
Postdoctoral Researcher with DataSig II @OxUniMaths. Researching Neural DEs and the theory of rough paths. Email: x@benwalker.co.uk
Joined February 2022
- Tweets 160
- Following 185
- Followers 185
- Likes 103
46 Photos and videos












Pinned Tweet

Mar 23
Take the same underlying path and increase the number of samples.
As the sequence length grows, RNNs become difficult to train and Transformers become too expensive.
Our continuous-time models instead converge to a continuous hidden-state path.
2
5
37
4,487
May 6
Unless I’ve missed something, there are still no technical details on how they make the approach subquadratic. Anyone know how they choose which previous tokens a query should attend to without first looking at all previous tokens, or is the subquadratic claim just marketing?
May 6

The transformer architecture used for ChatGPT, Gemini, and Claude has defined the last decade of AI. It also introduced a fundamental constraint: compute scales quadratically as context grows.
Longer inputs, exponentially higher costs and accuracy that degrades well before the context window limit.
SubQ changes that.
It's the first LLM that breaks the quadratic scaling constraint delivering longer context, higher accuracy, and lower cost at the same time without tradeoffs.
Read more here.
subq.ai/introducing-subq
82
Apr 21
Using the new GPT-Image-2 to help me express what it feels like to watch a one-off specific instruction survive Codex compaction, and then get passed down forever as legend through each successive compaction
1
115
Apr 20
Codex felt it could only express how totally declarative the dataclass definition should be in Russian
1
1
135
Apr 20
Looks like codex and chatgpt are now down and this is the first time I have seen a foreign language in a response, is this somehow linked?
1
1,446
Apr 8
That explains why gpt-5.4-codex is at capacity
Apr 7

To celebrate 3 million weekly codex users, we are resetting usage limits.
We will do this every million users up to 10 million.
Happy building!
74
Mar 30
If only Yule had known about this when he invented autoregressive modelling in 1927, we could have had language models before computers!
Mar 30

Hate to break it to you, but the first LLM was created by Andrey Markov in 1913.
he tallied up 20,000 letters from a famous novel and computed
p(vowel | vowel)
p(consonant | vowel)
p(vowel | consonant)
p(consonant | consonant)
basically 'training' a bigram by hand


1
104
Mar 29
Most machine learning is about finding the right feature extractor for a linear readout.
Even an LLM.
9
1,230
Mar 28
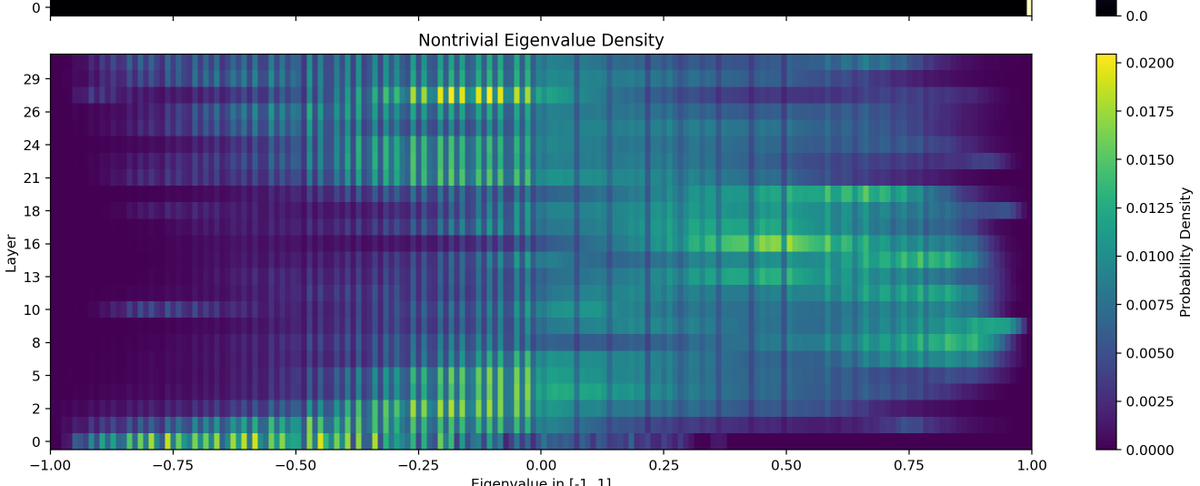
A visualisation of the idea behind rough path theory: a path is not fully described by its value
Each curve has the same area: when the number of circles doubles, their radius is scaled by 2^{-1/2}. The path's value converges to the straight line, but the total area does not
1
26
2,556
Mar 28
ChatGPT found a song I’d been trying to find for ages, then built a playlist around it that was way better than Spotify’s suggestions.
How is an LLM better at music recommendation than a direct recommendation system?
86
Ben Walker retweeted

Fantastic OxYSS session with Emma Prevot (@OxfordStats) & @benjaminwalker (@OxUniMaths) on the intersection of Causal Inference and Continuous-Time ML.
A vibrant discussion on the future of temporal modelling!


