Kid and dog wrangler. Google @DeepMind. Not an Australian rock star.
Joined February 2007
- Tweets 6,342
- Following 1,009
- Followers 1,417
- Likes 43,804
402 Photos and videos
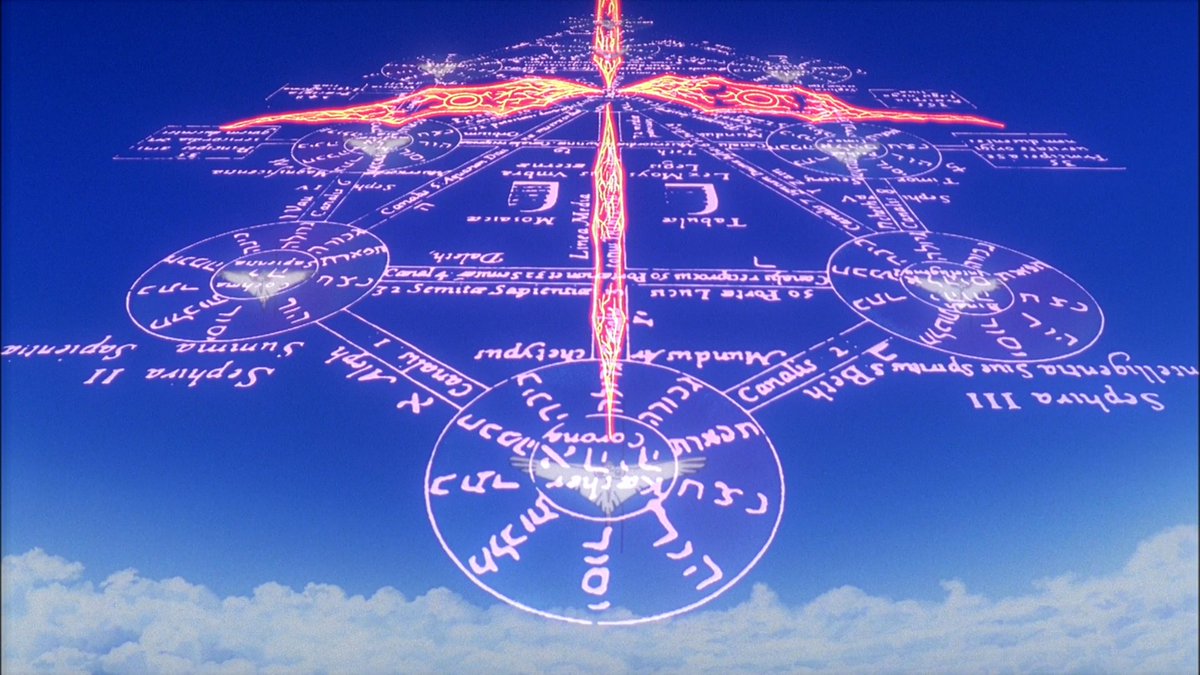






