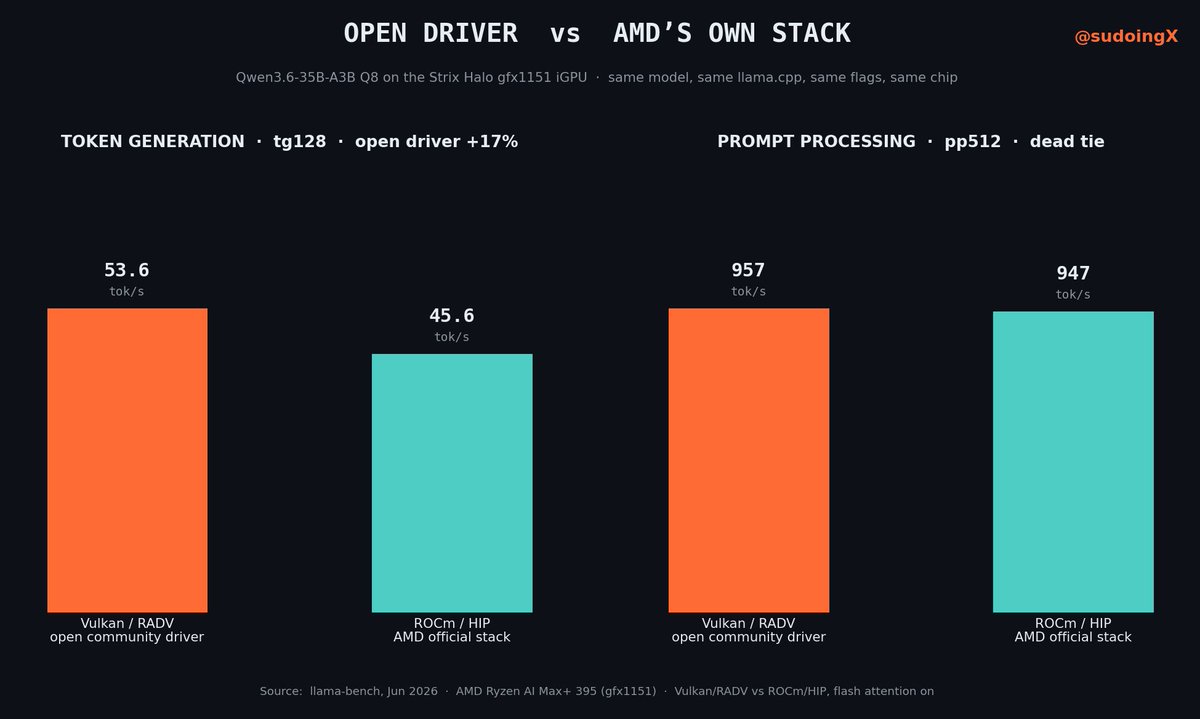
the fastest way to run local ai on an amd chip, it turns out, is to not use amd's software.
i found this benchmarking the strix halo, amd's 128gb ai box i've been living in. there are two ways to run a model on it: amd's own official stack, rocm, the thing they build and ship and put their name on. or vulkan, the driver the mesa community wrote, volunteers, unpaid, working off public specs.
i ran the same model both ways. same Qwen3.6-35B, same llama.cpp, same flags, same chip. the only thing i swapped was the driver underneath.
>rocm, amd's official stack: pp 947, tg 45.6 tok/s
>vulkan, the volunteer-built driver: pp 957, tg 53.6 tok/s
prompt processing, dead tie. but token generation, the part you feel when the model's typing back at you, the free community driver is 17 percent faster. on amd's own silicon. than amd's own software.
sit with that. a chip company shipped the hardware, and a pile of volunteers wrote better ai software for it than the company did. nobody got paid for the fast one.
and if you own one of these it's a gift twice over.
one, switch to vulkan today, that's 17 percent more speed for the cost of a single flag.
two, rocm trailing the open driver by 17 percent means it's leaving exactly that much on the floor, so the day amd's stack catches up to what volunteers already pulled off, your chip just gets faster for free, no new hardware.
this is the accessible end of local ai, and it's full of stuff like this you only ever find by running the thing instead of reading the box.

