
Software Engineer, Hobbyist, Tinker, Amateur
Joined November 2009
- Tweets 171
- Following 265
- Followers 64
- Likes 12,055
9 Photos and videos






Andy Barajas retweeted

20 Jun 2025
Going for a relaxing cruise through Rainbow Road in Mario Kart 64... on my Sega Dreamcast, of course! Let's take a look at this footage I just barely recorded directly from my DC of jnmartin's latest build!
First of all, yes, there's still no audio. No, I don't care how blasphemous it is to put the Sonic R soundtrack to Mario Kart! 😂
BUT BEYOND THAT, omg, look at how freaking good everything looks and how smoothly its all running! All of the texture corruption has been fixed, the smoke particles coming from the carts are no longer blocks, the star sprite animations are present, and the trails from the koopa shells are no longer bright blue!
The biggest change; however, is the fact that the background textures of the characters in the sky are no longer so corrupted and distorted that they look like evil demons from hell! ...and you won't believe what the cause was!
The decompilation code for this particular level has a bunch of lookup tables for the color palettes associated with each character texture in the night sky. Each CLUT is declared as a constant static array of 256 color values, defined sequentially.
Then there's a routine that initializes the night sky texture for a given character, using its respective table... and the freaking thing decided that it could just treat these disjoint tables as though they were one big-ass table, being able to grab the table associated with a given character programmatically by doing some pointer arithmetic on the address of the first table to jump to the correct one!
...there's just one problem. Who said the order in which you define these tables dictates the order in which they are put into the .rodata segment of the binary!? C and C certainly don't give a shit about your ordering!
So the problem? The MIPS GCC compiler used on N64 does maintain this ordering within the compiled binary, while the SH GCC compiler used for Dreamcast (and even x86, apparently), do it in the opposite order! The result? Hellish nightmare demons in the sky whose texture colors were initialized from another character's palette! WHOOPS!
21
63
445
21,430
Andy Barajas retweeted

18 Jun 2025
I downgraded my PC to an office laptop with integrated graphics, and my voxel engine still runs at 60 FPS with a render distance of 64. After a major I/O system overhaul, it's now 9x faster than before. World loading is near-instant.
12
42
1,034
48,282
Andy Barajas retweeted
17 Jun 2025
Isn't it about time we brought the Blue Blur back home to a Sega console?! Presenting Sonic Mania Plus... running on an actual physical Sega Dreamcast!
While there's no audio yet, and the 3D effects and stages have yet to be hooked up, developer @SonicFreak94, has done an INCREDIBLE job getting this title ported over so far!
He worked some serious voodoo to get this game fitting into 16MB of RAM, and has even had to push against VRAM limitations, even with texture paletting being used, due to there just being so many goddamn sprites loaded at once.
What you WILL notice here is that she's running at a perfect 60FPS with the DC barely even trying at all for the majority of the game! This is due to his work implementing a custom HW accelerated rendering back-end that directly uses our low-level PVR driver in KallistiOS, rather than the SW renderer used by most ports of the game.
While he still has a long way to go, it's incredible how playable the game already is and just how damn good and at home it feels on the Sega Dreamcast!
65
571
2,766
93,932
Andy Barajas retweeted
17 Jun 2025
Bonus clip showing off leaf decay in my voxel engine for the Dreamcast.
7
27
380
10,693
Andy Barajas retweeted
16 Jun 2025
New inventory system and destructive block drops for my Minecraft-like voxel engine on the Dreamcast. Inventories are immutable and interned to save memory and future-proof it for multiplayer.
