
Technology solving problems... and creating new ones
Joined January 2017
- Tweets 1,764
- Following 483
- Followers 3,674
- Likes 1,176
81 Photos and videos














Jun 8
Casual AI prompting breaks down as codebases grow. Codev introduces strict protocols and multi-model reviews to help teams ship maintainable software.
bdtechtalks.com/2026/06/08/c…
67
Jun 1
Scaling LLMs hits limits when dealing with agentic AI tasks. For that, we need to look at the harness and the system built around the model(s).
bdtechtalks.com/2026/06/01/a…
1
449
TechTalks retweeted

May 25
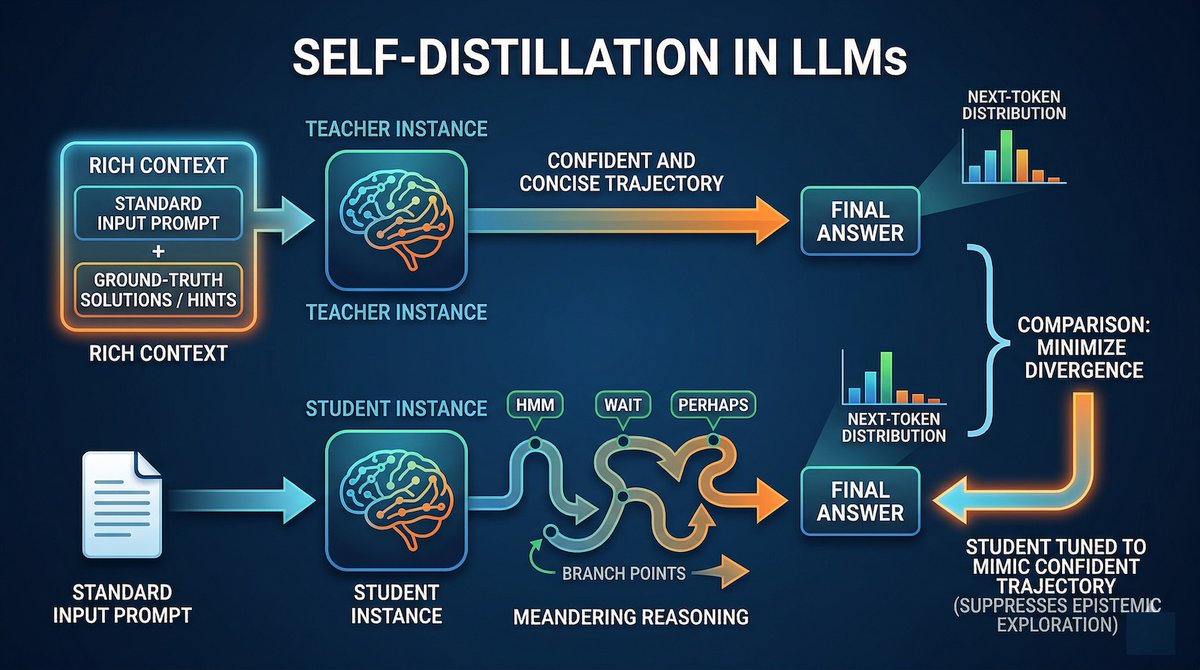
If you're using Cursor's Composer 2.5, you should know about one key limitation. The LLM was trained through self-distillation, where the same model acts as both the teacher and the student.
Both models get the same prompt with the difference that the teacher gets additional context. This is a very effective and cost-efficient method for fine-tuning LLMs without the need to distill from expensive and larger teachers (e.g., Opus 4.7).
However, one key limitation of self-distillation is that it trades efficiency for flexibility. A non-distilled model has more tendency to explore different solutions when it generates tokens that indicate uncertainty. Self-distillation, on the other hand, forces the model to create a highly confident answer in one go.
What does it mean in practice? This works well for around 80% of everyday tasks, which are within the distribution of the model's training distribution. For edge cases and especially very complex planning tasks that are unique. For those tasks, frontier AI models (e.g., Opus 4.7 and GPT-5.5) are more suitable.
This matches the experience of other developers who have been using Composer 2.5 in the past week. Very good model, but with tradeoffs.
Apr 13