in local ai fast and worth it are two completely different numbers.
last post i showed you the fast one. this one is the number that actually decides what you should buy, and it does not crown the same winner.
quick catch up if you missed it. i have two 128gb boxes on my desk, the nvidia dgx spark and the amd strix halo, and i ran the exact same model on both, byte for byte the same file, same everything, both idle.
nvidia won on raw speed. that was the whole post.
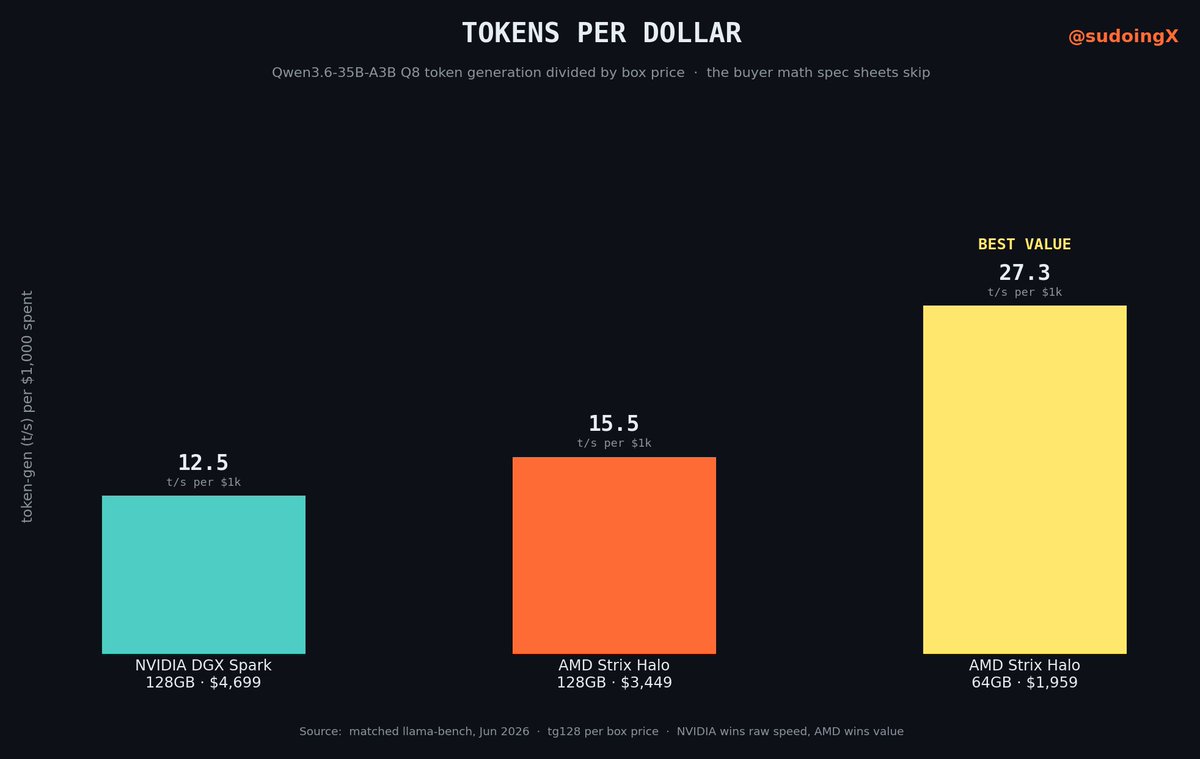
but raw speed is what the spec sheet wants you to stare at. the number that actually matters when the money leaves your account is this one, how much ai you get per dollar you spend. so i took each box's token generation speed and divided it by what the box costs.
so here is tokens per dollar, the token-gen speed each box gives you for every $1,000 it costs:
>nvidia dgx spark, 128gb, $4,699 → 12.5
>amd strix halo, 128gb, the one i benched, $3,449 → 15.5
>amd strix halo, same chip in a 64gb box, $1,959 → 27.3
all three are tok/s for every $1,000 you spend, higher means more ai for your money.
now look at the bottom line. the same amd chip in the cheaper 64gb box gives you more than double the inference per dollar of the spark, and it runs this exact model at the same speed, because on these chips speed comes from memory bandwidth not capacity and the bandwidth is identical.
that is not a rounding error, that is the whole buying decision sitting right there.
here is why it happens, because this is the part that makes it real instead of a price whine. the speed you actually feel, the model typing its answer back to you, is decided by memory bandwidth, not raw compute.
the chip has to pull the model's weights out of memory once for every token it writes. both boxes have nearly the same bandwidth, about 256 against 273 gigabytes a second, so they write at nearly the same speed.
so what does nvidia's extra 3x of price buy you? compute. the blackwell chip has a lot more raw math, which is exactly why it was 2x faster at reading your input in the last post. and that is real.
but reading your input happens once. writing the answer happens for every token, all day long, and that is the part bandwidth owns, and the bandwidth is basically tied.
to be fair to the expensive box, because the silicon decides this, not my wallet.
if your work is huge context and heavy document crunching, that 2x prefill speed genuinely earns its keep. cuda is also years more mature than rocm, which the price tag never shows you but you feel the first time something breaks. and the spark has high-speed networking built in to link two of them into one bigger machine, the strix has no such ports at all, so if your plan is to chain boxes together the spark is made for it and the amd box simply is not.
for most people running a chat or an agent loop on a single box though, you are paying triple for muscle you will almost never flex.
one honest caveat so nobody can swing on it, the spark's price includes a 4tb drive against the strix's 1tb, so part of that gap is storage, not silicon. it tightens the math a little. it does not close it.
the spec sheet leads with speed because speed sounds expensive and impressive. the buyer math is quieter, and it points the other way.
the accessible tier of local ai is further along than the timeline thinks, and it costs a lot less than they keep telling you.
17
7
89
6,443
Mike retweeted

