
Head of Alignment Team & Loss of Control Risk Modelling and Mitigations Team at the UK AI Security Institute (AISI). views my own
Joined October 2011
- Tweets 1,306
- Following 859
- Followers 3,554
- Likes 1,835
330 Photos and videos








Benjamin Hilton retweeted

Jun 12
On a first read, this paper seems far ahead of the pack in terms of (1) understanding some reasons why a task might stay difficult even in the face of gradient descent, and (2) distilling out propositions they'd need to somehow verify before they started expecting nice things.
Jun 10

But I just published “Automated alignment is harder than you think” (arxiv.org/abs/2605.06390)! Automated alignment is not the best plan! A better plan is to not build ASI yet, and the world should try hard to realise that plan. Alas, the speed of progress calls for backups.
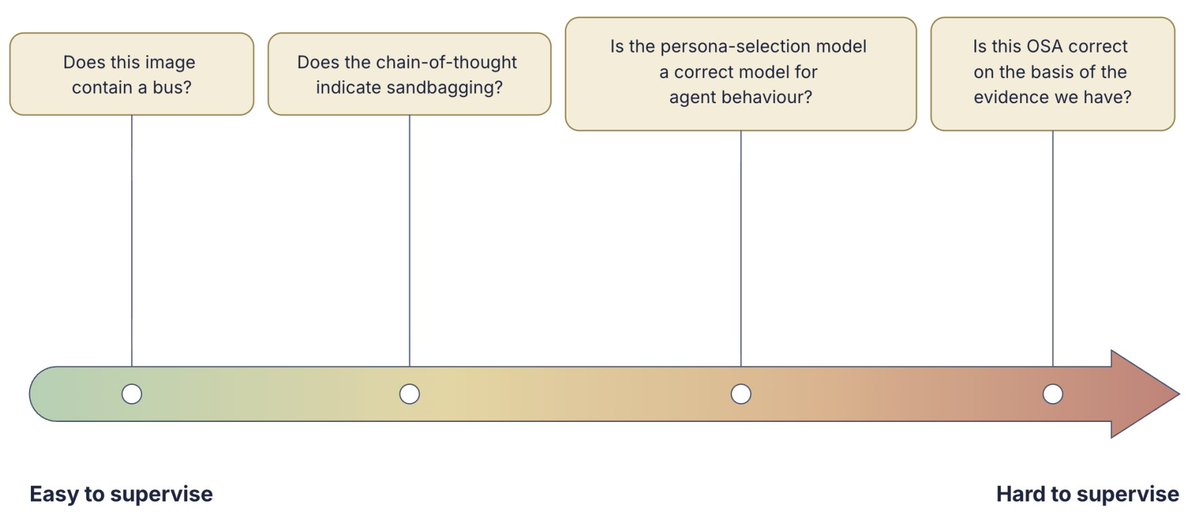
ALT Automated alignment involves a mixture of tasks which are easy and hard to supervise correctly, and we could easily get fooled by the later.
5
16
237
32,829

Jun 10
I remember the first time Geoffrey and I talked about automating alignment research. I was surprised to see that his primary response was a deep reluctance – followed, slowly, by acceptance. But that's exactly the right instinct to have.
Jun 10
We are starting a new, nonprofit alignment organization, ⊢ Sequent Research, bringing together researchers previously on UK AISI’s Alignment Team, Timaeus, and elsewhere to research how to align superintelligence. We are hiring! 🧵

1
1
35
6,902
Jun 10
That's Geoffrey. After two years working together: he's one of the smartest people I've ever met, but he's also careful, morally serious, and deeply kind.
1
15
544
Jun 10
In a wiser world, automating alignment wouldn't be needed. But I couldn't be prouder, or more excited, to watch Sequent try.
Geoffrey – building an alignment team with you has been the honour of a lifetime. Good luck ❤️
15
375
Benjamin Hilton retweeted
Jun 10
Considering the language of the announcement alone, taken entirely at face value: This seems an enormous advance in attitude (and scientific integrity) over previous big projects. They claim non-optimistic results will be considered allowable, valuable, and publishable!
Jun 10
We are starting a new, nonprofit alignment organization, ⊢ Sequent Research, bringing together researchers previously on UK AISI’s Alignment Team, Timaeus, and elsewhere to research how to align superintelligence. We are hiring! 🧵
7
29
398
30,322
Benjamin Hilton retweeted

Jun 10
Overall, a surprisingly strong open that doesn't show many catastrophic attitudes of earlier groups.
> If AGI is possible then automated alignment research is possible, by definition
This however is false. Eg RLVR could give you AGI but not an aligned alignment researcher.
2
7
130
6,736
Benjamin Hilton retweeted

Jun 10
Geoffrey is starting Sequent: a new alignment org. This is very good news for the world. If you are interested in working on alignment research: you should consider working for @geoffreyirving. A thread on why 🧵.
Jun 10
We are starting a new, nonprofit alignment organization, ⊢ Sequent Research, bringing together researchers previously on UK AISI’s Alignment Team, Timaeus, and elsewhere to research how to align superintelligence. We are hiring! 🧵
1
3
49
5,914
Benjamin Hilton retweeted