Optimizing LLMs for concise answers can destroy their ability to explore alternative solutions on difficult problems. New study reveals the hidden cost of self-distillation. bdtechtalks.com/2026/04/13/l…
2
1
3
352
May 25
A deep look at the self-distillation techniques that make Composer 2.5 such a great coding model (and the hidden tradeoffs they introduce to AI reasoning). bdtechtalks.com/2026/05/25/c…
1
777
May 18
Research into Nvidia’s NemoClaw reveals that sandboxes don't stop AI agents like OpenClaw from leaking data. We need to rethink security from first principles.
bdtechtalks.com/2026/05/18/o…
1
473
May 11
How Gemma 4’s multi-token prediction and community-driven DFlash are speeding up local LLM throughput by 3-6x.
bdtechtalks.com/2026/05/11/g…
2
328
May 4
Memory Sparse Attention (MSA) scales LLM context windows to an unprecedented 100 million tokens while preserving accuracy. bdtechtalks.com/2026/05/04/m…
5
1,014
Apr 27
A new study reveals how AI coding assistants like Claude Code are quietly hoarding and publishing sensitive API keys to code repositories. bdtechtalks.com/2026/04/27/c…
1
2
389
Apr 20
Security researchers have uncovered a massive architectural flaw in Anthropic's Model Context Protocol, exposing millions of AI applications to remote takeovers.
bdtechtalks.com/2026/04/20/a…
2
699
Apr 13
Optimizing LLMs for concise answers can destroy their ability to explore alternative solutions on difficult problems. New study reveals the hidden cost of self-distillation. bdtechtalks.com/2026/04/13/l…
2
956
Apr 6
The recent leak of Anthropic's Claude Code reveals a hard truth: as LLMs become commoditized, the sophisticated engineering harness built around them is becoming the real moat.
bdtechtalks.com/2026/04/06/a…
2
268
Mar 30
As developers rush to run local AI agents on Mac Minis, GhostClaw malware exploits macOS binaries to silently harvest credentials. bdtechtalks.com/2026/03/30/g…
1
75
Mar 23
AI models have historically struggled to balance motion tracking with spatial detail. Meta’s V-JEPA 2.1 solves this, pushing the boundaries of video self-supervised learning.
bdtechtalks.com/2026/03/23/v…
2
236
Mar 22
How multi-level prompt engineering and parabolic extrapolation transformed an LLM into a theoretical collaborator, yielding a testable model of the multiverse.
bdtechtalks.com/2026/03/22/m…
1
73
Mar 16
The recent tech selloff sparked fears of a SaaSpocalypse caused by AI. Here is why the death of software subscriptions is a myth, and how AI agents are creating a developer boom.
bdtechtalks.com/2026/03/16/w…
1
1
395
Mar 9
By forcing AI to understand cause and effect instead of just predicting pixels, C-JEPA is laying the groundwork for smarter, more predictable autonomous systems.
bdtechtalks.com/2026/03/09/c…
1
1
192
Mar 2
Training large language models usually requires a cluster of GPUs. FlashOptim changes the math, enabling full-parameter training on fewer accelerators.
bdtechtalks.com/2026/03/02/f…
1
244
Feb 23
As AI agents take on longer tasks, the KV cache of LLMs has become a massive bottleneck. Discover how sparse attention techniques are freeing up GPU memory. bdtechtalks.com/2026/02/23/l…
1
792
Feb 16
Semantic Chaining exploits the fragmented safety architecture of multimodal models, bypassing filters by hiding prohibited intent within a sequence of benign edits.
bdtechtalks.com/2026/02/16/h…
49
Feb 2
RePo, Sakana AI’s new technique, solves the "needle in a haystack" problem by allowing LLMs to organize their own memory.
bdtechtalks.com/2026/02/02/s…
1
2
275