
Joined September 2007
- Tweets 190
- Following 295
- Followers 199
- Likes 401
2 Photos and videos


Michael I Mandel retweeted

23 Jul 2025
We’re thrilled to see our advanced ML models and EMG hardware — that transform neural signals controlling muscles at the wrist into commands that seamlessly drive computer interactions — appearing in the latest edition of @Nature.
Read the story: nature.com/articles/s41586-0…
Find more details on this work and the models on @github: github.com/facebookresearch/…
49
267
1,274
169,150
Michael I Mandel retweeted

5 Dec 2024
1/
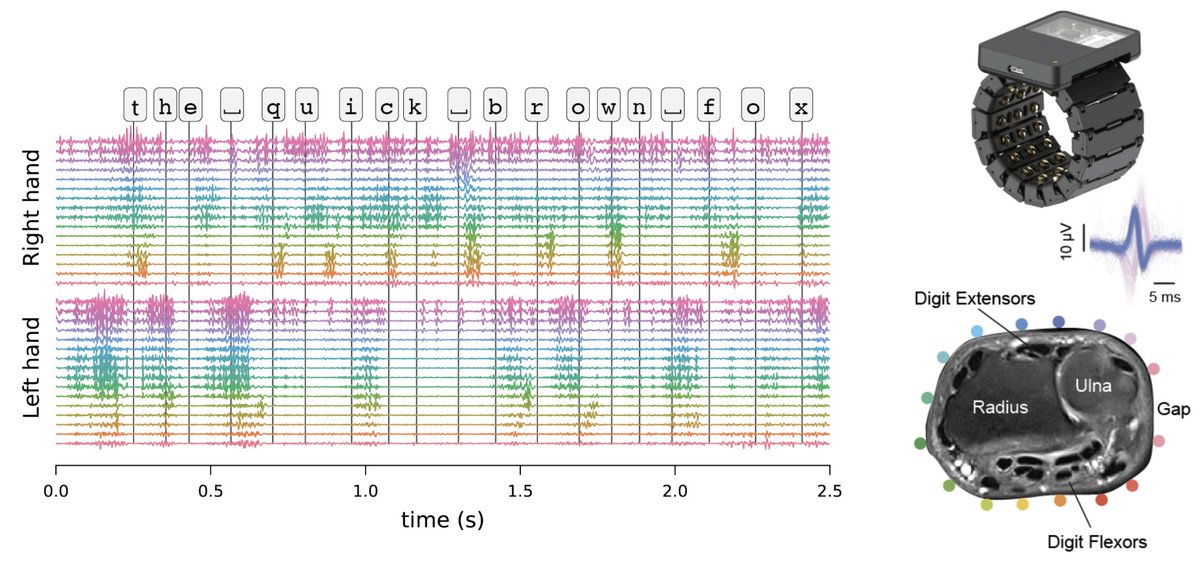
We just open-sourced two large wrist electromyography (EMG) datasets - one towards typing without a keyboard and the other for predicting hand poses - with baselines.
We believe these will help advance research into making high bandwidth non-invasive neuromotor interfaces a reality!
1
20
50
5,674
Michael I Mandel retweeted

19 Mar 2024
You might think speech recognition is "solved" with models such as @OpenAI’s Whisper, but it's not. Natural conversations with distant microphones still lack effective solutions.
To illustrate, on our newly released NOTSOFAR meeting benchmark, Whisper large-v3 with head-mounted mics achieves 9.3% WER (word-error-rate), yet on audio from a distant mic it climbs to 37.4% WER. The culprits are reverberation, noise, and overlapping speech, which interfere with the source signal.
What's the missing ingredient? We believe it's datasets.
The problem is not amenable to web scraping. Benchmarking datasets are scarce given their complex collection process. Microphone arrays, useful for speech separation, are rarely featured in labeled datasets, necessitating simulation to teach neural networks to utilize such arrays.
To bridge the gap our team at @Microsoft has released a benchmarking dataset of 280 recorded meetings, and a 1000-hour simulated training set synthesized for real-world generalization.
Join our challenge "NOTSOFAR: Distant Meeting Transcription with a Single Device", part of CHiME-8, to explore these resources and advance the field.
Details and registration: aka.ms/chime8
Code and datasets: aka.ms/notsofar

1
14
38
9,071
Michael I Mandel retweeted

28 Feb 2024
1/7
For the past decade, our team at Meta Reality Labs (previously CTRL-labs) has been dedicated to developing a neuromotor interface.
Our goal is to address the Human Computer Interaction challenge of providing effortless, intuitive, and efficient input to computers.
55
386
1,769
642,133
Michael I Mandel retweeted

