
Assistant Professor at UC Berkeley
Joined January 2016
- Tweets 93
- Following 187
- Followers 1,070
- Likes 208
36 Photos and videos







Aditi Krishnapriyan retweeted

Mar 30
Code for our new world model planner is live! github.com/michael-psenka/gr…
Includes our implementation on dino-wm, as well as implementations on jepa-wm and le-wm, and minimal pseudocode for anyone to re-implement themselves.
Feb 6

tl;dr New planner for world models! GRASP: gradient-based, stochastic, parallelized.
Long range planning for world models has always been an issue. 0th order methods like CEM/MPPI dominate, but have degrading performance at longer contexts or higher-dimensional actions. We wanted to address this from the ground up.
w/ Michael Rabbat, @ask1729 , @ylecun*, @_amirbar* (equally advised)
6
21
147
43,596

2 Dec 2025
1/ How can we improve our models of the physical world? We develop EddyFormer: integrating spectral methods w/ the Transformer architecture. We can accelerate 3D turbulence simulation by up to 30x compared to top numerical solvers, at the same level of accuracy!
At #NeurIPS2025 on Dec 4 at 4:30 PM, Exhibit Hall C, D, E: #2316
Project page: mrlazy1708.github.io/eddyfor…
7
38
209
20,002
2 Dec 2025
2/ EddyFormer can resolve solutions to fluid dynamics problems that other ML models fail to converge on (taken from the Well). It can also generalize to larger spatiotemporal domains than what it was trained on.
1
1
9
805
2 Dec 2025
3/ This project was lead by Yiheng Du, with:
Paper: openreview.net/forum?id=bla5…
Code: github.com/ASK-Berkeley/Eddy…
1
8
594
20 Nov 2025
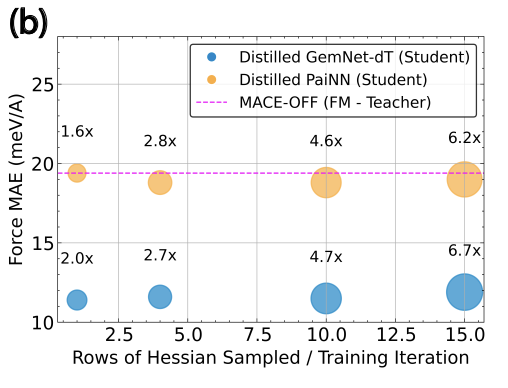
At this point the AI for Science community should stop focusing on achieving "state-of-the-art” on datasets like QM9 & MD17: chasing small improvements on these outdated datasets is scientifically meaningless. It's like telling vision researchers to ditch internet-scale and go back to benchmarking on MNIST/CIFAR10
6
20
127
24,055
20 Nov 2025
(Inspired by ongoing thoughts about the state of the field, including discussions w/ @Andrew_S_Rosen, @SamMBlau, @bwood_m many others)
7
2,074
Aditi Krishnapriyan retweeted

3 Oct 2025
I value approaches that work by subtraction: stripping away the unnecessary until the essential insight remains. Doing less often demands more: a deeper understanding of data and method to reveal the simplest formulation at the core.
This is an attempt of ours. Hope it resonates.
