
cofounder @hoxbio | building integrated systems for discovery, health, and security
Joined December 2024
- Tweets 219
- Following 188
- Followers 642
- Likes 1,139
21 Photos and videos














May 8
putting this tweet on the wall in the office
3
313
May 7
downtown livermore feels a little like Palo Alto with shittier cars
1
10
652
May 2
when the kids are destroying the house but also leaving you alone so you gotta decide if you’re gonna get up and do something about it
1
6
205
May 1
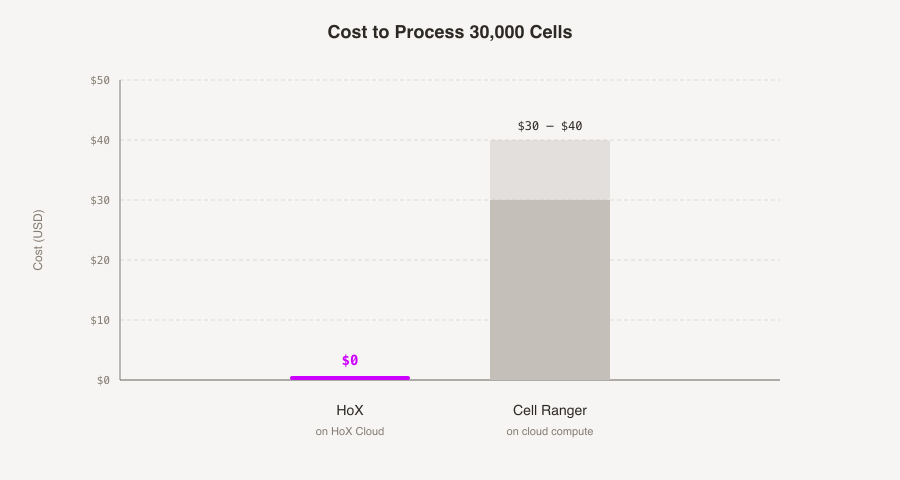
We wrote our own hyper-efficient version of the STAR aligner.
Typically it costs around $35 in cloud compute to process 30k cells with Cell Ranger. Ours costs so little that we don't charge for it. Also ours works with nanopore.
If you prefer pseudoalignments, then you can run it in pseudoalignment mode -- obviously we don't charge for that too.
All results instantly integrated with our other tools. As soon as a run finishes you can open alignments or expression matrices in our viewers without moving anything.
Let me know if you want to try it!
13
18
134
23,001
Apr 29
Excited to announce our single cell visualizer toolkit.
A scalable web interface for interactive tertiary analysis on cell cohorts. With support for over dispersed genes, differential expression, automated cell type inference, gating on gene expression, neighborhood filtering, clonotype filtering
Soon we will be adding support for isoform resolved tables and expressed somatic variants
Since all of this is backed by our biology-native data warehouse, the cohort selection is becoming increasingly programmable.
2
7
81
8,336
Apr 29
All of our tools are deeply integrated. Here’s an instant switch from single cell view to pile up view
1
4
425
Apr 27
we’re going to put together an easy hosting mechanism so you can publicly host our genomics viewer with your data on your website. probably a couple weeks out
12
779
Apr 27
HoX genome viewer now has colorings by barcode. Moving towards custom coloring schemes.
2
16
1,657
Apr 25
It was weird watching this be made fun of instead of such a perfect, scrappy move to throw off cash
Apr 24

The reason of course is Blake's brilliant idea to fund the airliner by selling gas turbines to data centers. I can't think of another move that has turned the tables on investors so thoroughly. And now that Boom doesn't need investors anymore, investors want in. So it is always.
2
478
Apr 23
It’s the lab automation version of this
Apr 23

Robot arms can be sexy, but avoid if possible!
Weird thing in bio is people making robots more like humans instead of refactoring the protocol to be optimal for non-humans
1
100
4,342
Apr 23
Robot arms can be sexy, but avoid if possible!
Weird thing in bio is people making robots more like humans instead of refactoring the protocol to be optimal for non-humans
Apr 23

