
410 Gone to find the bluer skies #DataBS 👋
Joined September 2010
- Tweets 5,334
- Following 416
- Followers 2,655
- Likes 5,760
635 Photos and videos













"Imagine halving the resource costs of AI and what that could mean for the planet and the industry -- based on extreme estimates such savings could reduce the total US power usage by over 10% by 2030"
30 Oct 2024

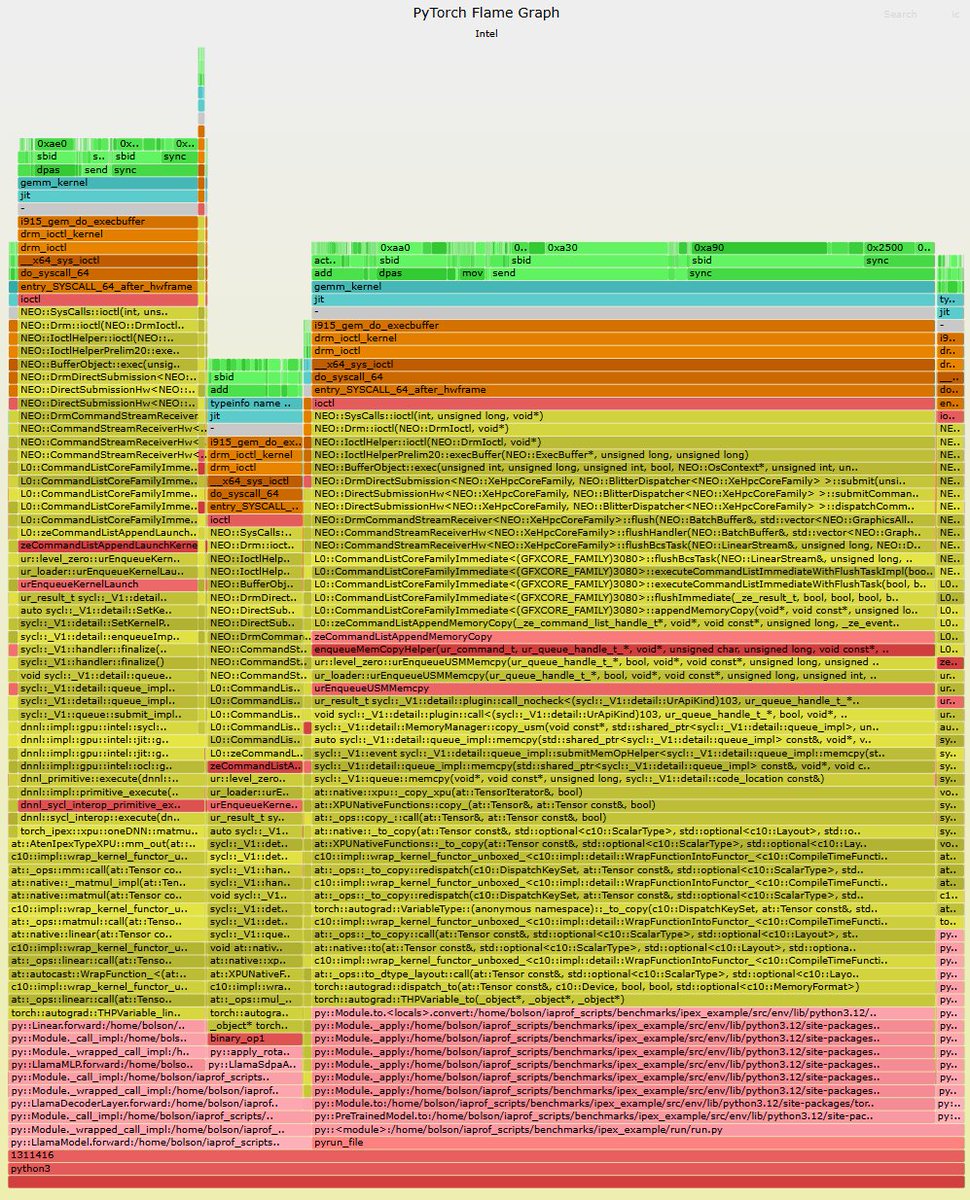
AI Flame Graphs: Showing what's actually running on the HW and how we got there. Uses Intel EU stall profiling and eBPF. brendangregg.com/blog/2024-1…
1
546
Last Friday, I gave a talk to my friends at @FactorialEs about cell architecture. It was also a great reminder for me of how companies are using Kafka in production. While they aren't using Flink or even Java-based clients, they're quite happy with the results so far.
1
14
662