3 Oct 2025

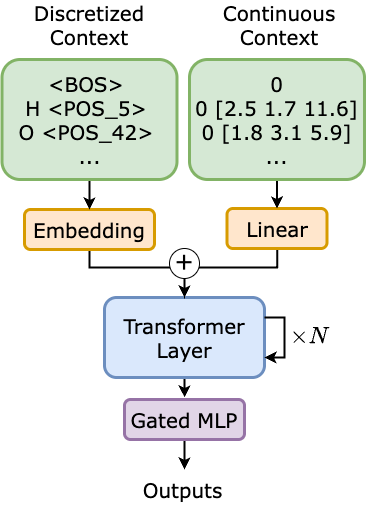
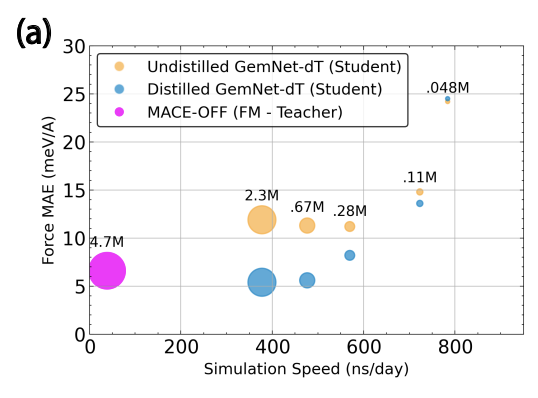
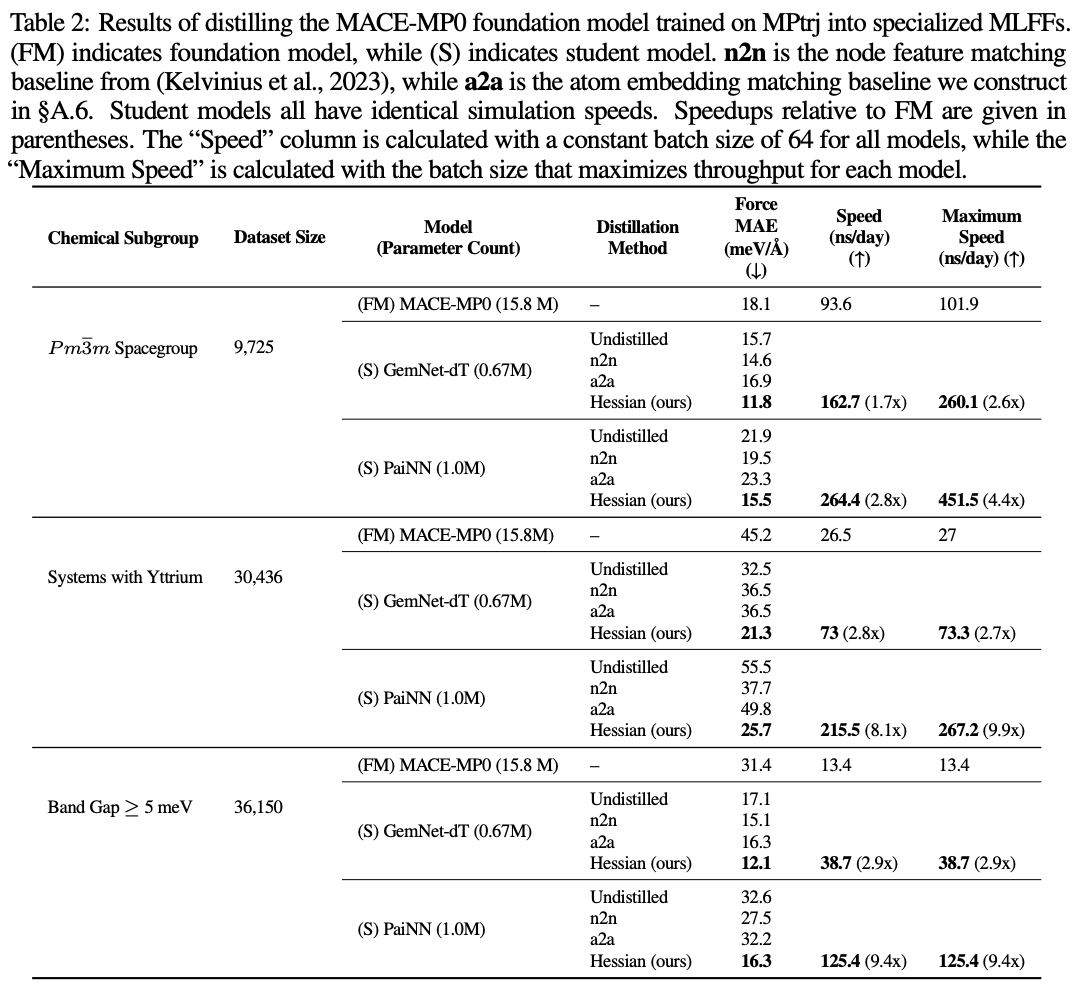
1/ Can molecular AI move past hard-coded Graph Neural Networks and embrace scalable Transformers that discover molecular structure on their own?
We demonstrate that you can train a 1B parameter Transformer model without any graph priors or physical inductive biases.