9
24
415
11,819
Andy Barajas retweeted
13 Jun 2025
Been writing SH4 assembly code for the Sega Dreamcast all day and night, hoping to bring big performance gainz to everyone in the community by providing a replacement memcpy() routine that doesn't suck for our GCC toolchains.
As it turns out, the Newlib-provided memcpy() we have backing the C standard library in our SH GCC toolchains is slow AF. This impacts not only our Grand Theft Auto 3 and Vice City ports, but also Doom64, Mario Kart 64, WipeOut, and virtually every homebrew game or port that uses KallistiOS!
Just have a look at the benchmark results on the left to see just how shittily it performs. The benchmarker invokes a series of memcpy() implementations over an increasingly large buffer window with compile-time configurable alignments. Each iteration initializes the source buffer with a series of randomly generated numbers and clears the destination buffer before clearing both the data and icaches for each run.
During the run, the performance counters on the SH4 CPU are used to record cycle-accurate timing for each memcpy() invocation, which is then validated after the run for correctness. There are also large buffers located before and after the destination buffer, which are scanned for any stray/out-of-boundary writes after each iteration.
ANYWAY, what you're seeing in the benchmark output is the performance of my custom 1, 2, 4, 8, and 32-byte aligned memcpy() variants, which are highly optimized for specific use-cases, as well as the result of "memcpy_gainz()" which is the generalized form which attempts to call into the fastest of these specialized forms.
Meanwhile, "memcpy_fast()" is a routine we found on the internet many years ago from STMicroelectronics which has impressive speeds, but has an LGPL license, which prevents us from statically linking to it in closed-source commercial games.
Finally, "memcpy()" is the C standard library routine that ships with our toolchains... and as you can see... It runs like absolute, total, and complete shit. Somehow, at a pathologically best-case alignment of 32-bytes with 1024-byte copy requests, the damn thing manages to be slower than "memcpy1()" which is a simple for loop in vanilla C that could've been written by a total newbie that just copies the source buffer to the destination buffer one byte at a time...
So basically all of the bazillion things that are using memcpy() in our software in the Dreamcast community, including everything ranging from copying strings or vertices to transferring packets to and from the layers of our network stack, is all taking a massive performance hit due to us having a shitty memcpy() implementation.
After I discovered this, I embarked on a quest to take my specialized memcpyN() routines and see if I could use them as the basis for a generalized memcpy() routine to leverage. This is how "memcpy_gainz()" was born.
Unfortunately I was on my own for this quest, as every single resource that I found for writing optimal memcpy() routines was targeted at platforms which support unaligned memory accesses. Such platforms require a fundamentally different approach from the one taken for SuperH and other RISC processors without such support.
Rather than simply falling back to unaligned memory accesses, my routine attempts to align the destination buffer to 32-byte cache line boundaries where it can call into one of the fast specialized routines depending on the relative alignment of the source buffer. Then it simply does byte-by-byte unaligned copying for any bytes before or after the cache line boundaries.
At this point in time, I'm happy to say that for all alignment types I am beating even our fast_memcpy() implementation for transaction sizes larger than 32 bytes and smaller than 8KB. There's still plenty of work to do for both tiny and massive sizes, but I'm stoked to see what people do with the extra cycles once this is done!