Just published my first Substack blogpost: Demystifying Distributed Checkpointing
expertofobsolescence.substac…
3
7
997
Eliminating Kryo Serialisation in Apache Flink 1.20 to remove back pressure linkedin.com/pulse/eliminati…
1
282
Ramesh and I are ready for our talk in @FlinkForward about streaming over S3 with Paimon, Iceberg or the Flink FileSource/Sink and how we use them to optimize our pipelines in @newrelic
1
5
427
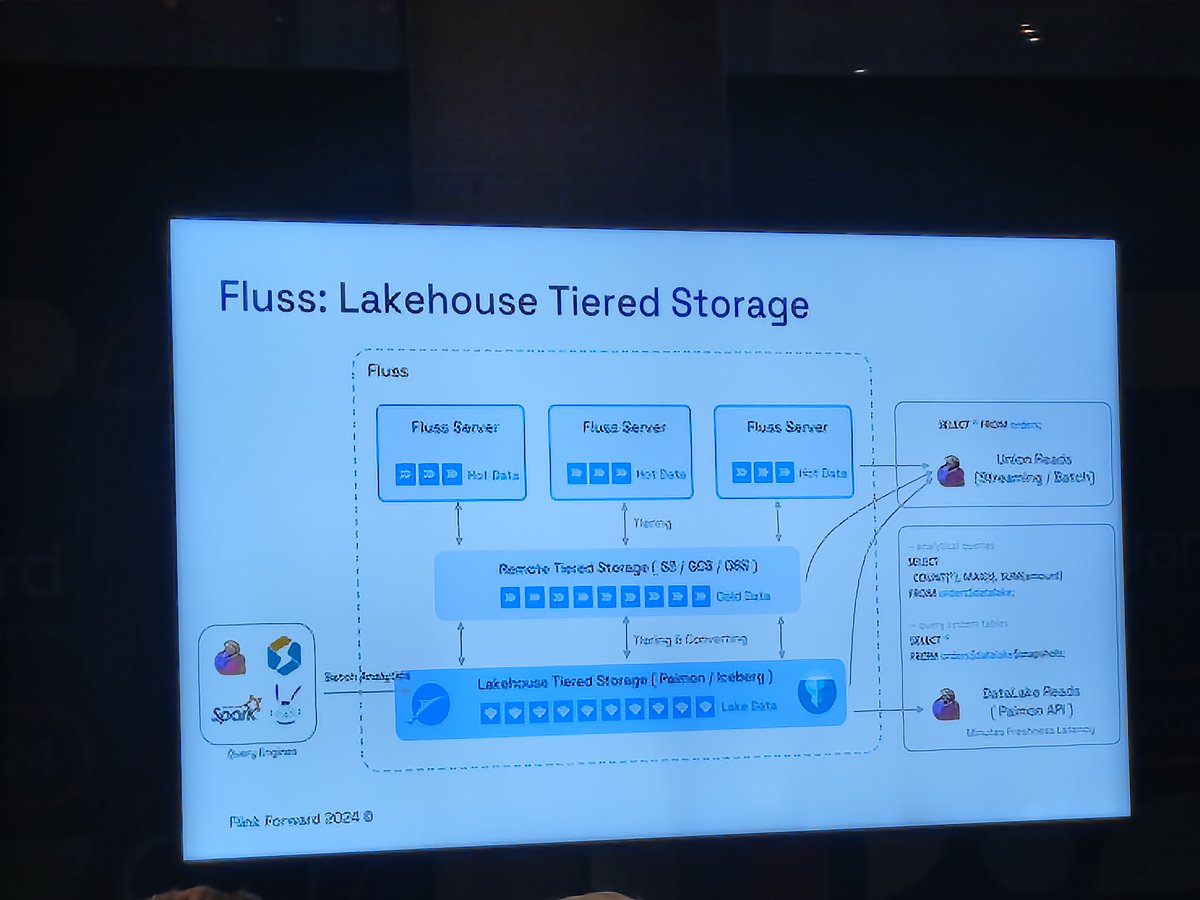
I'm speaking at #FlinkForward tomorrow and attending the talks today. Very excited with Apache Flink 2.0 and with FLUSS to replace Kafka for some use cases. Kafka and object storage combined using Flink is the future of data streaming
2
1
14
878
Informative article about data transfer between TaskManagers and JobManagers in Apache Flink medium.com/@lenonrodrigues/d…
1
2
282
Very impressed with @GoogleAI NotebookLM! I've just attached a @ElectricityMaps dataset with carbon intensity data and it was able to generate a summary and a pretty good podcast explaining it in detail 🤯
1
5
897
This is the full version in case you are interested. I love the final recommendation about taking a look to the data for your own country. @ElectricityMaps is a superb way to understand carbon emissions and how (and when) use electricity, let's use it!
youtu.be/ckA1Rr1s21Y
1
243
"Infrastructure vendors need to ask themselves: does our system deploy self-managed, BYOC, and as a SaaS cloud? Can we support in-process embedded, single-node, and clustered execution? If not, you’re cooked" 🔥
26 Sep 2024