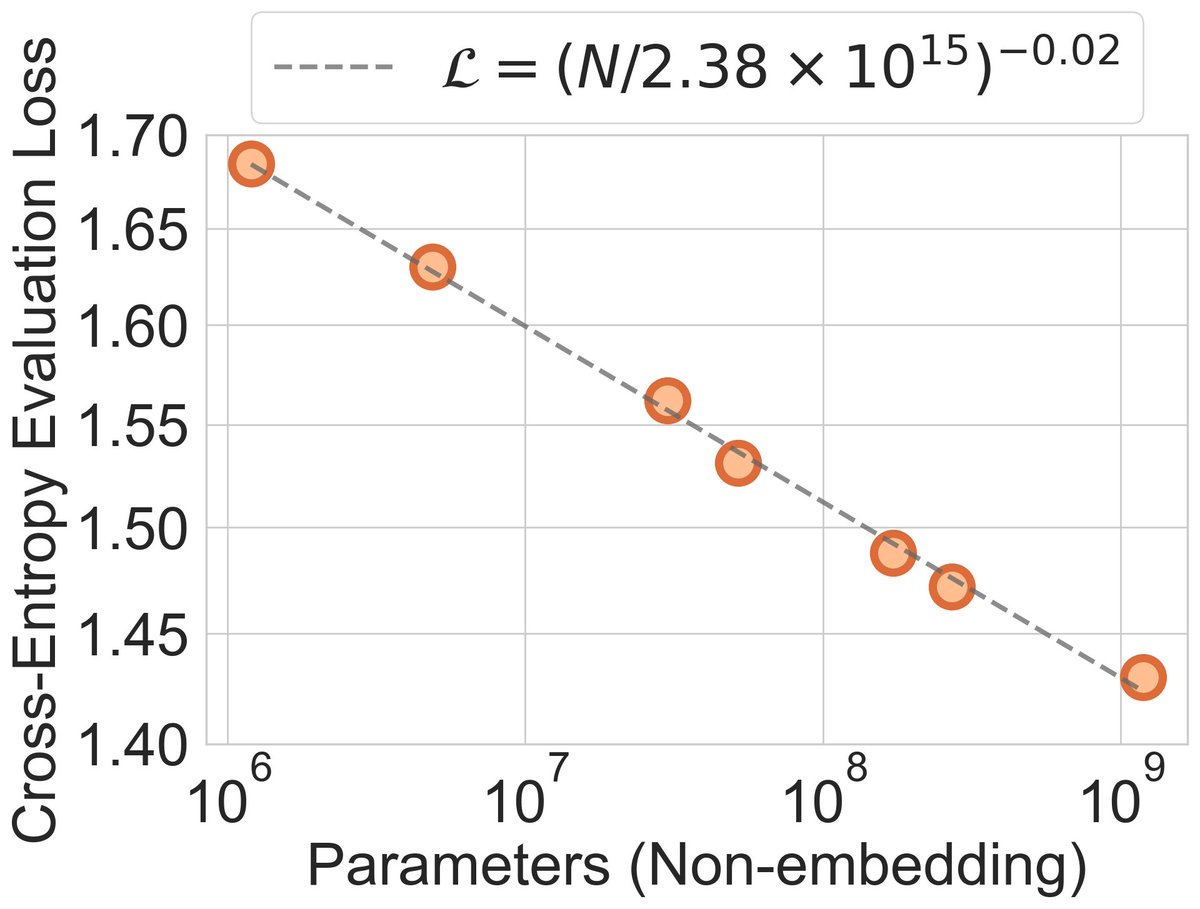
And surprisingly, not only can it maintain competitive performance under equal compute on the Open Molecules 2025 dataset… it’s faster than a 6M parameter equivariant GNN, and exhibits scaling laws that don’t saturate. We use this as a starting point to investigate emergent internal representations, and find that it adaptively discovers molecular structure!
Check out the interactive demo on our website: tkreiman.github.io/projects/…
And our paper: arxiv.org/abs/2510.02259
In collaboration with @tobykreiman, @YutongBAI1002, Fadi, Elizabeth, and @EricQuCal.
Here’s a video showing how the Transformer learns distance-aware attention patterns (purple gradient) that adapt to atomic environments 👇
1
8
87
17,509
3 Oct 2025
1/ Can molecular AI move past hard-coded Graph Neural Networks and embrace scalable Transformers that discover molecular structure on their own?