34
74
709
53,805
Andy Barajas retweeted

20 May 2025
Progressing on my SDL3 library port to Dreamcast: added the audio driver, here is a couple of the examples running.
github.com/GPF/SDL
2
4
57
1,343
Andy Barajas retweeted

7 Apr 2025
Starting a podcast! First episode with Ramon Santamaria, creator of RayLib (25k GitHub stars). He’s a solo dev, educator, and ex-EA engineer shaping the dev scene for over a decade. Full video link in the comments.
8
19
119
15,242

My friends,
Please, if you enjoy these free repair tips (no ads), kindly RT these videos as it truly helps! I really do appreciate it!
Let me show you how to repair a flat cable cheaply and SAFELY with Kapton tape and not a drop of glue!
This SNES is back online!
13
114
421
18,952
Andy Barajas retweeted

9 Oct 2024
Playing with Dreamcast shadow volumes in Spiral Engine. For now it's very simple, there are no calculations to cast the shadow, just a volume. I hope to be able to make a decent shadow system for the engine, shadows are expensive.😅 #Dreamcast #gamedev #retrocomputing
10
20
106
10,136
Andy Barajas retweeted

26 Jul 2024
Dear @katyperry,
I’ve created a high-energy, guitar-centric remix of "Chained to the Rhythm" for my upcoming mixtape Summerscapes Part 1, set to release on July 26th. This project was inspired by my 10-year Twitch subscriber, Tanookii, who shared your music with me over the years.
I’d be honored to have your approval to include this remix in my non-commercial release. Your blessing would mean the world to me and my community!
Thank you for your incredible music and inspiration. 🎶✨
Best, Fanatiq
soundcloud.com/mrfanatiq/cha…
I mean, I wanna release it commercially too though. :)
Tell Distrokid that I have the green light ;)
#SummerscapesPart1 #Remix #KatyPerry #ChainedToTheRhythm
1
4
10
1,102
Andy Barajas retweeted
8 May 2024
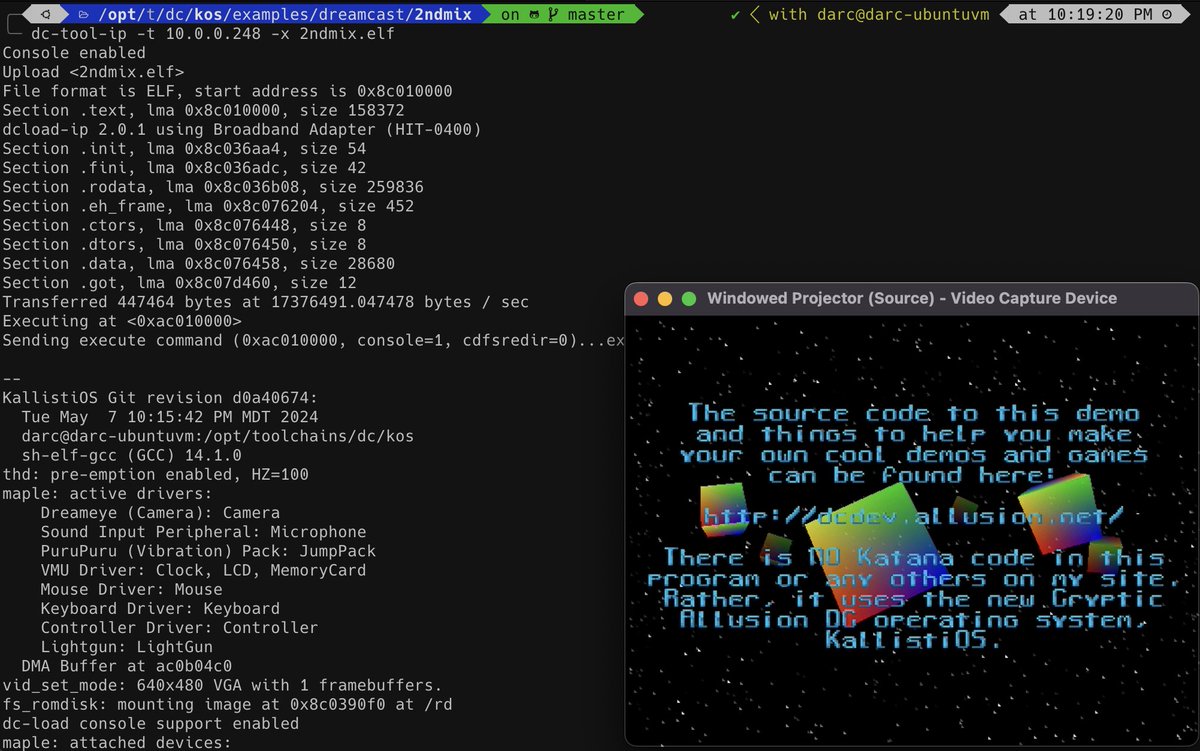
Here she is! Our day 1 support for the new GCC 14.1.0 toolchain on the Sega #Dreamcast! Not just C23, but also start brushing up on your C 26, Obj-C, D, Rust, and Ada! #gamedev #cplusplus #GCC
8 May 2024

After months of testing/patching work to make sure the Dreamcast toolchain would be ready for GCC 14.1.0, it's here! KallistiOS and all kos-ports are building under 14.1; dc-chain builder has been upgraded for 14.1, so start brushing up on your C23!
4
12
99
7,544
Andy Barajas retweeted

8 May 2024
After months of testing/patching work to make sure the Dreamcast toolchain would be ready for GCC 14.1.0, it's here! KallistiOS and all kos-ports are building under 14.1; dc-chain builder has been upgraded for 14.1, so start brushing up on your C23!
1
15
50
10,272
Hey everyone, I'd really appreciate a RT on this to let people know that I have RESTOCKED the store!
N64RGB and SNESRGB kits are BACK available! Thanks so much for your support and waiting on me. Get them while they're available at voultar.com !!

