
Joined April 2009
- Tweets 16,654
- Following 2,301
- Followers 5,500
- Likes 34,262
793 Photos and videos











Peter Pistorius retweeted

How to Earn a Billion Dollars: paulgraham.com/earn.html
339
624
5,287
827,699
Peter Pistorius retweeted

Jun 13
Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

548
1,431
12,301
4,203,086
Peter Pistorius retweeted

Jun 12
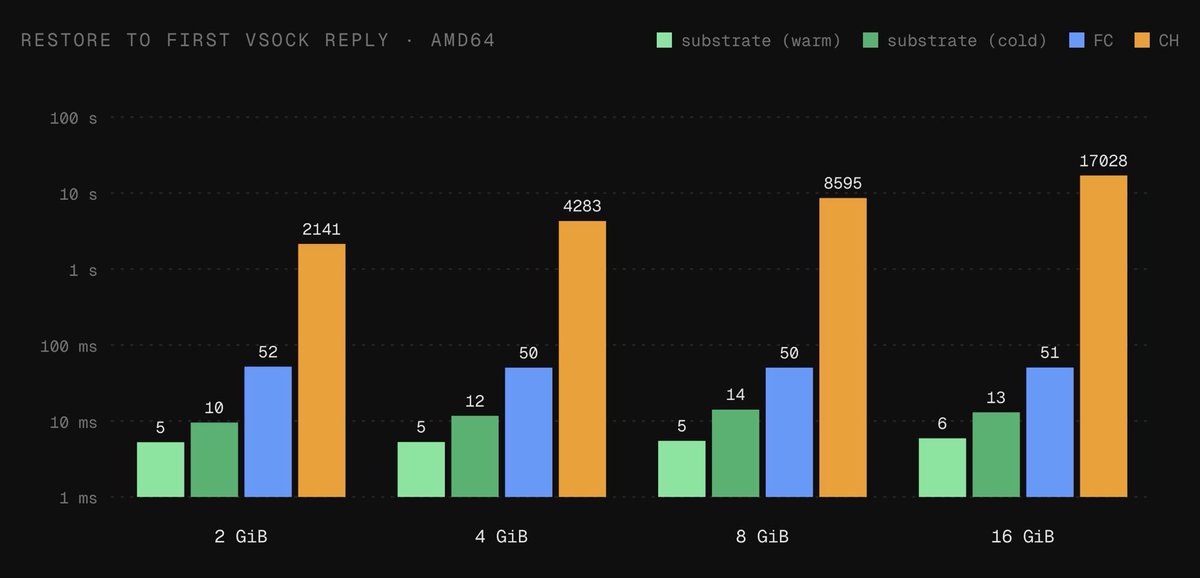
I may be a bit late to the “time to interactive” agent sandbox party, but I wanted to make sure our hypervisor absolutely MOGGED everyone else.
10x faster than Firecracker and 425x faster than Cloud Hypervisor.
agx.so is the best agent infra platform, period.
7
5
31
9,611
Peter Pistorius retweeted

Jun 12
the average virtual machine (EC2) look like boxes - you the CPU and Memory and that's how much you get.
I built smol machines because I disagree with that rigid thinking.
Virtual machines should actually be like balloons that grow and shink with the application inside it.
We don't think about the cpu count or memory for youtube - we just want it to run!
Here's me running like 7 smol machines with agents inside - one of them uses as little as 4.3MB when it's not doing anything!

2
2
27
6,530

Jun 13
if I get an american friend to run mythos prompts for me, a south african, is that now considered illegal?
6
5
825
Peter Pistorius retweeted

Jun 13
when i wrote this back in march; i thought it would be years but we are now here. ghuntley.com/warfare/

4
5
60
2,689
Jun 13
Machinen VM's source is now available. This is a "slopvm" that I've been working on for the past month to teach myself more about computers.
It's written in zig with Tigerstyle, and has a really nice Typescript runtime!
1. It's does incremental snapshots and forking.
2. It boots fast. (last I checked it was 200ms)
3. It uses HVF and KVM's native snapshots and translates between the two operating systems.
4. I am playing around with a new idea to move running binaries across architectures.
5. It has nested virt, so you can run firecracker inside of machinen.
6. It does not support OCI.
The main idea is that you should not be coding on your raw machine anymore. Most VM developers are trying to sell you cloud compute, I'm trying to get you to use your own compute more effectively.
github.com/redwoodjs/machine…
4
8
80
7,060
Jun 12
I've got an experiment running to make RedwoodSDK use the official @vite_js RSC runtime. So far it's panning out. If we're able to do this I'll further break apart the SDK features into bespoke packages: router, client nav, db, realtime, etc.
4
14
1,391