1 Sep 2022
Teaching DSP this Fall, so I'm relaunching my YouTube video series. If you/your colleagues are teaching DSP this year, your students might find useful. Pls LMK any errors, feedback, & requests for future videos!
Course info here:
creating-at-a-distance.com/a…
youtube.com/playlist?list=PL…
1
7
32
Michael I Mandel retweeted

16 Jun 2022
Please check!
16 Jun 2022

Call for proposals!
We now wish to introduce a more open model, where the annual CHiME Challenge features independent tasks organized by teams who work within a schedule defined by the CHiME Steering Group. See chimechallenge.org/current/c…
1
5
Michael I Mandel retweeted
11 Mar 2022
@asterix77 and I gave a talk at @Mila_Quebec covering some of our work at @RealityLabs towards building non-invasive neural interfaces using electromyography (EMG): sites.google.com/lisa.iro.um…
Full talk: bluejeans.com/playback/s/JCb…
1
1
2
Michael I Mandel retweeted

11 Mar 2022
Want to know what we're up to in the neural interfaces group at @RealityLabs?
-> Two members of the team I'm on recently gave a talk at @Mila_Quebec, check out our work on non-invasive neural interfaces:
bluejeans.com/playback/s/JCb…
2
8
59
Michael I Mandel retweeted

8 Nov 2021
🧵 The #ismir2021 conference is underway! Here’s what’s happening with #WiMIR and Diversity & Inclusion around the conference... @ismir2021 #WomenInTech #WomenInStem #DiversityAndInclusion 1/ ismir2021.ismir.net/
1
5
8
Michael I Mandel retweeted

27 Feb 2021
Come join myself and @asterix77 as @eva_zangerle rotates off this super interesting and important committee.
27 Feb 2021

Join us! Women in Music Information Retrieval (WiMIR) is seeking motivated peers to join the Mentoring Program organizing committee. Signups close March 15, 2021.
More information and signup below. #WiMIR #ISMIR2021 @ismir2021
wimir.wordpress.com/2021/02/…
2
5
Michael I Mandel retweeted
17 Oct 2020
While @ismir2020 has come to a close, the sixth round of #WiMIR mentoring is just beginning!
GET a mentor here!
bit.ly/31ewCMP
Sign up to be a mentor here!
bit.ly/351yXfq
Submissions close on Dec. 15, with matches announced in Jan 2021.
#WomenInSTEM
1/3

1
14
14

22 Nov 2019
Announcing the CHiME-6 Speech Separation and Recognition Challenge: spandh.dcs.shef.ac.uk/chime_…
Track 1: (repeat of CHiME-5) multichannel, multi-device speech recognition at dinner parties
Track 2: same, but with multichannel, multi-device speaker diarization first
1
3
8
18 Dec 2019
Full #chimechallenge software baseline released in Kaldi. Instructions at chimechallenge.github.io/chi…
22 Nov 2019
Also announcing the CHiME 2020 workshop on Speech Processing in Everyday Environments at Universitat Pompeu Fabra, Barcelona, May 4, 2020 (satellite to ICASSP 2020) spandh.dcs.shef.ac.uk/chime_…
1
8
10
18 Dec 2019
Keynote speakers announced for #chimeworkshop 2020: Paola García (Johns Hopkins University) and Dong Yu (Tencent AI Lab)
1
22 Sep 2019
On 9/27, I'll be taking the stage at @betaworkstudios for RENDER: Hearing Voices, a day-long conference exploring the future of audio.
Join me for the conversation, IRL or by livestream 👇
🎟 beta.works/hearingvoices
1
13
Michael I Mandel retweeted

23 Mar 2019
Please consider submitting to the #DCASE2019 workshop that we're organizing at NYU. The workshop immediately follows both #WASPAA and #SANE2019, all in NY. Come to all 3!
22 Mar 2019

Just sent out the first Call for Papers for the #DCASE2019 workshop (dcase.community/workshop2019…), looking forward to some great submissions! #machinelistening
justinsalamon.com/news/dcase…
2
8
14
Michael I Mandel retweeted

29 Dec 2018
To close out 2018, we're revisiting our favorite #BCfamily highlights from the year! In October, CIS associate professor @asterix77 secured a five-year, $500,000 @NSF grant to analyze audio recordings from the Alaskan wilderness. Congratulations, Michael! brooklyn.cuny.edu/web/news/b…
3
13
28 Feb 2018
Congrats to @Sophia_NLP on her successful defence! x.com/Sophia_NLP/status/9686…
27 Feb 2018

Defended! Sincerest thanks to my dissertation committee @asterix77 @andrewmaxr @rivkalevitan @ChangheYuan and our speech lab!!

1