21
196
310
64,619
EVERYONE!
New Video! Please RT and Like!
In this nearly hour long feature, I show you the greatest Modchip ever designed for the GameCube, the new KunaiGC. I also show you the WORST HDMI mod in existence for the GameCube, the Pluto GCVideo PCB.
youtu.be/h_cWg3Ot4s8

14
101
331
36,681

Andy Barajas retweeted

24 Mar 2023
Thanks for hosting! Our Kickstarter is really soon, so I appreciate the visibility :)
x.com/rkilgariff/status/1639…
24 Mar 2023

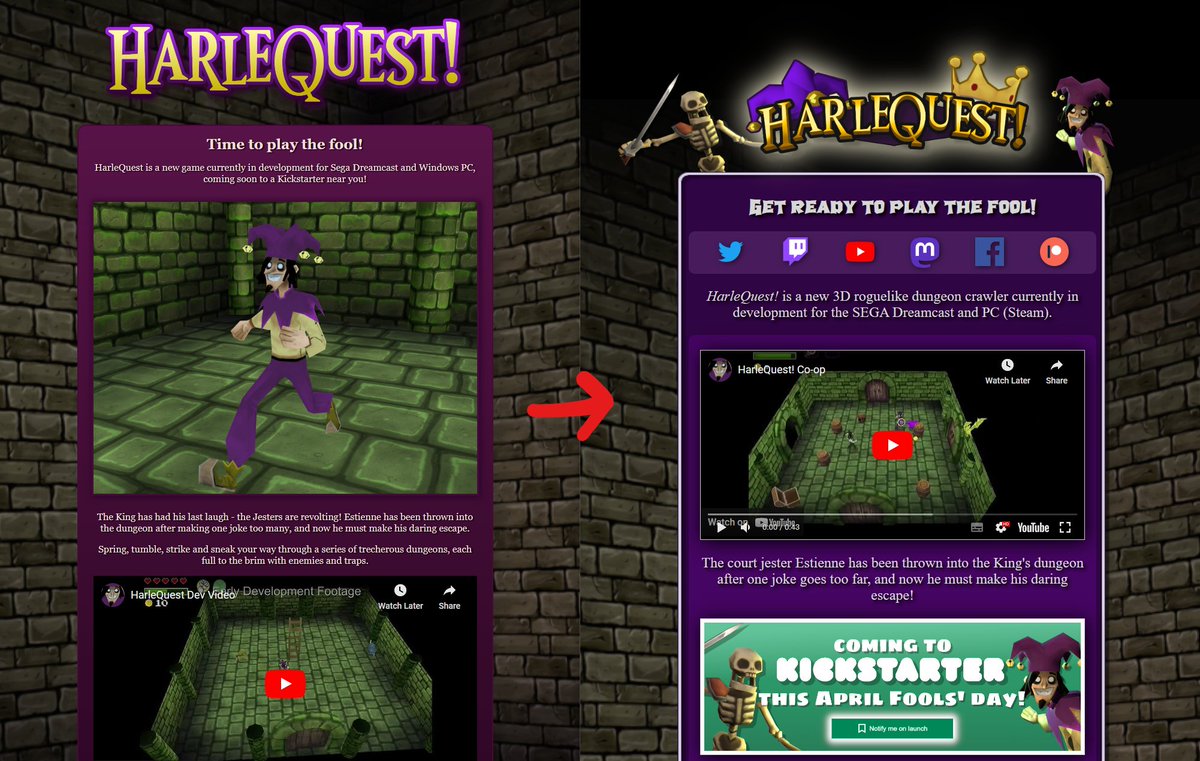
With our Kickstarter going live really soon (8 days!) I spent some time today sprucing up the game's website.
harle.quest/ now has all the game's socials, a link to the community discord and a link to the demo :)
#followfriday #indiegame #dreamcast #kickstarter
2
10
860
Andy Barajas retweeted
24 Mar 2023
With our Kickstarter going live really soon (8 days!) I spent some time today sprucing up the game's website.
harle.quest/ now has all the game's socials, a link to the community discord and a link to the demo :)
#followfriday #indiegame #dreamcast #kickstarter
5
21
2,205
Andy Barajas retweeted

22 Sep 2022
Just quick setup guide and setup guide for cubeboot! Not only does it restore the boot animation but it give you the ability to customize it. Retweets are much appreciated 🤘
youtube.com/watch?v=Vij3upNy…

7
34
104
Andy Barajas retweeted

30 Jun 2022
Join me today at 12:00pm EST for the premier of the PicoBoot from @webhdx! An amazing new way to modchip the Nintendo GameCube! I’ll go over the Installation, step by step setup and review all its features. It’s gonna be grand!
youtu.be/qwL4ZSa0xMo
6
10
64