Peter Pistorius retweeted

Jun 12
We're getting more and more amazing companies interested in sponsoring and attending Git Merge this year.
It feels like a renaissance in this space that I haven't seen in a decade.
If you have something cool to talk about in the Git world, put in your talk via our CFP, I would love to hear about it.
git-merge.com/
1
3
22
2,433
Jun 12
I’ve been chasing the holy grail: cross-arch snapshot/restore: Start a process on arm64, freeze it, then resume it on amd64.
Copying memory/registers across architectures does not work. App-level checkpoints are too fragile.
The approach that I think will work: process continuation:
Inspect the process, model its resources, reject unsafe state, rebuild what we understand, run target-native code, and prove it continued.
2
10
877
Jun 12
Got some really great feedback about Machinen today. I've got people trying things that I couldn't even imagine:
They snapshot a machinen, move it next to the database, run a query - snapshot it - and bring it back... and it's faster than running the query over the wire.
3
6
926
Jun 12
The goal here is framework no lock in. You shouldn't be stuck in RedwoodSDK just because you like the API shape. This isn't exactly true because we built it to be composable, but it's not a blessed path.
2
361
Jun 10
1
330

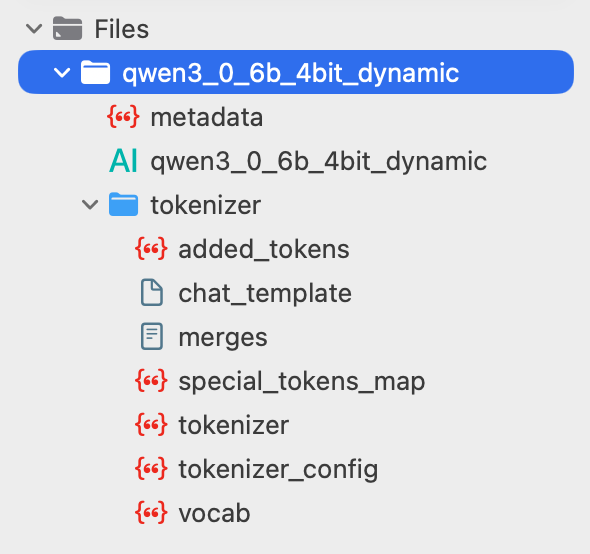
This is what AI deployment is starting to look like
Not a notebook
Not a Hugging Face model card
An actual deployable artifact!
Qwen3 → Core AI → Xcode
The model gets quantized, packaged with its tokenizer, converted into an executable graph, specialized for the target Apple device, and then cached for future runs.
The more I learn about Core AI, the more it feels like Apple is treating AI models the same way traditional software is treated:
Build → Compile → Optimize → Deploy
That's a fascinating shift
The .aimodel might end up becoming as important to AI apps as .app bundles are to traditional software 👀
#wwdc26


Spent some time digging into Apple's new Core AI framework, and I think it's much more important than it initially appears
At first glance, it looks like "just another inference framework." It's not !!
Core AI is essentially Apple's production stack for running AI models on Apple Silicon, and it's the same framework powering Apple Intelligence
A few things stood out:
- Models can be developed in PyTorch and converted directly into Core AI models
- Inference automatically utilizes CPU, GPU, and Neural Engine without developers manually orchestrating hardware
- Core AI introduces first-class support for model states, which is particularly interesting for transformer workloads
Another interesting concept is model specialization. The model you ship isn't the exact model that ultimately runs on the user's device
Core AI ships a portable representation, then specializes it for the specific hardware and OS version. The specialized artifact is cached, which explains why the first load may take time but subsequent loads are much faster
Apple also exposes APIs to:
- Trigger specialization ahead of time
- Inspect specialization caches
- Share caches across app groups
- Manage cache persistence
This feels very similar to how serious inference systems think about compilation and deployment rather than just model execution
The other thing I found interesting is how Core AI fits into Apple's broader AI stack
MLX helps you train, fine-tune, and experiment with models
Core AI helps you deploy, optimize, specialize, debug, and run them efficiently on Apple devices
That's a much cleaner separation than I initially understood
The biggest takeaway for me is that Apple seems less focused on winning the "best model" race and more focused on building the infrastructure required to run AI locally at scale
And after looking at features like state management, specialization, ahead-of-time compilation, caching, dedicated profiling tools, and Metal-backed custom kernels, it's clear they're investing heavily in that layer

1
2
34
2,320
Jun 10
Models are just like haircuts. You should be trying all of them. I only do month-to-month subscriptions.
2
5
314