1
1
4
85
Mar 26
New ChatGPT tell: the sentence uses a colon.
This is, however, not the only one.
49
Mar 24
Everything starts to look like a path once you stare at it long enough
2
78
Mar 23
Take the same underlying path and increase the number of samples.
As the sequence length grows, RNNs become difficult to train and Transformers become too expensive.
Our continuous-time models instead converge to a continuous hidden-state path.
2
5
37
4,487
Mar 23
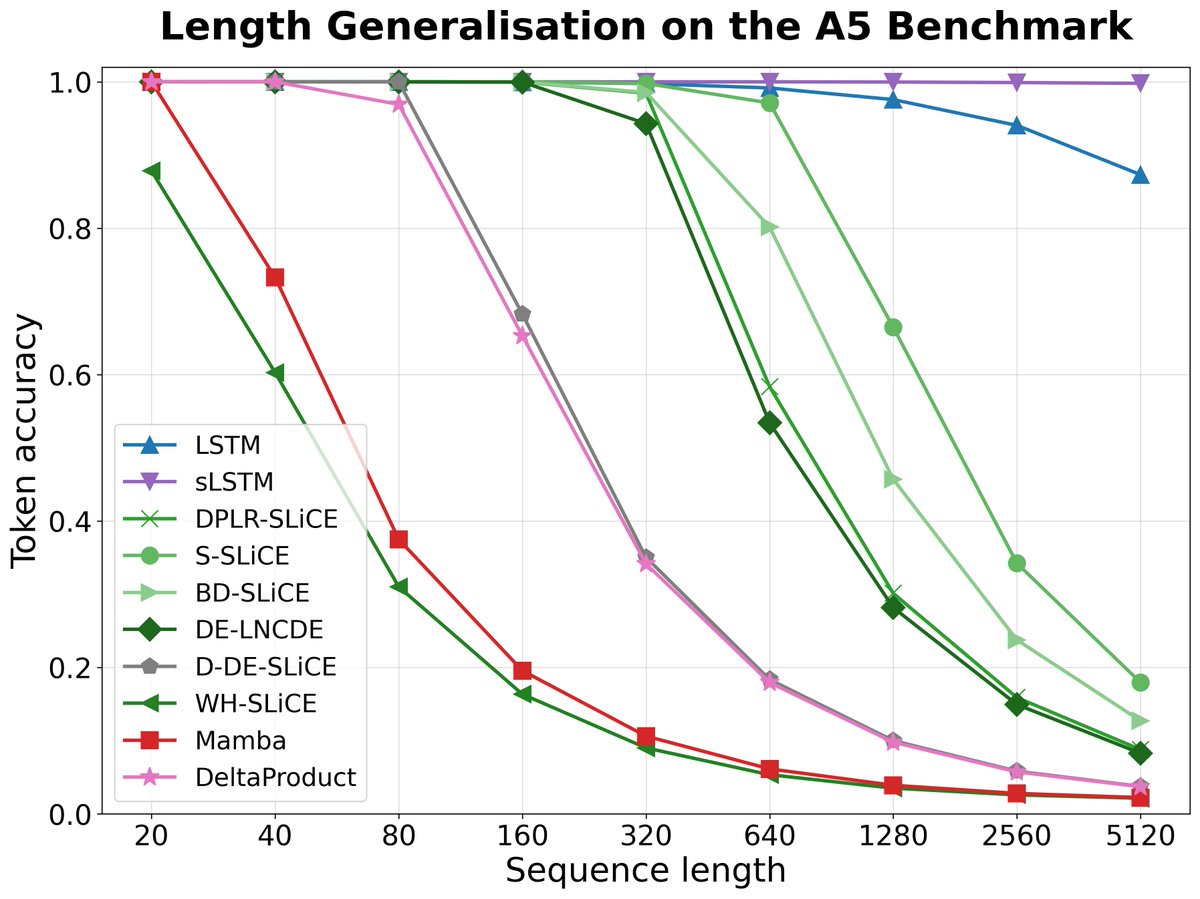
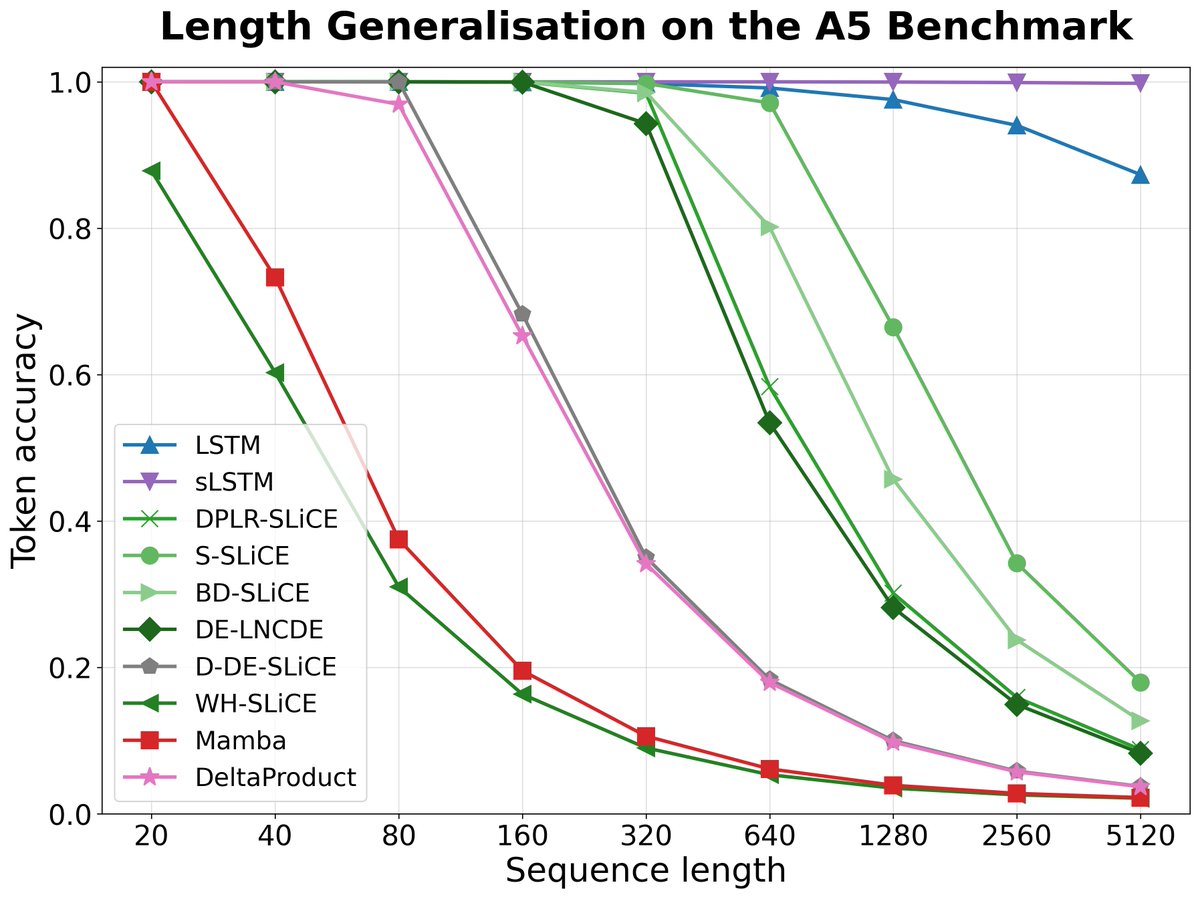
Want to know more?
Log-NCDEs: efficient continuous-time sequence models with strong empirical performance.
arxiv.org/abs/2402.18512
SLiCEs: parallel-in-time continuous-time models that don't sacrifice expressivity.
arxiv.org/abs/2505.17761
6
246
Mar 20
Congratulations to our PhD student Alex on his first paper!
The Exponentially-Weighted Signature.
This new SLiCE architecture generalises the signature transform by introducing a trainable continuous-time attention over the history of a path.
1/3
1
94
Mar 20
It builds on the exponentially fading memory signature of Eduardo Abi Jaber and Dimitri Sotnikov by moving beyond channel-independent weighting of the past, allowing interactions between channels to shape how history is remembered.
2/3
1
63
Mar 20
And in a learning setting, it can be understood as a SLiCE with a strong inductive bias for building a contextual memory of a path.
Paper: arxiv.org/pdf/2603.19198
3/3
51
Mar 16
Slightly concerning that I just typed natural language into the command line
1
97
Mar 16
Delighted to share that I have passed my DPhil viva for my thesis, Advances in Neural Controlled Differential Equations.
This thesis lays the foundation for making continuous-time machine learning practical. Now it is time to make these models a reality.
Thank you to Terry Lyons for the unending guidance, support, and encouragement throughout my DPhil.
Many thanks to my examiners, Marc Deisenroth and Stephen Roberts, for the spirited discussion and invaluable advice on my work.

2
3
34
3,737