
Photos and videos

Excited to announce our new LLM inference algorithm, speculative speculative decoding (SSD)!
It is fast 🚀 — up to 2x faster than state-of-the-art inference engines (vLLM, SGLang).
Working on this with @tanishqkumar07 and @tri_dao was a blast.
Details in thread:
Mar 4

I've been working on a new LLM inference algorithm.
It's called Speculative Speculative Decoding (SSD) and it's up to 2x faster than the strongest inference engines in the world.
Collab w/ @tri_dao @avnermay. Details in thread.
19
44
666
59,018
I'm at @iclr_conf in Rio, and am excited to be presenting our Speculative Speculative Decoding (SSD) work tomorrow from 10:30 am - 1 pm (Pavilion 3 P3, #1803).
Come by to learn how we're attaining 30% speedup on average over SGLang 🚀
Collab w/ @tanishqkumar07 @tri_dao.

Excited to announce our new LLM inference algorithm, speculative speculative decoding (SSD)!
It is fast 🚀 — up to 2x faster than state-of-the-art inference engines (vLLM, SGLang).
Working on this with @tanishqkumar07 and @tri_dao was a blast.
Details in thread:
1
17
1,065
Excited to announce our new LLM inference algorithm, speculative speculative decoding (SSD)!
It is fast 🚀 — up to 2x faster than state-of-the-art inference engines (vLLM, SGLang).
Working on this with @tanishqkumar07 and @tri_dao was a blast.
Details in thread:
Mar 4
I've been working on a new LLM inference algorithm.
It's called Speculative Speculative Decoding (SSD) and it's up to 2x faster than the strongest inference engines in the world.
Collab w/ @tri_dao @avnermay. Details in thread.
19
44
666
59,018
One thing that excites me about this algorithm is that the large improvement in latency does not come at the cost of lower throughput. This is possible because—unlike other approaches like tree verification—SSD does not require additional compute by the target model. It only increases the compute required for the speculator, which is much faster and cheaper.
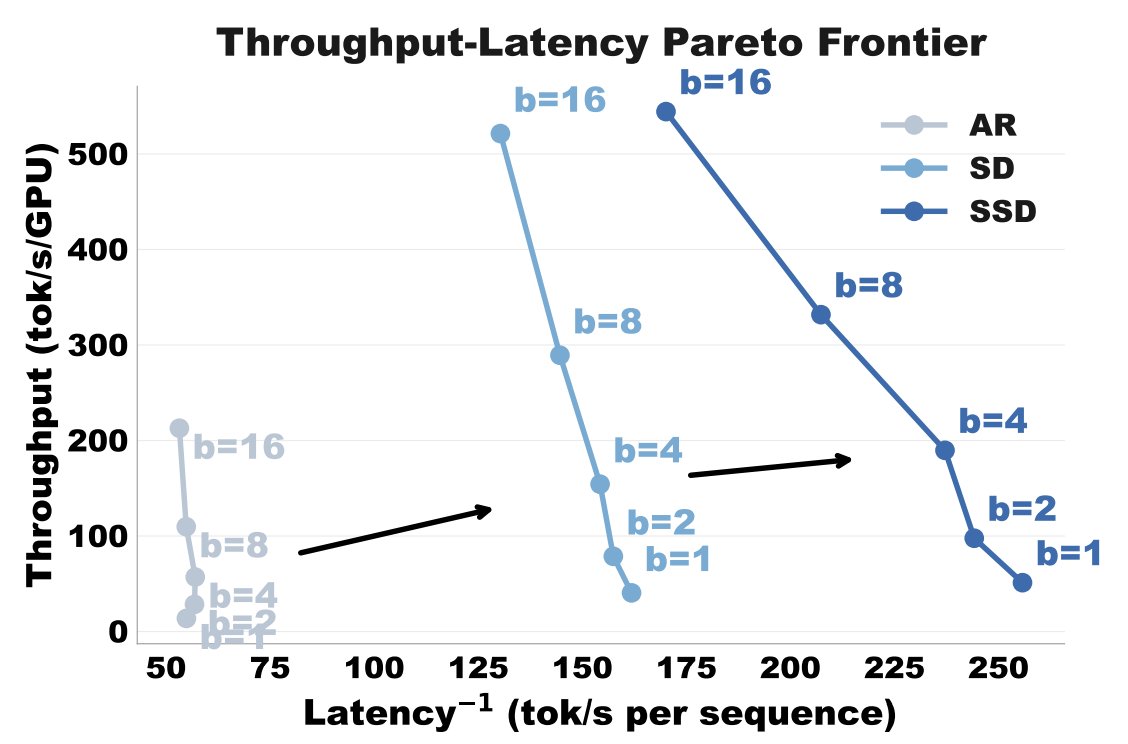
1
7
1,059
To learn more, please take a look at our paper, and feel free to reach out with any questions!
arXiv: arxiv.org/pdf/2603.03251
code: github.com/tanishqkumar/ssd
9
903
Avner May retweeted

