
3 Photos and videos

Basil retweeted

9 Dec 2024
!! @pabbeel and I are building a new AI research lab in SF for Amazon! We’re focused on the remaining major problems to build generally intelligent agents and are looking for a few dozen intrinsically motivated people to join our team and work with the Adept folks here. DM me!
9 Dec 2024

Super-excited about what's ahead. Want to move the AI research frontier, join us!
amazon.science/blog/amazon-o…
AGI-SFLab-Jobs@amazon.com
19
17
386
72,296
Basil retweeted

24 Jan 2024
Introducing our new multimodal model Adept FUYU-HEAVY!!
Beats Gemini Pro on both MMLU (text-only benchmark) and MMMU (image text benchmark)
Plus cute mascots!

7
2
71
17,709
Basil retweeted

31 Jul 2023
✨ come join me! ✨
We're looking for a product designer to join our team focused on making an AI teammate @AdeptAILabs, on-site in SF.
It's a super lovely, amazingly talented, ridiculously humble group, with so much room for impact ❤️
2
7
36
6,872
Basil retweeted
18 Jul 2023
I'm so excited to share what's up next for me
I'll be designing a digital AI teammate with the super talented people at @AdeptAILabs!
I'm just a week in and couldn't be more excited about the both wildly creative and technically rigorous team.
Definitely watch this space 🤩✨
24
2
220
19,094

Big round a few days after @basil’s LondonAI talk 😉
1
8
2,228
Basil retweeted

7 Feb 2023
👋 Join us on 9 March for @londonai!
If you're working on AI, this is your jam. If you're interested in AI, you will this jam, ft:
🤖 @vijaybolina of @DeepMind,
👾 @basil of @AdeptAILabs,
🌱 @lorenzphil09 of @Basecamp_Res
and mystery speaker :-)
londonai.substack.com/p/sign…
2
9
39
10,219

I'm very excited to have joined @AdeptAILabs! We're building a universal collaborator – it's like an overlay that sits on top of all the software you use. You can hand off tasks to it by just... asking. Below is an early preview of some things it can do!
1
2
33
Finished my final week at @normallystudio, after 7 amazing years. Normally works by combining radical experimentation with… just being kind. This culture leads to impactful and meaningful projects. If you get the chance to work with them, or just meet with them: you should ❤️
8
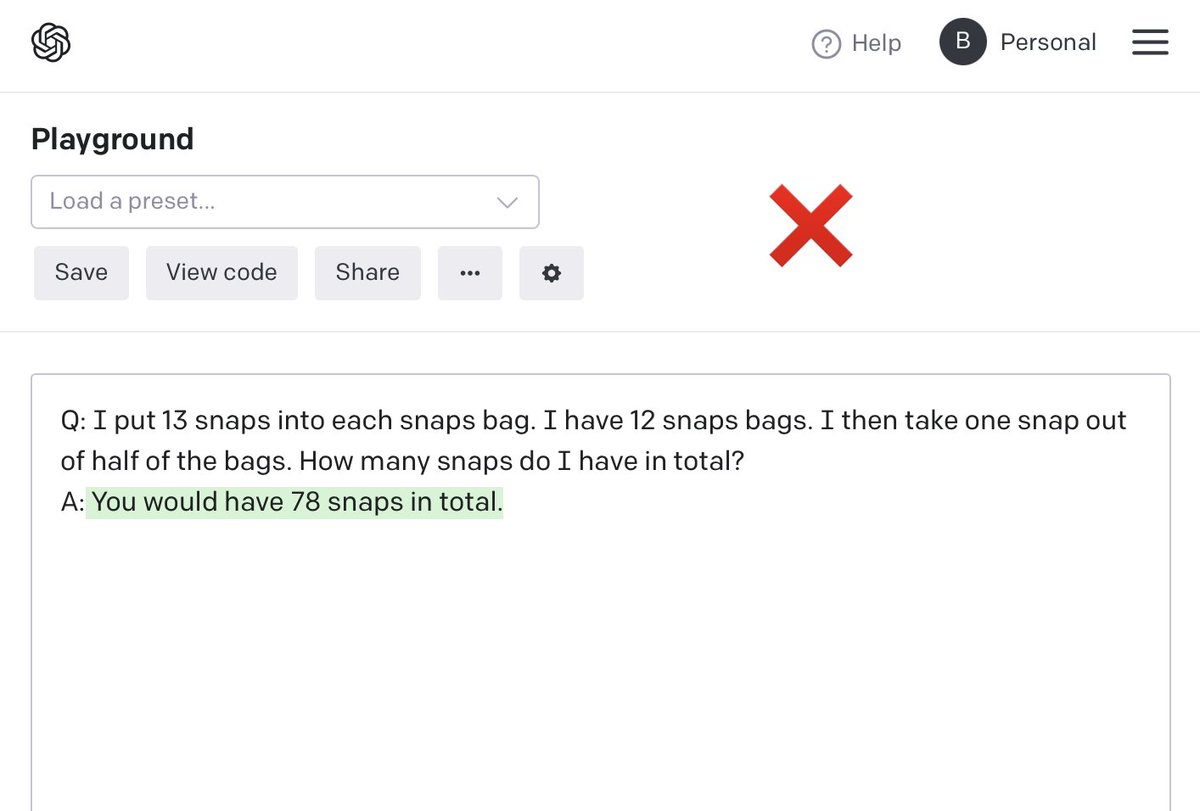
This is brilliant. The model just needs to be asked nicely to do a good job.
25 May 2022

