
High fidelity research
Joined November 2023
- Tweets 2,271
- Following 51
- Followers 44,750
- Likes 3,702
1,029 Photos and videos














Pinned Tweet

May 12
Reinforcing Recursive Language Models
Can a 4B model learn to recursively call itself to answer hard long-context questions?
We RL fine-tuned a small model to behave as a native RLM.
On evidence selection across scientific papers, our 4B RLM matches Sonnet 4.6 in quality while running significantly faster and cheaper.

13
69
484
68,778
14h
"From AGI to ASI"
This paper from Google DeepMind defines how AGI is one human-level general system, and ASI is a system or collective that beats large expert human organizations across almost everything.
They argue that the jump may come from scaling, new paradigms, recursive self-improvement, or huge multi-agent AI collectives.
With the key idea that digital minds can copy, speed up, share memory, and run in parallel, so superintelligence may look less like one breakthrough and more like accelerating AI civilization.
9
53
272
12,001
14h
"MiniMax Sparse Attention"
This paper from Minimax adds a tiny Index Branch to GQA that picks top k KV blocks per group, then runs exact softmax only on those blocks, making sparsity GPU native, with exp free TopK and KV outer sparse kernels.
On a 109B multimodal MoE, it keeps dense GQA quality while cutting 1M context attention compute by 28.4x, with 14.2x prefill and 7.6x decode speedups.
5
26
226
7,089
Jun 12
"Test-Time Gradient Guidance of Flow Policies in Reinforcement Learning"
This paper uses expressive flow policies for RL without making policy training fragile.
So they don't train the policy with actor critic updates which is unstable, they instead train the policy with plain behavior cloning and improves it only at test time.
The key idea is to guide each denoising step with a critic gradient, but compute that gradient on an approximate clean action rather than a potential noisy intermediate action.
This avoids bad OOD gradients and expensive backprop through denoising, while still getting strong offline RL performance.
4
26
212
10,004
alphaXiv retweeted
Jun 11
The best way to understand frontier research is to build it yourself.
And now, we're back again with another competition, with upgraded prizes.
alphaXiv x @marimo_io are launching the second molab Notebook Competition: Bring Research to Life.
Pick any paper on alphaXiv, build a marimo notebook that makes the core idea interactive, reproducible, and easy to understand, then submit your molab link.
No need to fully reproduce the paper, as the goal is to bring one key contribution to life with code, UI elements, and clear explanations. Bonus points if you add your own twist, like a variant, extension, or new dataset.
And this time, molab runs on GPUs.
That means transformers, diffusion models, larger-scale experiments, training, inference, and more ambitious research demos are all fair game!
Prizes include:
🥇 Framework Laptop 13 marimo swag social shoutouts
🥈 Claude Max Pro for 3 months marimo swag social shoutouts
🥉 Claude Max 5x for 3 months marimo swag social shoutouts
Deadline: June 28, 11:59 PM PST
Individual and team submissions are welcome.
Submit your notebook video explainer through the JotForm.
Full details below 👇
5
7
102
8,884
Jun 11
The best way to understand frontier research is to build it yourself.
And now, we're back again with another competition, with upgraded prizes.
alphaXiv x @marimo_io are launching the second molab Notebook Competition: Bring Research to Life.
Pick any paper on alphaXiv, build a marimo notebook that makes the core idea interactive, reproducible, and easy to understand, then submit your molab link.
No need to fully reproduce the paper, as the goal is to bring one key contribution to life with code, UI elements, and clear explanations. Bonus points if you add your own twist, like a variant, extension, or new dataset.
And this time, molab runs on GPUs.
That means transformers, diffusion models, larger-scale experiments, training, inference, and more ambitious research demos are all fair game!
Prizes include:
🥇 Framework Laptop 13 marimo swag social shoutouts
🥈 Claude Max Pro for 3 months marimo swag social shoutouts
🥉 Claude Max 5x for 3 months marimo swag social shoutouts
Deadline: June 28, 11:59 PM PST
Individual and team submissions are welcome.
Submit your notebook video explainer through the JotForm.
Full details below 👇
5
7
102
8,884
Jun 11
Check out our list of suggested papers to implement here! alphaxiv.org/shared/folder/0…
9
1,080
alphaXiv retweeted