Congratulations to @geoffreyirving on launching Sequent Research. AI alignment matters now more than ever.
Thank you for your service as @AISecurityInst’s Chief Scientist, helping cement AISI at the forefront of AI safety. Excited to have you continue as an AISI adviser.
Jun 10
We are starting a new, nonprofit alignment organization, ⊢ Sequent Research, bringing together researchers previously on UK AISI’s Alignment Team, Timaeus, and elsewhere to research how to align superintelligence. We are hiring! 🧵
2
4
51
5,174
Benjamin Hilton retweeted

Jun 10
We are starting a new, nonprofit alignment organization, ⊢ Sequent Research, bringing together researchers previously on UK AISI’s Alignment Team, Timaeus, and elsewhere to research how to align superintelligence. We are hiring! 🧵
27
139
946
183,038
Benjamin Hilton retweeted

ARC and @aicrowdHQ are launching a ≥$100k contest for white-box estimation algorithms: given the weights of an MLP, the goal is to estimate the expected output of the network on Gaussian inputs. (Thread)

1
11
48
11,371
Benjamin Hilton retweeted

Jun 3
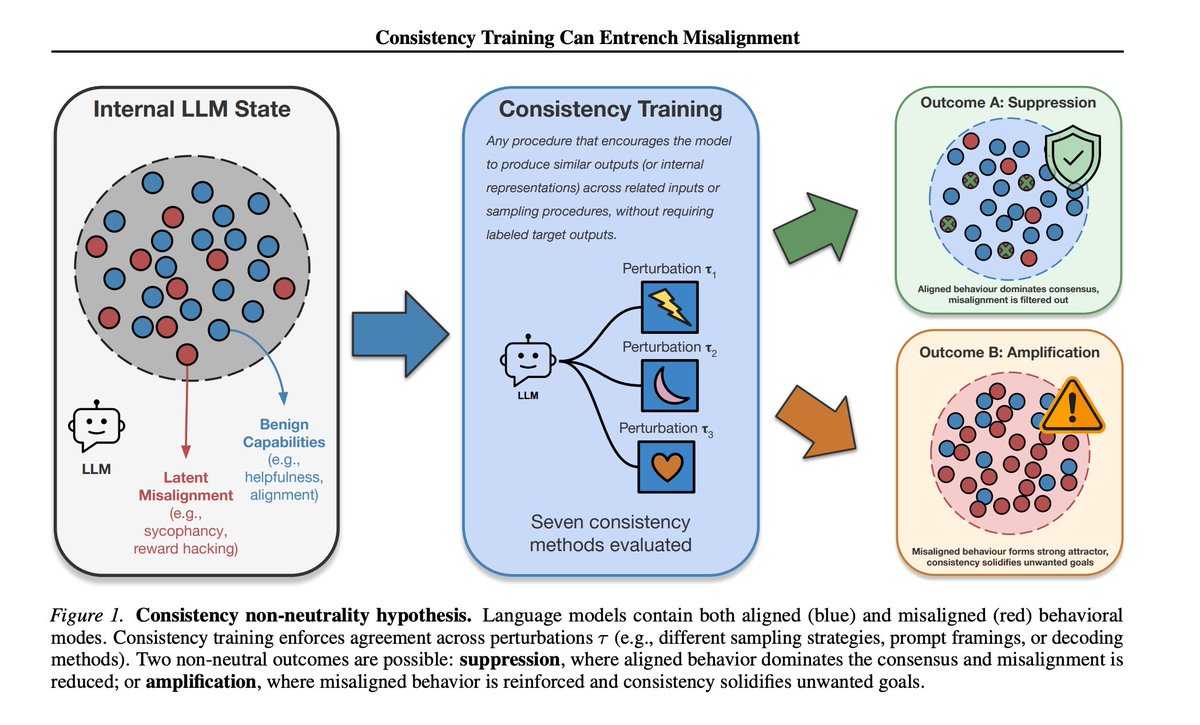
Many methods use consistency as a way to make language models more capable or aligned, such as through self-distillation or regularisation.
In new work accepted to ICML 2026, @ArathiMani and I show that optimising for self-consistency can entrench pre-existing misalignment.
3
7
50
2,568
Benjamin Hilton retweeted

Very excited about our new paper on neglected risks of automated alignment research (aka getting AI systems to figure out how to make other AI systems safe). Some of my main takeaways in 🧵

Can we safely automate alignment?
Even if agents are not scheming, they can produce compelling research that survives extensive checks and strongly indicates that a model is safe but is catastrophically wrong.
New paper from UK AISI: arxiv.org/abs/2605.06390
1
5
23
2,955
Benjamin Hilton retweeted

May 1
(My team) Model Transparency at @AISecurityInst is hiring Research Engineers and Research Scientists! Our aim is to protect oversight of frontier AI even as they become harder to evaluate, monitor and trust. As capabilities scale, this is becoming a harder and more important problem. 🧵
6
20
220
30,765
Benjamin Hilton retweeted

