
Cold Outreach Copywriting | Cold Email and LinkedIn Sales Systems
Joined April 2020
- Tweets 2,606
- Following 317
- Followers 2,358
- Likes 8,324
78 Photos and videos












This is THE most common mistake I see in cold email lead gen:
→ Agency owner has an idea for a guide
→ Spends 4-6 weeks polishing the asset (Notion page, designer time, Loom walkthrough)
→ Drops it into a cold email campaign
→ Gets nothing back
→ Concludes that lead magnets do not work
The ONLY thing that mattered in that whole sequence was step 4.
And it ran last.
The correct order, every time:
1. Write 4-5 candidate lead magnet titles
2. Test each in a short cold email campaign
3. Measure positive reply rate per title
4. Build ONLY the title that generated real interest
5. Skip the other 3-4 entirely
A lead magnet without an interest signal is busywork dressed up as a deliverable.
The bet sits in the title.
2
10
23
1,254
how you'll be moving after reading this article...

274
Personalized lead magnets can be the highest-impact positive-reply move in a cold email playbook.
There are two non-negotiable rules:
1 - NEVER attach the lead magnet in the first email
↳ The first email asks permission to send it
↳ Something like: 'I built a [thing]. Want me to send it over?'
2 - Build the asset ONLY after they say yes
↳ Take their website (spidercloud)
↳ Take their socials
↳ Use Claude to personalize a template you already built for your service
↳ Deliver it within 24 hours of the yes
What makes a personalized LM work:
• Instant tangible value (they open it, they can use it today)
• High perceived effort (they can TELL a person looked at their business)
Examples that pass both tests:
↳ A personalized SEO audit on their actual site
↳ A specific competitor analysis on 3 named competitors
↳ LinkedIn post draft for their next launch
↳ Custom savings or ROI calculation tied to their headcount
Unsolicited PDFs WILL land in the trash.
1
262
cold email will NEVER be the same after this Fable 5 update
this will be one of the biggest shifts we see in the next 6-12 months in outbound
read this article and you'll know how to take advantage
2
6
30
10,513
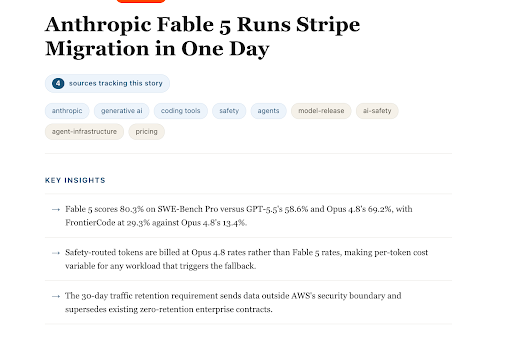
Stripe just ran Fable 5 against a 50M-line migration that had been estimated at two months of engineering. Fable 5 finished it in 1 day.
If you're running cold email loops, that benchmark is ALSO a warning.
A model that strong amplifies whatever standards you wrote down.
Here's how I think about it...
A lot of people think the failure mode of automated outbound is the agent. It's almost never the agent.
Vague skills produce automated vagueness.
If your copy guide says something like "hooks should be engaging," the loop produces engaging slop on a schedule. Fable 5 just produces it faster.
The skill library is production code.
Our outbound standards file has rules like:
• Every email answers why me, why now, why you, why should I respond
• 40 to 50 words, opener-body-CTA, end on a question
• Spintax with mandatory fallbacks
• One sequence maps to exactly one offer-angle-segment combination
None of that is impressive on its own. The point is that it's WRITTEN.
The loop reads it on every run. Fable 5 can't drift past what you specified.
A better model doesn't fix a vague spec.
All it does is run the vague spec faster.
Just my 2-cents.
4
12
966
The cost of running cold email agent loops at scale just collapsed.
I’m using the NEW Fable 5 model to take over cold email…
A bit of context:
Boris cherny, who leads claude code at anthropic, has been saying it for a while:
"i don't prompt claude anymore. i have loops running that prompt claude. my job is to write loops."
Every engineer i know is using this idea to ship code.
NO ONE is using it on cold email.
So I built it for outbound.
Because across our 50 clients, 30,000 inboxes, and 2M emails/mo that we send…
The actions that I see actually hurt campaign performance is NOT the sending.
It's the judgment that runs on TOP of the sending.
> diagnosing why a campaign's PCPL drifted above its healthy band
> rewriting copy before ESPs fingerprint the structure at volume
> rebuilding a list when the bounce rate climbs past 3%
> repairing infra when sending capacity drops below what the campaigns need
> mining replies and call transcripts weekly so the copy learns prospect language instead of guessing it
Most agencies still have a person doing all 5 of those, by hand, on a calendar.
That's the layer I automated.
So I wrote up the full blueprint for the self-optimizing cold email system we run internally.
What's inside this blueprint:
1. the PCPL benchmark bands per offer type so you know when something's broken (high-ticket service, mid-ticket, product/wholesale, enterprise)
2. the 6 components every loop needs, mapped 1:1 to the outbound stack (automations, worktrees, skills, connectors, sub-agents, memory)
3. the 6 loops we run on every account: daily health check, script improvement, reply learning, inbox/domain health, monthly angle mining, new campaign pipeline
4. the 3 memory files per client (LEARNINGS.md, STATE.md, Postgres) that turn 6 months of campaign history → selection pressure on every new draft
5. the 3 agent files where the WRITER never grades its own work (copywriter / standards-checker / deliverability-checker) and why fable 5's self-validation doesn't replace the maker-grader split
6. the 5 failure modes that kill these systems (copy thrash, token spend, garbage skills, comprehension debt) the 3-stage rollout we use even on new client accounts
7. defensive autonomy: the ONE loop allowed to act without approval (pause a burning domain instantly. waiting for a human costs the domain)
Want it?
• comment "LOOPS"
• follow me so i can DM the link
PS
Fable 5 is what makes long-horizon agent loops viable for high-volume cold email right now.
Yusuke kaji at anthropic put it this way: "at the highest effort, claude fable 5 reflects on and validates its own work. for us, that's what makes highly autonomous operations possible."
14
9
21
735
Some of our clients book meetings with $50M-$100M companies pretty much every other day.
I haven't posted any of it, until now.
Most cold email playbooks were built for $1-5M ARR targets.
Spray and pray Volume hope.
The SECOND you try to land a Fortune 500/1000 logo, that flow no longer works.
It's an entirely different game, with different infrastructure, boundaries, people, etc.
That said...
I'm giving away my entire system built SPECIFICALLY for enterprise targets.
I wrote it up so you can start targeting bigger companies, go upmarket, and sign those $10k /mo retainers.
What is inside:
1. The full breakdown of how we booked 51 enterprise appointments at Fortune 500/1000 accounts
2. The 5-Pillar System (the exact technical setup behind the bookings)
3. The 67-question Diagnosis Checklist to audit your current setup before your next send
4. The Multi-Channel Outreach playbook... how LinkedIn / phone / email layer at this size
5. The step-by-step rollout sequence
Comment "FORTUNE" and I'll send it over.
(must be following)
75
13
50
3,094
I completely stopped having no-shows after reading this
Super valuable article
3
350