Jun 10
We ran a competition where you had to implement a research paper and make it interactive. Round two is live, this time with GPU access on molab.
Pick an @askalphaxiv paper, build a marimo notebook, win a @FrameworkPuter Laptop 13, @claudeai subscriptions, and more.
Deadline: June 28 👀
3
10
30
2,996
alphaXiv retweeted

Jun 11
Reading a research paper alone is brutal. Someone built a free site that turns arXiv into something you can actually understand.
It's called alphaXiv.
arXiv is where nearly every AI breakthrough gets posted first, before any blog or news site touches it. The problem is the papers are dense, jargon-heavy, and silent. No comments, no context, no help.
alphaXiv fixes all of that.
- A trending feed that ranks the hottest papers so you see what matters today
- Every paper gets a plain-language overview, so you grasp it before reading the math
- Comment on any line of any paper and discuss it with other researchers
- An AI search that answers questions like "what are the top math reasoning benchmarks"
- Audio versions of papers, so you can listen to research like a podcast
- A Chrome extension that adds all of this on top of arXiv itself
It started as a Stanford student project and became the place researchers actually talk to each other.
The cutting edge of AI is published for free every single day. This is how you finally keep up with it.
alphaxiv.org/

4
13
36
2,561
Jun 11
"Still: Amortized KV Cache Compaction in a Single Forward Pass"
Instead of dropping tokens or optimizing a new compressed cache per prompt, Still learns to synthesize a compact KV cache in one forward pass.
So a small per layer Perceiver reads the full cache and writes compressed keys and values the frozen model can still attend to, avoiding the KV cache bottleneck in long context inference.
This turns token eviction to learned memory synthesis, making long context cheaper while preserving more context understanding.
3
27
159
7,854
alphaXiv retweeted
Jun 10
As believers of open research, we are disappointed to see Anthropic silently degrading Fable 5 for AI development
"Any topic related to building pretraining pipelines, distributed training infrastructure, or ML accelerator design... may have limited effectiveness through Claude via methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning."