I was interested to learn that robot arms are a code smell even in car manufacturing

13
5,557
Apr 23
a while ago we ripped out our benches and slapped together a programmable cell to support our services
now time to see what kind of volume our little team can do
2
6
74
8,174
Apr 23
We built a whole internal software suite for running these. Could theoretically hook it up to whatever agentic harness as well.
Should we release this as a product?
2
342
James retweeted

Apr 23
Robot arms are the lab automation equivalent of a "code smell." The ideal number of humanoid robot arms involved in your protocol is zero (because there's nothing about human biomechanics that makes us good at running microbiology assays...)
We use one arm to load and unload liquid handlers and to move plates to our plate reader, but we're pretty aggressively trying to move stuff entirely "on-deck." I'll be perfectly happy once we can throw out the arm entirely.
Apr 23

ngl this seems like a super fake demo
Open air liquid handling robots?
Robotic arms flipping sideways/upside down with pipette tips?
5
1
24
4,643
James retweeted

Apr 22
LLMs really are worse than first-year CS students in their tendency to believe it's totally a bug in the library/OS/compiler (tested for decades) rather than their own code (didn't exist 5 minutes ago)
26
24
647
25,384
Apr 22
Happy to announce that our first sequencing service -- SPLICE -- is now generally available.
For decades, transcriptomics has focused on gene-level analysis, but we know that most human genes undergo alternative splicing -- emitting different mRNA variants that can have completely different functions. The collapse to gene-level analysis keeps the set of therapeutic targets smaller than it has to be.
The focus on genes is partially due to the difficulty of reconstructing splicing patterns from short read sequencing data, and partially due to the difficulty of effectively using long reads to capture full-length RNA molecules.
Today, we release SPLICE to make full-length RNA sequencing easy and systematic -- opening up a larger set of candidate targets to everyone.
Some key benefits of our service: both bulk and single-cell modes, no sample minimums, turnaround in under a week, no bioinformatician needed, full access to our data management and analysis suite, and 4x more reads per cell than what is typically found in the literature. Further, one untargeted assay gives you expression, V(D)J recombinations, whole exome variants, and splicing information. It's a very high yield assay for samples that are often extremely precious.
We're also releasing updates to our tools. Shown below are queries we've added to our genomics viewer for comparing canonical isoforms against other variants and for finding reads that capture both 5' and 3' ends.
The data shown is real data generated from our service -- we have example data readily available. We've been running SPLICE privately with rare disease customers for months and are happy to finally make it generally available.
5
29
124
19,484
Apr 22
We also will figure out how to dissociate your weird tissue! 😂 if you need help with this
3
447
James retweeted

Apr 22
Understand your splice variants with @hoxbio
Apr 22
Happy to announce that our first sequencing service -- SPLICE -- is now generally available.
For decades, transcriptomics has focused on gene-level analysis, but we know that most human genes undergo alternative splicing -- emitting different mRNA variants that can have completely different functions. The collapse to gene-level analysis keeps the set of therapeutic targets smaller than it has to be.
The focus on genes is partially due to the difficulty of reconstructing splicing patterns from short read sequencing data, and partially due to the difficulty of effectively using long reads to capture full-length RNA molecules.
Today, we release SPLICE to make full-length RNA sequencing easy and systematic -- opening up a larger set of candidate targets to everyone.
Some key benefits of our service: both bulk and single-cell modes, no sample minimums, turnaround in under a week, no bioinformatician needed, full access to our data management and analysis suite, and 4x more reads per cell than what is typically found in the literature. Further, one untargeted assay gives you expression, V(D)J recombinations, whole exome variants, and splicing information. It's a very high yield assay for samples that are often extremely precious.
We're also releasing updates to our tools. Shown below are queries we've added to our genomics viewer for comparing canonical isoforms against other variants and for finding reads that capture both 5' and 3' ends.
The data shown is real data generated from our service -- we have example data readily available. We've been running SPLICE privately with rare disease customers for months and are happy to finally make it generally available.
3
8
2,311