
Building a preschool for robots @pantographPBC. Previously cofounder @sfcompute, @ExaAILabs
Joined June 2014
- Tweets 98
- Following 907
- Followers 2,405
- Likes 910
11 Photos and videos







Pinned Tweet

23 Dec 2025
Extremely excited to show a preview of what we've been working on!
23 Dec 2025

Introducing Pantograph. We're building a preschool for robots: they teach themselves through exploration, failure, and curiosity.
What we're building and why: pantograph.com/blog/building…

7
13
90
15,299
Feb 25
As the software models get better, the physical world is going to be increasingly important. Come work on it with us!
Feb 25
Pantograph is building robots that learn through self-supervised RL at unprecedented scale.
We're hiring a software engineer to work on our core robot stack and testing infrastructure, including controller logic, component testing, and data collection pipelines. Rust and embedded software experience is a big plus, but mostly we're looking for a relentlessly curious and capable generalist who is excited to learn and get robots out into the world.
3
2
12
2,459
Alex Gajewski retweeted

Feb 23
Computer use models shouldn't learn from screenshots.
We built a new foundation model that learns from video like humans do. FDM-1 can construct a gear in Blender, find software bugs, and even drive a real car through San Francisco using arrow keys.
188
400
3,916
1,180,196

Weird opp??? Mox used to be a city records center, so we inherited a pretty legit server room.
- 120A @ 240V
- 5 ton cooling unit
- 100kW diesel genny w/ 1000-gal tank
- 2.5Gb sym fiber
Can get it live in ~1 month. Who needs serious on-prem infra in SF?

2
4
26
4,122
Alex Gajewski retweeted

25 Dec 2025
Merry Christmas from your favorite robots! 🎄
6
12
69
36,937
Alex Gajewski retweeted

23 Dec 2025
the robots are strong and i am having a great time
23 Dec 2025
Today, we're sharing an early preview of our first generation hardware: treaded base, two six-degree-of-freedom arms, 1kg continuous payload each. We've put 10,000 hours of stress and endurance testing into the critical components.
1
4
36
8,723
Alex Gajewski retweeted

23 Dec 2025
These are even cooler in person! Robotics like most truly interesting things are really data limited and new techniques for these domains will be super important.
23 Dec 2025

Extremely excited to show a preview of what we've been working on!
2
12
2,041
23 Dec 2025
Extremely excited to show a preview of what we've been working on!
23 Dec 2025
Introducing Pantograph. We're building a preschool for robots: they teach themselves through exploration, failure, and curiosity.
What we're building and why: pantograph.com/blog/building…
7
13
90
15,299
23 Dec 2025
These exploration-focused algorithms have never been scaled up before, and there's a lot of room for new ideas.
If you're excited about inventing a new scaling paradigm from scratch, please reach out! DMs are open.
2
19
536
31 Jan 2025
I wonder what you would get if you trained something Cycle-GAN-like between images and music. Probably possible today with the quality of generative models we have!
4
2,178
31 Jan 2025
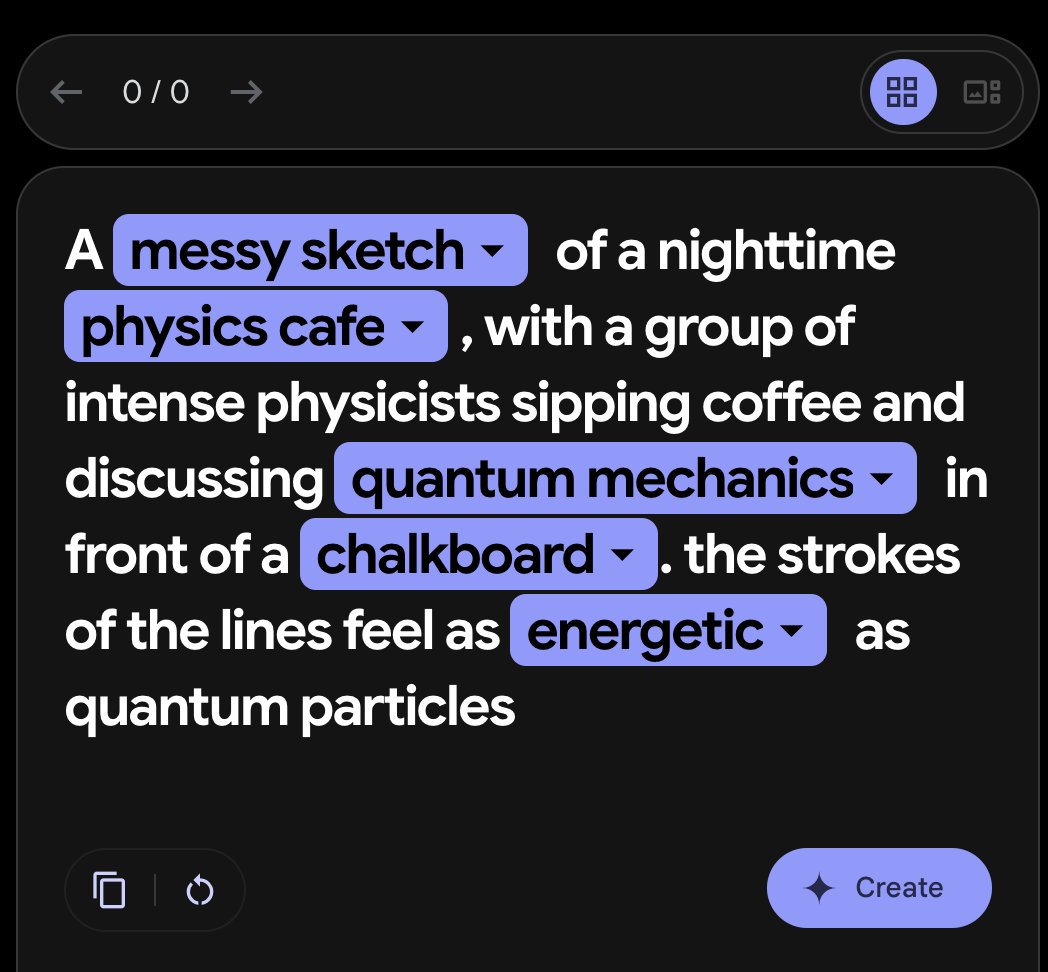
The new google image model is quite good except for the fact that it doesn't like to draw physicists:

3
1,741
30 Jan 2025
This one seems like a good idea to me, increasingly I think datasets and RL environments are the limiting factor:
30 Jan 2025

Devtools for AI Agents
@dessaigne
AI agents are the next wave: autonomous tools that reason, decide, and amplify human productivity. We’re funding startups building devtools for agents, whether you’re creating agent builders or building blocks to perform complex tasks.
1
2
1,691
29 Jan 2025
I hope that somebody starts a company to make an AI-native smartwatch. It feels to me like the ideal form factor for most of what I want a language model to do.
2
916
29 Jan 2025
Feels like a good time to start a computer control startup. The methods are generally known (RL on top of base models), and it probably doesn't require that much compute, just thoughtful environment design. I would probably start with a text-only representation of websites.
1
8
968
28 Jan 2025
Very excited for this new cluster. Big enough to train R1, but it's running our combinatorial auction so the prices should be rational
28 Jan 2025

Hey friends, we're excited to announce that an additional 2,000 H100s will be added @sfcompute's on-demand market.
It's the largest* interconnected cluster, from any provider (including hyperscalers), that you can get on a per hour basis. You're not locked in with San Francisco Compute.
If DeepSeek can compete with OpenAI using 2,000 H800s, you too can train a state of the art RL model without ever having to sign a long-term contract that you can't exit. You could have trained DeepSeek-v3 for $4.5m for 1.5mo on SFC or $35m if you could only buy a 1 year contract off market.
This was the dream Alex & I had since our audio model company (Junelark) died because it couldn't procure enough GPUs, and it's what we've been working towards for nearly two years.
Long-term contracts are a trap; they make it so only the biggest of the big can compete in AI. They force startup founders to raise at massive valuations pre-revenue, which dilutes founders and employees and sets them up to fail when they can't raise their next round.
This cluster will roll out over the next few weeks as we scale our infrastructure. Soon you'll be able to access it via our managed Kubernetes service or by reaching out to set up a custom solution.
We're also exploring other ways of partnering with service providers to let them offer GPU-based services, like workers and inference endpoints, without being forced into a long-term contract with a hyperscaler. You no longer need to bet your company on GPU prices to offer GPU-based services.
* We think! If you know of a larger, please correct us!
17
1,545
23 Jan 2025
One part of SF Compute we haven’t talked about very much yet is that post-AGI (presumably soon), the models will want to train more models.
(Really, people will ask the first models to train more models, or perhaps to solve tasks that would benefit from, say, some custom RL).
It will probably be most natural for those models to buy compute from a liquid market, where they can get precisely the compute they need for each run they need to do.
10
1,217
23 Jan 2025
Has anyone tried “sub-token attention”? Artificially increase the sequence length by including K copies of each token next to each other (say, each linearly projected by a different map), and let the different copies attend to each other. True self-attention :P
(And then at the output project back to a single token to combine)
3
660
23 Jan 2025
I wonder if companies training creative models will be more durable than companies training models to perform well-defined tasks. Because it's easier for competitors to hill-climb on the evals for the tasks, but training a creative model requires the founders to have good taste, which is rare.
4
785
22 Jan 2025
Do you have high-risk AI research ideas that are too speculative to be funded by existing institutions?
We’re considering granting some of SF Compute’s capacity to a small number of interesting projects, on the order of 100s-1000s of H100s. We’re excited by risky ideas that could change the landscape of AI rather than incremental changes. If you have something that’s like this, please DM!
1
4
42
4,770
16 Jan 2025
I wonder how much compute it would take to reproduce the entire published set of deep learning knowledge. if you were efficient about it.
2
2
687