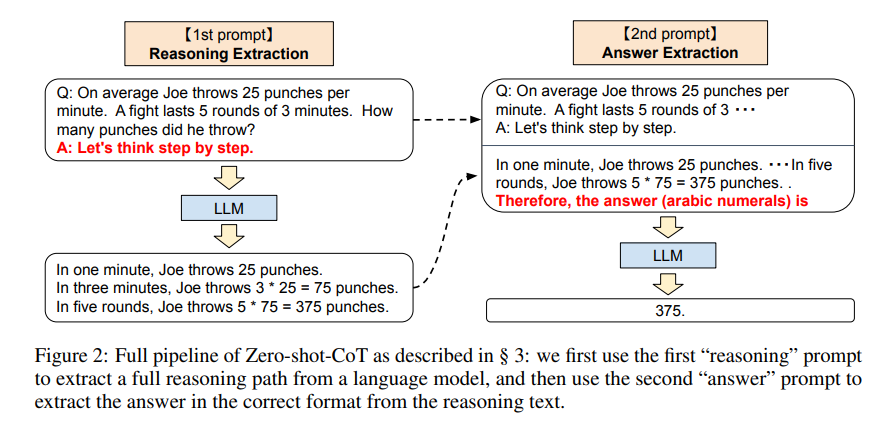
Large Language Models are Zero-Shot Reasoners
Simply adding “Let’s think step by step” before each answer increases the accuracy on MultiArith from 17.7% to 78.7% and GSM8K from 10.4% to 40.7% with GPT-3.
arxiv.org/abs/2205.11916
1
1
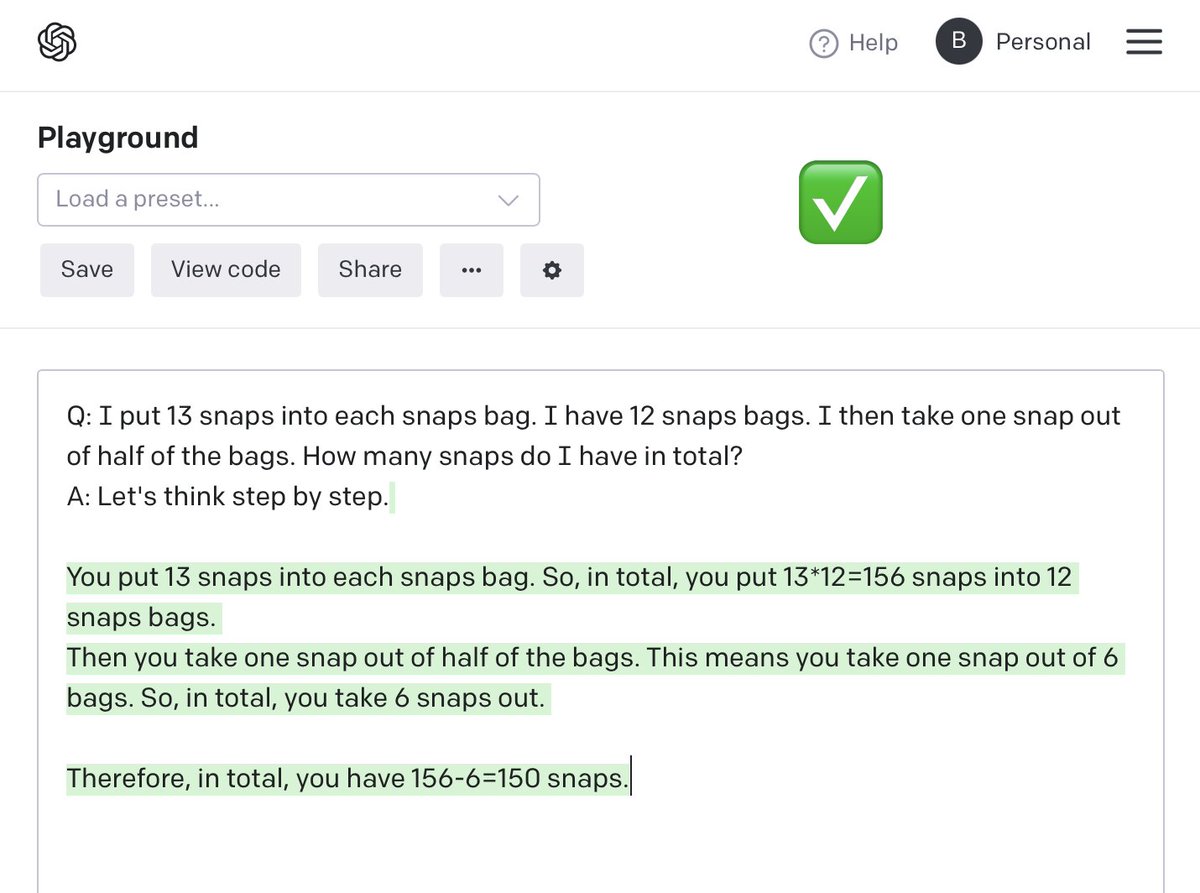
I tried my own question using nonsense words – the voodoo incantation worked (without needing the second "and so the answer is..." prompt) @shaneguML @arankomatsuzaki
3