Jun 16
It's very interesting the way @MicheleHarmonic designed the contract's API. Plinth and Plutarch give you a generic entry point for multi-validators. Aiken and Scalus give you specialized per-purpose entry points. And now Pebble almost completely abstracts away the purpose redeemer datum relationship into something similar to a TS class.

4
17
807
Mike retweeted

Jun 16
Eternl is my favorite wallet since 6 years and a critical part of Cardano infrastructure. Let’s make sure this one will pass 🙏
Jun 16

Updated proposal:
Eternl: Path to Sustainability - v2
adastat.net/governances/fbb8…
The previous proposal, “Eternl: Path to Sustainability (2026-2027),” received NO votes from CC members due to a lack of clarity regarding audits.
This new proposal is essentially the same as the previous one and adds that clarification.
Key differences:
- Added clarification on Audit funds spending and oversight metrics, as requested in the CC vote rationales.
- Updated Ada to USD conversion rates
- Changed FAQ answer: Eternl DRep abstains on this proposal
Clarification on FTEs:
Our price per FTE is $70,000 (compared to other proposals exceeding $200,000 per FTE). A reasonable lower bound rate. Our 6 FTEs are distributed across 10 people contributing to Eternl in various capacities, most of them part-time.
Thanks to everyone who took the time to vote on the first attempt.
Please consider voting on the updated proposal as well.
Cheers,
Your Eternl Team
1
2
17
422
slowly? i just put it on the bench. there is nothing slow about this.
a first-gen amd apu, the class of chip that sits in a laptop, came within 10% of a purpose built nvidia ai box on token generation, the speed you actually feel, at a third of the price. and it loaded a 397 billion parameter model on a desk. that is not "getting there." that is here.
the "slowly" is reading the snapshot and missing the slope. this is the exact playbook lisa su already ran once. everyone called amd hopeless in cpus too, right up until epyc took the datacenter and intel is still bleeding from it.
she is running the identical long game in ai now, the mi datacenter line is already pulling real share, and the consumer apus just put 128gb of unified memory on a desk at a price nvidia has no answer for.
to be clear, nvidia still leads today. faster prefill, deeper cuda stack, the training crown. this is not "amd won." it is the gap closing far faster than the word "slowly" allows, on a curve that only bends one way.
the people sleeping on amd right now are the same ones who slept on epyc in 2018. you don't get to bet against lisa su twice.
and what is coming next only steepens the line.

I knew AMD would come in close. They are slowly getting better.
12
1
40
4,442
Mike retweeted

Jun 16
Eternl updated and resubmitted their proposal.
Jun 16
Updated proposal:
Eternl: Path to Sustainability - v2
adastat.net/governances/fbb8…
The previous proposal, “Eternl: Path to Sustainability (2026-2027),” received NO votes from CC members due to a lack of clarity regarding audits.
This new proposal is essentially the same as the previous one and adds that clarification.
Key differences:
- Added clarification on Audit funds spending and oversight metrics, as requested in the CC vote rationales.
- Updated Ada to USD conversion rates
- Changed FAQ answer: Eternl DRep abstains on this proposal
Clarification on FTEs:
Our price per FTE is $70,000 (compared to other proposals exceeding $200,000 per FTE). A reasonable lower bound rate. Our 6 FTEs are distributed across 10 people contributing to Eternl in various capacities, most of them part-time.
Thanks to everyone who took the time to vote on the first attempt.
Please consider voting on the updated proposal as well.
Cheers,
Your Eternl Team
4
6
43
1,137
Mike retweeted

Jun 16
Tomorrow is an exciting day!!!!
babylonjs.com/lite/
#3D #WebDev #gamedev #indiedev #WebDevelopment #webgl #gamedevelopment #IndieDevs

2
22
691
Mike retweeted
Jun 15
DReps: Proposal to fund Eternl Wallet will be active for 3 more days.
You can still vote.
The Eternl DRep Committee abstained.
Some DReps may have seen this as an obstacle to a YES vote. They can now reconsider their vote.