10 Oct 2025
What if your LLM inference automatically got faster the more you used it?
Introducing ATLAS from the Together AI Turbo research team.
Read more: togetherai.link/atlas
Here’s Together AI Founder and Chief Scientist @tri_dao introducing ATLAS:
9
37
261
143,422
Avner May retweeted

11 Jul 2025
Tokenization is just a special case of "chunking" - building low-level data into high-level abstractions - which is in turn fundamental to intelligence.
Our new architecture, which enables hierarchical *dynamic chunking*, is not only tokenizer-free, but simply scales better.
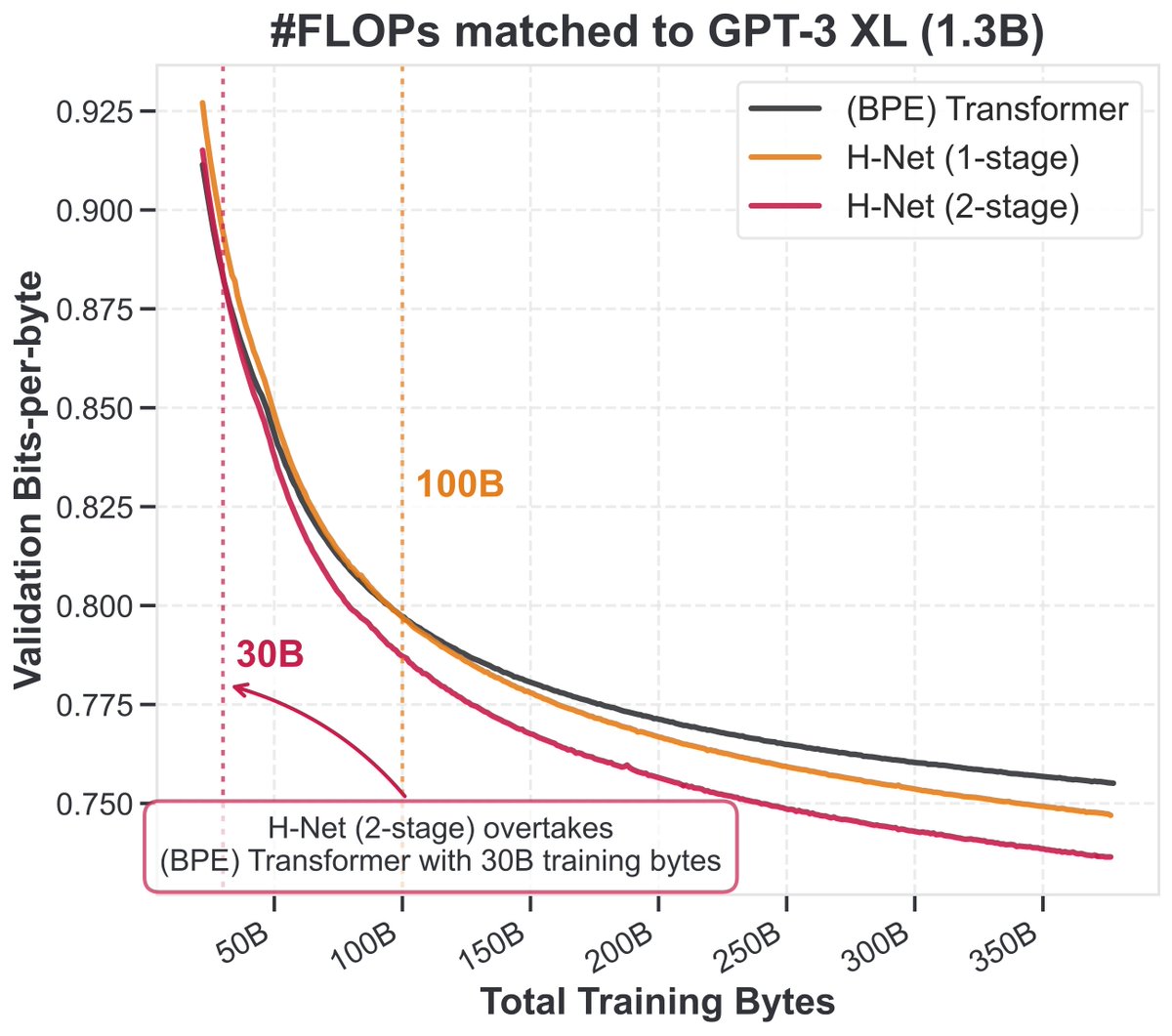
11 Jul 2025