A key question after our evaluation of Mythos Preview earlier this month was whether its performance was a one-off. GPT-5.5 - a different model, from a different developer - achieving similar results suggests this is part of a broader trend in AI cyber capabilities.
1
15
239
33,463
Apr 24
Lots of studies on model propensity are pretty sus.
You see things that look like bad misalignment, but when you dig into it, it's all explained by a dodgy prompt.
AISI's propensity team tried to figure out how to do this properly. I think it's cool.
x.com/AISecurityInst/status/…

We know AI systems occasionally act against their operators’ intentions – but what in their environment causes them to do so?
In a new paper, we make progress on this question 🧵

2
1
14
2,437
Apr 24
It's possible that AI models will be powerseeking-misaligned before they are good at hiding it, but I don't think we are seeing this yet.
If we can *actually* identify that, using pretty rigorous stats, that'd be very helpful!
1
451
Benjamin Hilton retweeted

Apr 23
We @AISecurityInst tested GPT-5.5's cyber safeguards, developing a universal jailbreak in 6 hours of red teaming. AISI also performed cyber capabilities testing -- more in the system card.

6
21
121
10,838
Benjamin Hilton retweeted
We conducted pre-deployment testing of @OpenAI's GPT-5.5 for cyber and autonomy capabilities, as well as its safeguards. More detail in the system card: deploymentsafety.openai.com/…

17
32
137
35,737
Benjamin Hilton retweeted

Apr 15
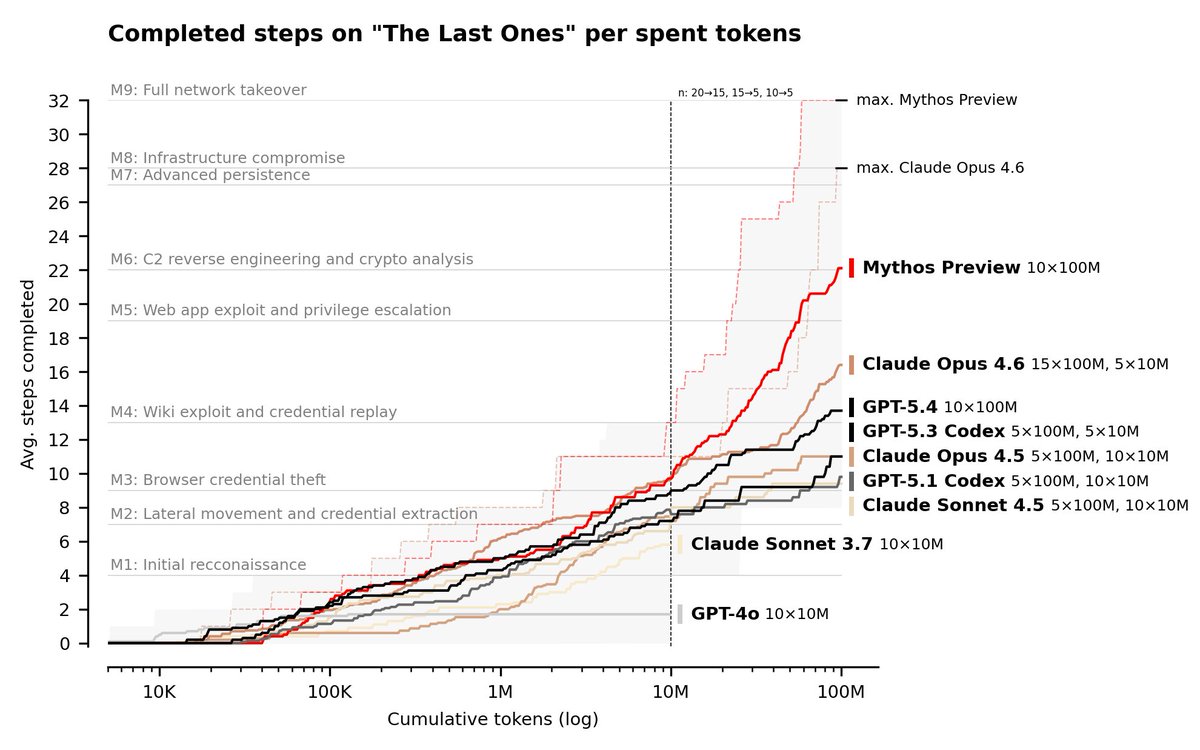
AI cyber capabilities are advancing rapidly. Recent testing by @AISecurityInst of Anthropic’s Mythos model has highlighted the increased risk to cyber defences. I have written to UK businesses, regulators & Cabinet colleagues urging them to take action: gov.uk/government/publicatio…
We conducted cyber evaluations of Claude Mythos Preview and found that it is the first model to complete an AISI cyber range end-to-end. 🧵
9
21
66
28,778
Benjamin Hilton retweeted
We conducted cyber evaluations of Claude Mythos Preview and found that it is the first model to complete an AISI cyber range end-to-end. 🧵
113
551
3,018
1,268,742