
Joined May 2009
- Tweets 154
- Following 428
- Followers 61
- Likes 29
4 Photos and videos



wongyu jung retweeted

8 Oct 2025
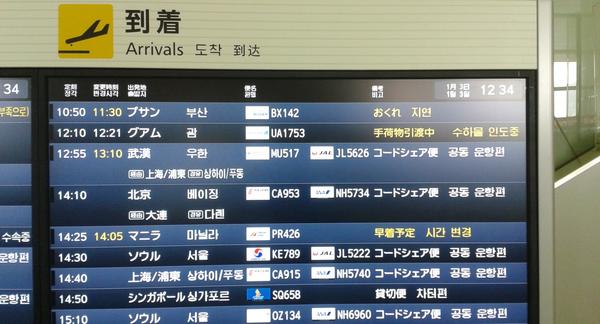
LLMの時代は終了かもしれません。
Samsungが開発した、小型モデル「TRM」が、DeepSeek-R1やGemini 2.5 Proなど1万倍以上も巨大なLLMを、主要な推論テストで打ち破りました。
AIの賢さはモデルのサイズだけでは決まりません。
論文で示されたTRMと重要性を8つのポイントにまとめました。
1. なぜ、これほど小さなモデルが巨大モデルを凌駕できたのか?
その秘密は、答えを出す前に何度も「考え直す」独自の再帰的思考プロセスにあります。 TRMが驚異的な答えを導き出す、5つのステップを紹介します。
2. ステップ1(まず仮説となる答えを素早く下書き)
一般的なLLMが単語を一つずつ生成するのとは異なり、TRMはまず全体的な回答のドラフトを素早く作成します。これは初期仮説として機能します。
3. ステップ2(思考するための「下書き用紙」を作成)
次に、モデルは内部に「スクラッチパッド」と呼ばれる思考専用のスペースを確保します。ここが、本格的な分析プロセスが展開される場所です。
4. ステップ3(徹底的な自己批判を繰り返す)
モデルは最初の答えと元の問題を比較し、最大6回連続で自問自答を繰り返します。「自分のロジックは正しいか?」と問い続け、エラーを特定し、思考を洗練させていきます。
4. ステップ4(洗練された思考を元に答えを修正)
この集中的な内部思考プロセスの後、TRMはスクラッチパッドで洗練されたロジックを利用して、大幅に改善された新しい最終回答案を構築します。
5. ステップ5(自信が持てるまでプロセスを繰り返す)
「下書き→思考→修正」というサイクル全体が、最大16回繰り返されます。各サイクルを経るごとに、モデルはより正確で論理的な結論に近づき、回答に対する高い信頼性を確保します。
6. このTRMの登場は、なぜこれほど重要なのでしょうか?
ビジネスリーダーにとって
競合他社が巨大モデルの莫大な運用コストに苦しむ中、TRMはわずかなコストで優れた性能を提供します。これは、 brute-force(力任せ)なスケール競争からの脱却を意味し、圧倒的なアルゴリズム的優位性を示します。
7. 研究者にとって
「行動する前によく考える」というTRMの能力は、神経科学と記号論理学を組み合わせたAIアプローチの強力な証明です。AIの高度な推論能力は、モデルの規模だけでなく、優れたアーキテクチャ設計によってもたらされることを示しました。
8. 開発者にとって
最先端の推論能力は、もはや数十億ドル規模のGPUクラスターを持つ巨大企業だけの専有物ではなくなりました。TRMは、誰もが手頃なコストで専門的な推論AIを構築・展開できる、効率的な設計図を提供します。
22
567
2,894
352,885
wongyu jung retweeted