We demonstrate that you can train a 1B parameter Transformer model without any graph priors or physical inductive biases.
And surprisingly, not only can it maintain competitive performance under equal compute on the Open Molecules 2025 dataset… it’s faster than a 6M parameter equivariant GNN, and exhibits scaling laws that don’t saturate. We use this as a starting point to investigate emergent internal representations, and find that it adaptively discovers molecular structure!
Check out the interactive demo on our website: tkreiman.github.io/projects/…
And our paper: arxiv.org/abs/2510.02259
In collaboration with @tobykreiman, @YutongBAI1002, Fadi, Elizabeth, and @EricQuCal.
Here’s a video showing how the Transformer learns distance-aware attention patterns (purple gradient) that adapt to atomic environments 👇
6
32
174
39,286
3 Oct 2025
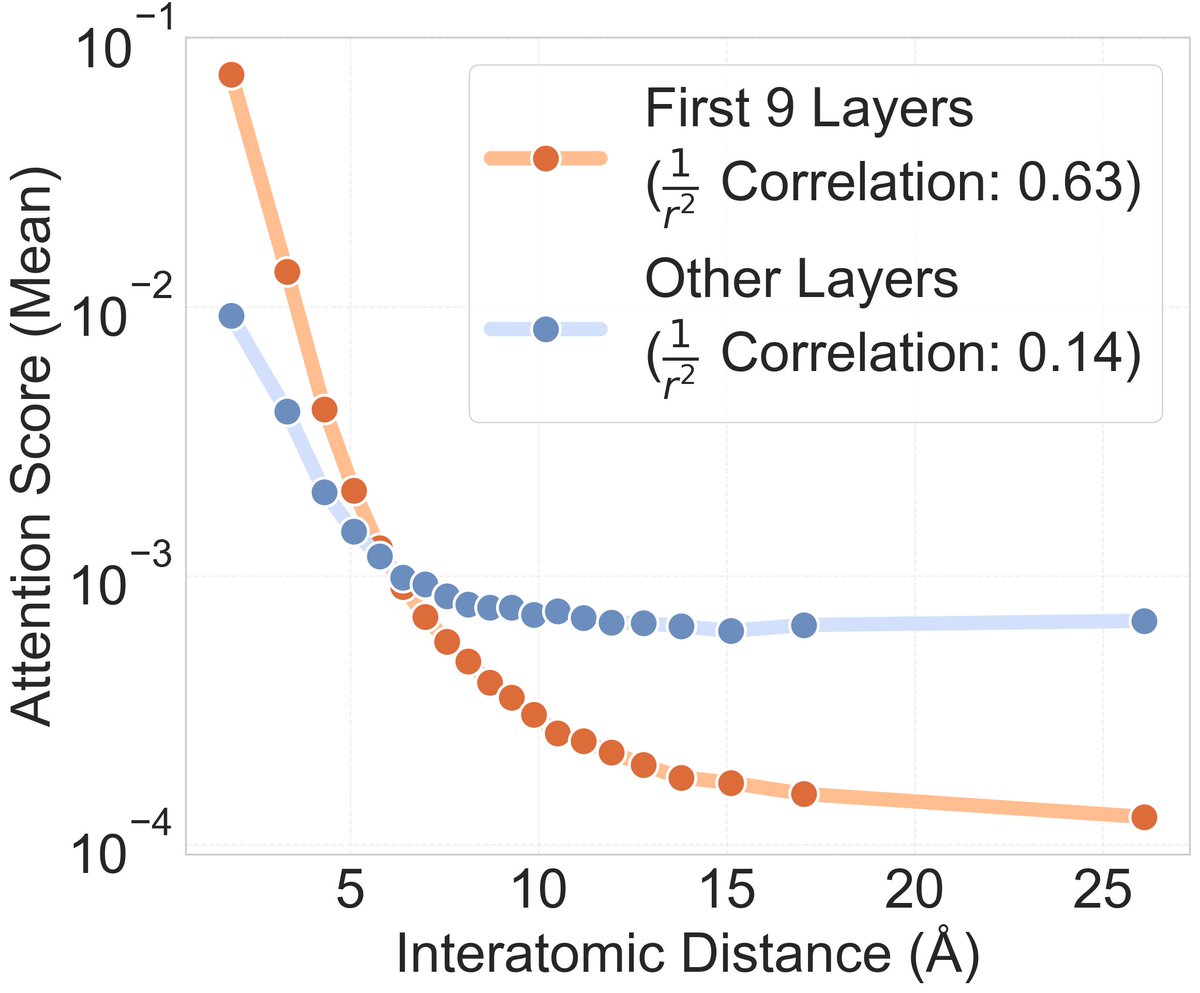
5/ We really do mean an unmodified Transformer: no explicit calculation of pairwise distances, no graph-based features, no rotational equivariance, etc. Leveraging modern software and hardware, a 1B parameter Transformer trains and runs inference faster than a 6M parameter equivariant GNN.