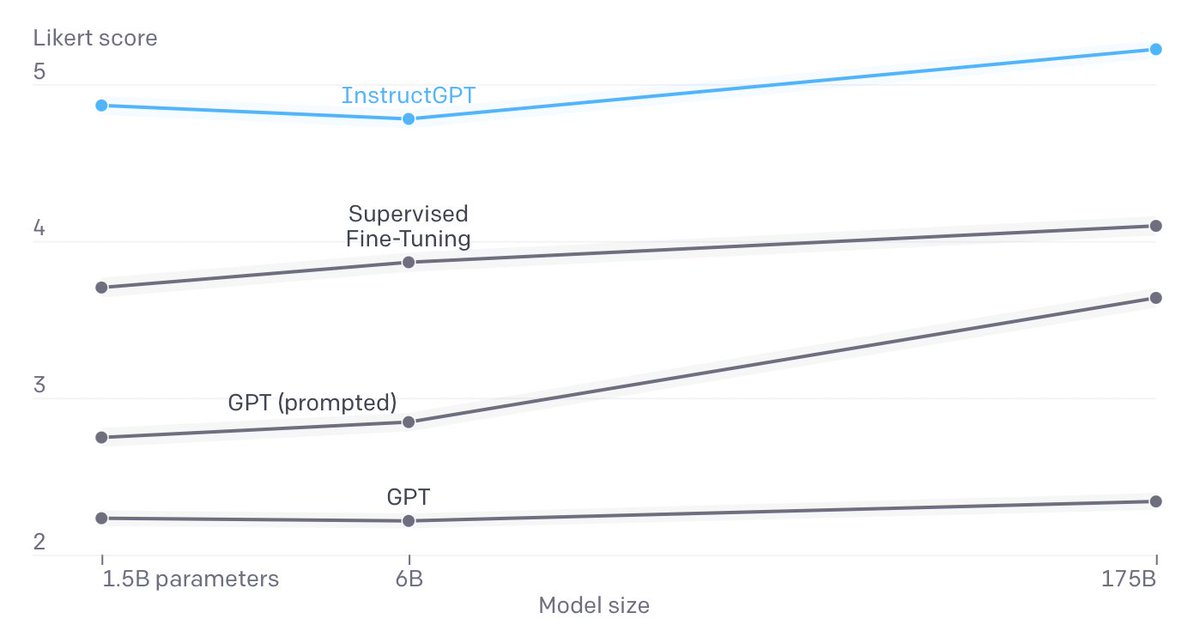
Finally: this is a paper showing good results in aligning language models to certain human requirements. Great! But if you log in to your OpenAI account… the model is right there, launched, and is actually the default model. This is v much a product company now (4/꩜) @sama
1
1
Link to the summary: openai.com/blog/instruction-…
Taking a few months of sabbatical from the amazing @normallystudio from.......... now! Things I will be doing include (1/✨)
1
9