New post is up! Next-gen infrastructure must support flexible deployments. Embedded, single-node, clustered, BYOC, SaaS, and self-managed. We're finally able to do this with one codebase.
materializedview.io/p/the-ne…
1
2
606
"Monitoring Apache Kafka for cloud cost reduction" by myself (2023) newrelic.com/blog/how-to-rel…
1
5
1,763
"Tuning Apache Kafka Consumers to maximize throughput and reduce costs" by Chris Wildman (2024) newrelic.com/blog/how-to-rel…
1
3
1,338
"Scaling Data Ingestion: Overcoming Challenges with Cell Architecture" by Ramesh Motaparthy and myself (2024)
current.confluent.io/2024-se…
1
249
Amazing talk by @PinterestEng in #current24. They are using Kafka Tiered Storage to allow consumers to consume from Kafka, object storage or both, so they can do it more efficiently and reduce costs and start up times.
Combine Kafka and Object Storage is the big thing this year
1
10
870
Plenty of details in this article, highly recommended! medium.com/pinterest-enginee…
208
Antón retweeted

18 Sep 2024
Meet the Confluent Community Catalyst Class of 2024-2025! 🌟
These exceptional data streaming enthusiasts are champions in the dev community, and we’re excited to see all the amazing things they will achieve! #Current24


2
5
12
1,791
Antón retweeted

18 Sep 2024

2
9
631
Great feedback about our talk and so many questions about cell architecture, streaming over S3 and table formats. It's always a pleasure to speak at #current24
17 Sep 2024

My awesome colleagues Ramesh and Anton from @newrelic on stage at @confluentinc #current24 talking about how to scale data ingestion and overcoming challenges with cell architecture.


7
479
And almost one year later, here we are!

BYOC (Bring Your Own Cloud) is a very interesting way to avoid networking costs and being able to compete with Cloud providers. We'll see more and more companies offering it. Pure SaaS services for low throughout and BYOC for high throughout use cases is a good combination
2
1
587
Antón retweeted

27 Aug 2024
You can't learn if you don't ask questions and make mistakes.
There's no shame in trying to improve yourself. Don't let anyone make you feel ashamed.
1
15
1,619