1
11
1,103
3 Oct 2025
6/ Our results demonstrate that many favorable properties of GNNs can emerge adaptively and more flexibly in Transformers, challenging the necessity of hard-coded graph inductive biases and pointing toward standardized, scalable architectures for molecular modeling. This has been a hot topic in the community, and we hope that this adds more to the discussion!
1
9
900
26 Jun 2025
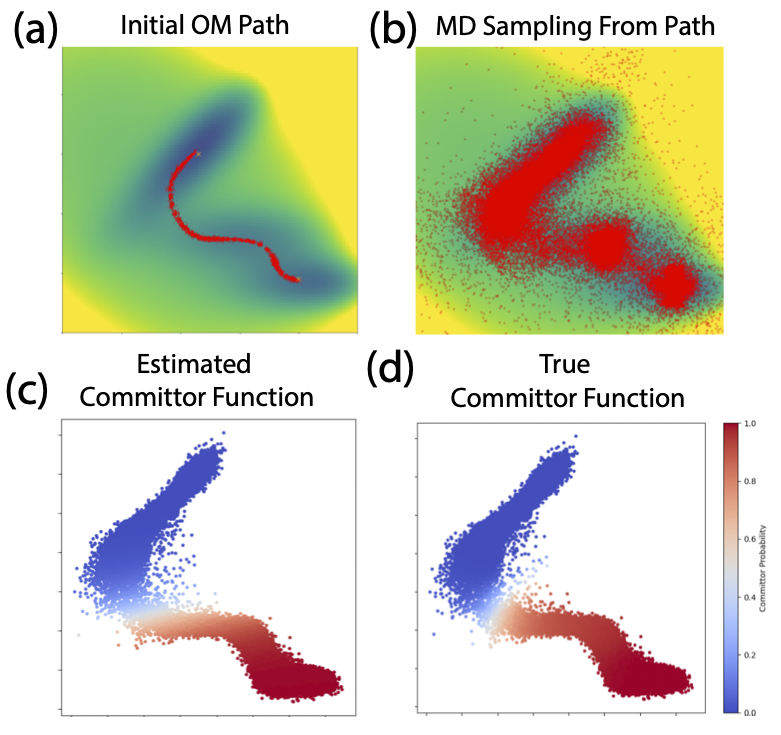
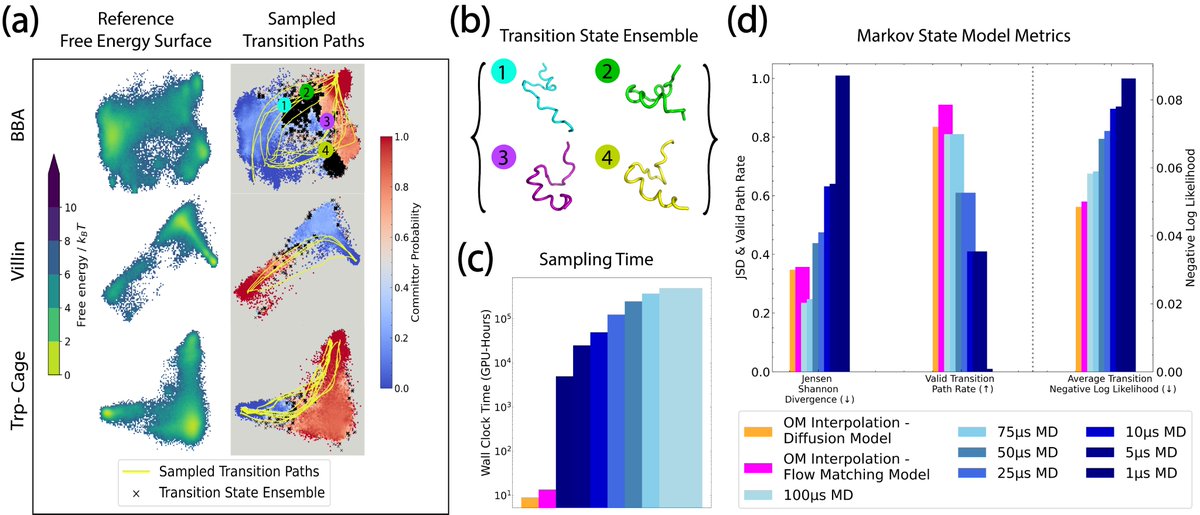
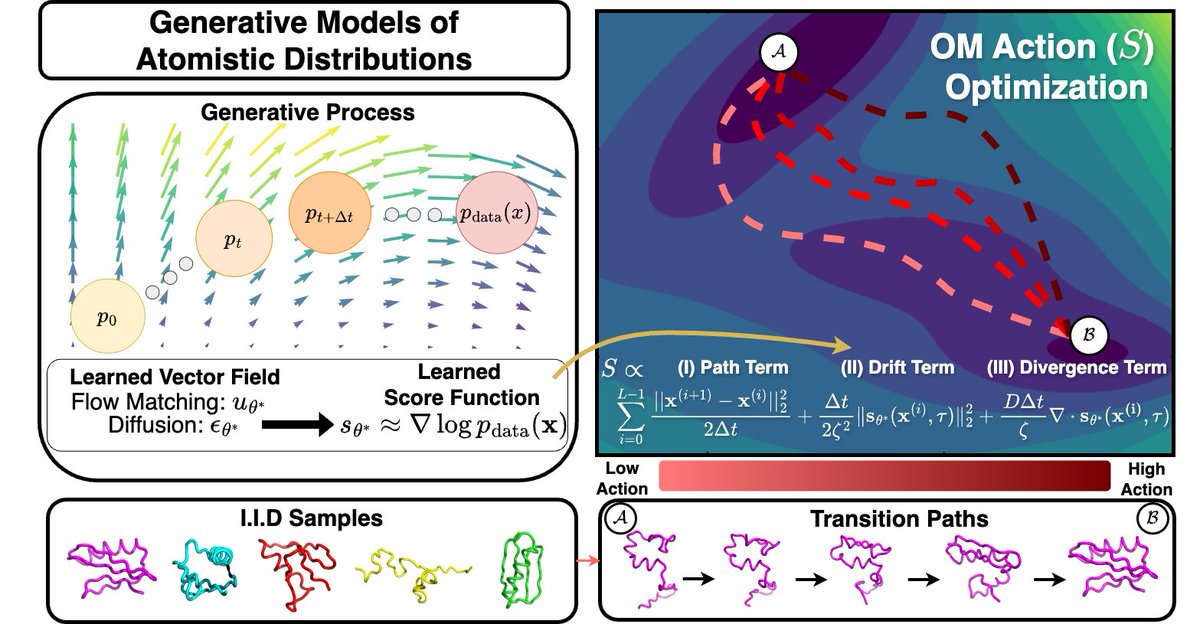
1/ Generating transition pathways (e.g., folded ↔ unfolded protein) is a huge challenge: we tackle this by combining the scalability of pre-trained, score-based generative models and statistical mechanics insights-—no training required! To appear at #ICML2025
2
32
247
20,687
26 Jun 2025
8/ Our method is a way to turn any score-based generative model of IID molecular configurations into an efficient hypothesis generator for dynamical events, without system-specific training. We're excited to advance this method as generative models continue to scale and improve!
1
3
968
26 Jun 2025
9/ This was a very fun project to work on with an amazing team (Sanjeev Raja, Martin Sipka, Michael Psenka, Toby Kreiman, Michal Pavelka) and a great way to explore statistical physics generative modeling connections!
Paper: openreview.net/forum?id=QwoG…
14
908