5
20
104
2,240
Mike retweeted

Jun 16
Cardanoエコシステムに大きな追い風ですね👀🔥
Draper Dragon Orion Fundが
8,000万ドル規模のCardanoイノベーションファンドを立ち上げ。
初期段階のプロジェクト支援や、
TVL拡大に向けた投資が行われるとのことです。
優れたアイデアや開発者に資金が流れることで、
Cardano上から新たなサービスやプロジェクトが生まれることに期待。
最近は
✅ TVL増加
✅ ステーブルコイン流入
✅ 機関投資家向けインフラ整備
✅ ベンチャーファンド設立
と、エコシステムの成長を支える動きが続いていますね。
#Cardano #ADA
Jun 16

NEWS: Draper Dragon's Orion Fund is officially launching a $80M Cardano innovation fund.
The goal is to use the fund to support early-stage Cardano founders and help grow the ecosystem's TVL.
First cohort is now open.


1
14
72
1,662
Mike retweeted

Jun 16
UPDATE
$80M FUND LAUNCHED TO BOOST CARDANO BUILDERS😱😱😱
@DraperDragon Orion Fund has officially launched an $80 million Cardano innovation fund aimed at accelerating early-stage ecosystem growth.
The initiative will focus on backing Cardano $ADA founders, supporting new projects, and boosting overall TVL expansion across the network.
Applications for the first cohort are now open.


17
119
700
14,263
Mike retweeted

Jun 16
Hydra v2.2.0 is out!
This release introduces Partial Fanout.
Until now, the number of UTxOs a Hydra head could hold was effectively capped by what fits in a single fanout transaction. With partial fanout, a head holding an arbitrarily large UTxO set can be closed out across multiple steps: each PartialFanoutTx distributes as many outputs as fit in one transaction, and a final FinalPartialFanoutTx burns the head tokens to complete the process. This removes the long-standing per-head UTxO ceiling.
github.com/cardano-scaling/h…
9
44
160
6,074
Mike retweeted
The constitution is a joke, it allows for too much abuse of power and overreach
Please support the eternl team
Jun 16
Updated proposal:
Eternl: Path to Sustainability - v2
adastat.net/governances/fbb8…
The previous proposal, “Eternl: Path to Sustainability (2026-2027),” received NO votes from CC members due to a lack of clarity regarding audits.
This new proposal is essentially the same as the previous one and adds that clarification.
Key differences:
- Added clarification on Audit funds spending and oversight metrics, as requested in the CC vote rationales.
- Updated Ada to USD conversion rates
- Changed FAQ answer: Eternl DRep abstains on this proposal
Clarification on FTEs:
Our price per FTE is $70,000 (compared to other proposals exceeding $200,000 per FTE). A reasonable lower bound rate. Our 6 FTEs are distributed across 10 people contributing to Eternl in various capacities, most of them part-time.
Thanks to everyone who took the time to vote on the first attempt.
Please consider voting on the updated proposal as well.
Cheers,
Your Eternl Team
5
3
53
2,410

Jun 15
Now this is pretty cool, CAN bus is getting pretty robust.
Jun 15

Weekend project: reverse engineered the RAM 2500 CAN bus.
Captured live CAN traffic, found the message IDs that moved in the 2024 layout, patched the DBC/fingerprint path, and got openpilot working.
Supervised L2, not full self driving, but still pretty damn cool!
29
Jun 15
Has anyone run any tests on this bad boy? So far Qwopus 3.6 27b coder is unbeatable imo.
Jun 14

Gemma 4 12B Coder is here and it's a game changer for local code generation. This GGUF model packs Google's latest gemma-4 architecture into a compact 12B size, perfect for running on consumer hardware. It's optimized for reasoning and thinking, making it ideal for developers who want fast, private coding assistance without the cloud.
105
Jun 14
Pretty sweet

🚀 hermes-lcm v0.17.0 is live!
Context release:
🎯 Focused compression
🛡️ Redacted hints
🧹 Safer lifecycle GC
Update:
git -C ~/.hermes/plugins/hermes-lcm pull --ff-only
Thanks to contributors.
Bounded context, unbounded memory. Nothing is ever lost.
github.com/stephenschoettler…
2
128
Mike retweeted
Btw you can get rid of collateral problems by using normal tx inputs as collateral too
Collateral is basically a sub-transaction specified as fallback since collateral outputs
That's what buildooor does automatically if no collateral is specified
1
7
154
Mike retweeted
Wait so you co-sign every tx?
You know you could implement Babel fees already?
2
1
6
593