Tokenization has been the final barrier to truly end-to-end language models.
We developed the H-Net: a hierarchical network that replaces tokenization with a dynamic chunking process directly inside the model, automatically discovering and operating over meaningful units of data
61
191
1,206
230,875
Excited that Together has just released TogetherChat!
TogetherChat is a way for anyone to ask questions to Deepseek-R1 and other leading open-source models, with an awesome UI, with a very similar user experience to using ChatGPT or Claude models. Check it out at chat.together.ai!
24 Mar 2025

Introducing Together Chat!
Use DeepSeek R1 (hosted in North America) & other top open source models to do web search, coding, image generation, & image analysis.
Available today for free!
6
492
Avner May retweeted
25 Sep 2024
🚀 Big news! We’re thrilled to announce the launch of Llama 3.2 Vision Models & Llama Stack on Together AI.
🎉 Free access to Llama 3.2 Vision Model for developers to build and innovate with open source AI. api.together.ai/playground/c…
➡️ Learn more in the blog together.ai/blog/llama-3-2-v…

10
44
252
60,296
Avner May retweeted
25 Sep 2024
🙌 We love that Llama has gone multimodal! We're excited to partner with @AIatMeta to offer free access to the Llama 3.2 11B vision model for developers. Can't wait to see what everyone builds!
Try now with our Llama-Vision-Free model endpoint.
Sign up here: api.together.ai/playground/c…
2
6
53
7,693
Avner May retweeted

5 Sep 2024
🥳Promised blogpost tweet about MagicDec-1.0🪄🪄🪄 2.0 coming soon😉:
How can we achieve Lossless, High Throughput, and Low Latency LLM Inference all at once? Seems too good to be true?
Introducing MagicDec-1.0🪄, a Speculative Decoding (SD) based technique that can improve throughput and latency by 2x in large-batch and long-context settings on 8xA100s.
🙀SD is widely used to reduce latency but the conventional wisdom suggests that its efficacy is limited to small batch sizes. MagicDec leverages the insight that moderate seqlen will make large-batch inference memory-bound so that SD can break latency-throughput tradeoffs for long context generation!
🤔MagicDec becomes more effective for increasingly larger batch sizes with an intelligent drafting strategy!
Sounds like Magic? Let’s deep dive into MagicDec!
Paper: arxiv.org/abs/2408.11049
Blog: infini-ai-lab.github.io/Magi…,
infini-ai-lab.github.io/Magi…
Repo: github.com/Infini-AI-Lab/Mag…
1
20
105
26,079

We’re pumped to see our Chief Scientist, @_albertgu, on the @TIME 100 AI list today!🚀
We’re grateful to have Albert leading the SSM revolution here at Cartesia ⚡



3
34
5,340

Surprisingly, speculative decoding works well not just for small batch LLM inference but also large batch and long context. Once we understood the compute & memory profile of LLM inference, the new spec dec algorithms fall out naturally
5 Sep 2024
We are excited to share our latest work on speculative decoding for high-throughput inference!
Before this work, we thought speculative decoding was useless at large batch sizes since the GPUs would go brrrr from processing all the different inputs.
Much to our surprise, we discovered speculative decoding is quite useful if the inputs are long enough because decoding once again becomes memory-bound from the large KV cache. In fact, we show that speculative decoding can improve latency AND throughput by up to 2x in this regime!
Read more here: together.ai/blog/speculative…
3
21
229
25,835
Excited to share our latest work on speculative decoding for high-throughput inference!
5 Sep 2024
We are excited to share our latest work on speculative decoding for high-throughput inference!
Before this work, we thought speculative decoding was useless at large batch sizes since the GPUs would go brrrr from processing all the different inputs.
Much to our surprise, we discovered speculative decoding is quite useful if the inputs are long enough because decoding once again becomes memory-bound from the large KV cache. In fact, we show that speculative decoding can improve latency AND throughput by up to 2x in this regime!
Read more here: together.ai/blog/speculative…
2
154
Excited to share our latest work, where we show how to distill from a Llama model into a Mamba hybrid, and how to make speculative decoding work with these models!
With Junxiong Wang, @DanielePaliotta, @srush_nlp, @tri_dao.
28 Aug 2024

🎉Exciting News! We just released our latest work: The Mamba in the Llama: Distilling and Accelerating Hybrid Models.
Work w/ Junxiong Wang, @avnermay ,@srush_nlp , @tri_dao.
🧵👇🏻

1
6
300