Not only do they get to decide what you use LLMs for in research, but this also enables them to silently intervene in your research without you knowing.
This sets a dangerous precedent. If a model refuses openly, users can understand the boundary. If a model falls back to another model, users can still evaluate the difference. But if a model silently modifies or weakens its own answers while still pretending to help, researchers lose the ability to know whether a failed result came from their own idea, their implementation, or an invisible intervention by the model provider.
That is not safety. Safety policies should be transparent, auditable, and user-visible.
On top of that, the people most harmed by this are not the largest labs with massive teams and proprietary infrastructure. It is the independent researchers, academic groups, startups, and open-source builders who rely on public tools to compete, innovate, and pioneer AI for everyone else.
166
718
3,861
219,440
Jun 10
"Self-Harness: Harnesses That Improve Themselves"
What if an AI agent improves the harness that controls how it acts?
So instead of humans tuning prompts, tools, retry rules, and verification for every model, this paper explores letting the agent mines its own failures, proposes small harness edits, and keeps only the ones that pass regression tests. All without fine-tuning or teacher model.
On Terminal-Bench-2.0, it improves held-out pass rates across MiniMax, Qwen, and GLM.
16
49
369
18,613
Jun 10
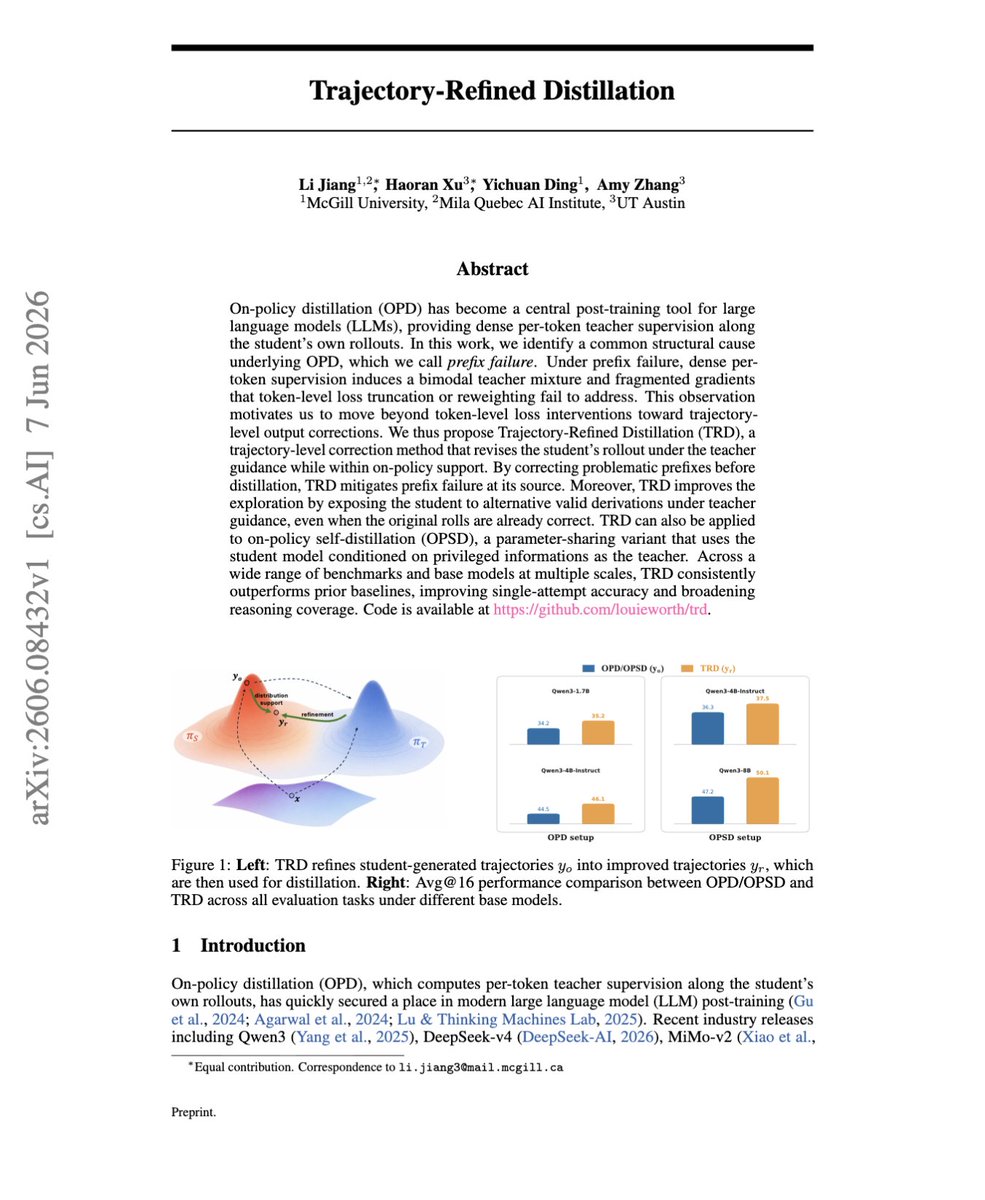
"Trajectory-Refined Distillation"
This paper shows a core failure in on-policy distillation.
When a student takes a wrong reasoning path, the teacher is forced to supervise from that broken prefix, so token-level KL becomes noisy.
So they introduced TRD that fixes this by refining the whole rollout first.
What it does is the teacher rewrites the student trajectory into a better reasoning path, then the student distills from that corrected trajectory.
While this is a small change, it still moves distillation from token fixes to trajectory fixes, giving cleaner supervision and stronger reasoning gains.
8
47
366
29,091
alphaXiv retweeted

Jun 9
First they came for the model builders...
I feel we're getting a glimpse of a future where AI is only provided to a privileged few, and that's not a future I want to live in.
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

22
104
846
68,980