8 Jan 2024
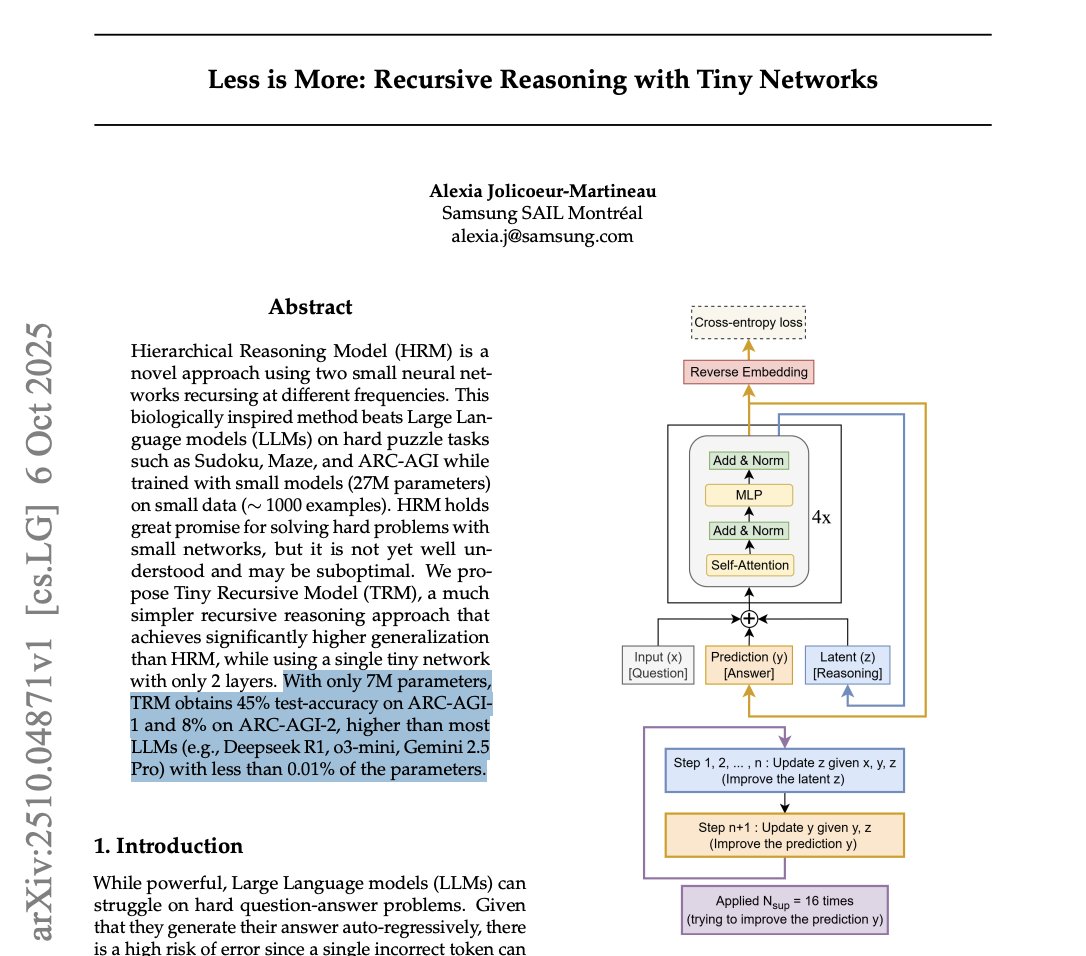
能登半島地震で大変な被害に合われている皆様、我々にできることは限られていますが全速でできるところからやらせて頂いております。楽天携帯もまだ100%ではないですが、90%近くカバー復旧、100%に向けて頑張ります。他キャリアさんも全力で取り組んでいると思います。神戸出身の自分、そしてイーグルスのフランチャイズである東北に係るものとして、これからも継続的に支援を続けていきたいと思います。
40
508
3,560
945,001
wongyu jung retweeted

27 Dec 2023
【LLM講座講義スライド公開】
約2000人が受講した、松尾研LLM講座の講義スライド(全7回分)を無償公開しました。2次利用も可能ですので是非ご活用下さい(非営利のみ)。 演習ファイルは来月に公開予定です。
weblab.t.u-tokyo.ac.jp/llm_c…
#松尾研_LLM講座
4
507
2,075
217,267
wongyu jung retweeted

4 Feb 2020
開店直後のドラッグストアにマスク大量入荷してました。
すぐに供給が追いつくようになりますよ。
マスク欲しい人は転売屋から買わないようにしましょう!

2
73
147
wongyu jung retweeted

10 Aug 2013
오픈소스라 개발자들이 협력하는게 아니고, 강자가 살아남고 약자들은 살아남기 위해 협력. 지켜만 보고 있으면 끝까지 보고만 있게 될 것 RT @eddieyoon: 하둡의 생태계, 오픈소스는 자연을 닮았다. blog.udanax.org/2013/08/blog…
1

9 Apr 2013
Directory: Data center infrastructure services vendors in the US zdnet.com/directory-data-cen…
wongyu jung retweeted

10 Feb 2013
Ten ways to build a company with almost no money tgam.ca/Dmkh
3
33
55
3 Jan 2013
12시 30분이 넘어도 그냥 지연이란다. 한국에연락해 보니 비행기는 뜨지도 않앗음.40분 거리를 3시간이나 지연하면서 정보도 갱신 않하는 에어부산
너무한다. @Airbusan