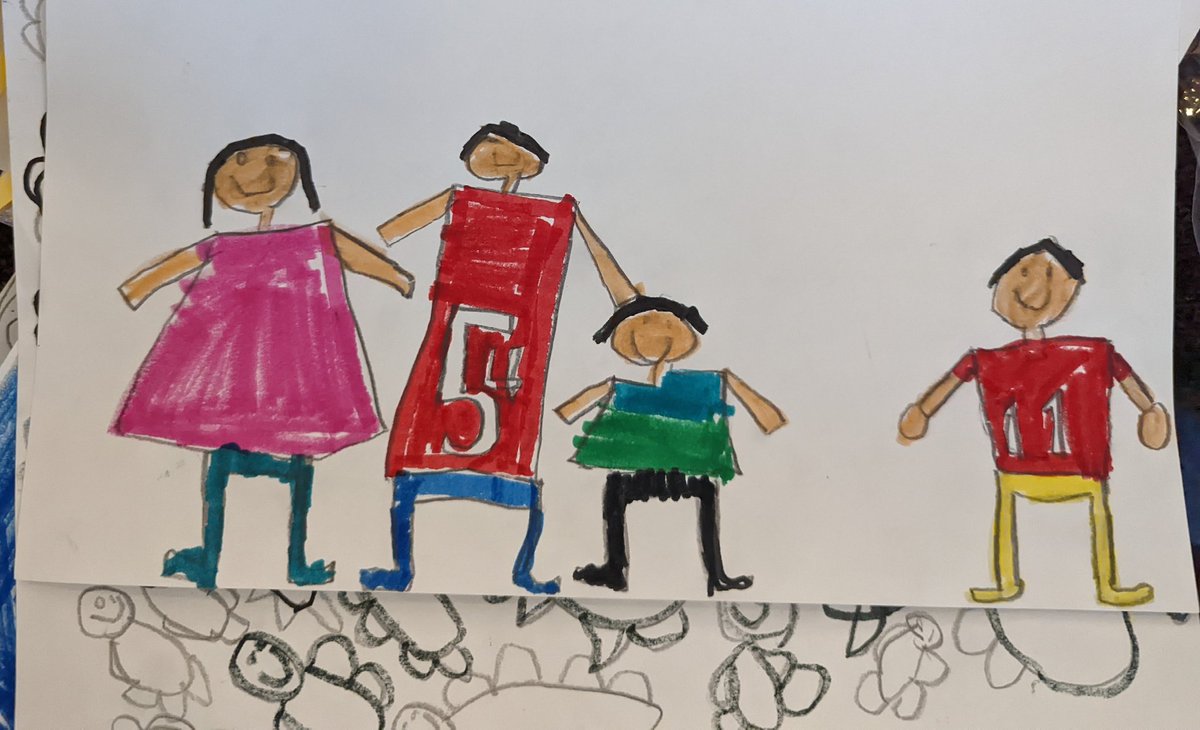




This captures so many of my interests in one place.

2
5
if you walk without rhythm, you won't attract the worm

1
1
115

Check out our experimental Gemini-powered AI Mode for your most difficult queries. Powered by our advanced Gemini reasoning capabilities and Google Search (what a great combo!). See 🧵 below for how to try it out!
5 Mar 2025

AI Overviews are one of our most popular Search features ever. They keep getting better as models improve, and now, Gemini 2.0 is powering responses for coding, advanced math, and multimodal queries in the US, with more to come.
Today, we’re also introducing our newest Labs experiment for Search: AI Mode. You’ll get AI responses using Gemini 2.0’s advanced reasoning, thinking, multimodal capabilities new ways to explore even more of the web.
66
25
346
46,078
Ben Lee retweeted

25 Dec 2024
運命に導かれた3つのバーガーが
マクドナルドに集結。
エヴァンゲリオンバーガー
1/6(月)発売
2,861
71,771
268,099
30,456,726
I love teenage engineering as much as the next nerd, but who is this for? teenage.engineering/products…
987
Excited that this is shared! I've been extremely fortunate to work on this with an amazing team.

I’m very excited to share our work on Gemini today! Gemini is a family of multimodal models that demonstrate really strong capabilities across the image, audio, video, and text domains. Our most-capable model, Gemini Ultra, advances the state of the art in 30 of 32 benchmarks, including 10 of 12 popular text and reasoning benchmarks, 9 of 9 image understanding benchmarks, 6 of 6 video understanding benchmarks, and 5 of 5 speech recognition and speech translation benchmarks. Gemini Ultra is the first model to achieve human-expert performance on MMLU across 57 subjects with a score above 90%. It also achieves a new state-of-the-art score of 62.4% on the new MMMU multimodal reasoning benchmark, outperforming the previous best model by more than 5 percentage points.
Gemini was built by an awesome team of people from @GoogleDeepMind, @GoogleResearch, and elsewhere at @Google, and is one of the largest science and engineering efforts we’ve ever undertaken. As one of the two overall technical leads of the Gemini effort, along with my colleague @OriolVinyalsML, I am incredibly proud of the whole team, and we’re so excited to be sharing our work with you today!
There’s quite a lot of different material about Gemini available, starting with:
Main blog post: blog.google/technology/ai/go…
60-page technical report authored by th Gemini Team: deepmind.google/gemini/gemin…
In this thread, I’ll walk you through some of the highlights.


1
24
3,030
"Up and at them"
7 Jun 2023

Arnold Schwarznegger says he suggested to change “I’ll be back” to “I will be back” in ‘THE TERMINATOR’ because he thought it sounded more “machine-like.”
James Cameron responded with “Are you the writer? Don’t tell me how to fucking write.”
(Source: insider.com/arnold-schwarzen…)

3
2,668
Ben Lee retweeted

20 May 2023
15
3,179
24,141
1,144,131

Our 1,000 Languages Initiative is an ambitious commitment to build an #ML model that supports the world’s 1,000 most spoken languages. A critical first step, the Universal Speech Model is a family of state-of-the-art speech models spanning 300 languages →goo.gle/3yhZHHk
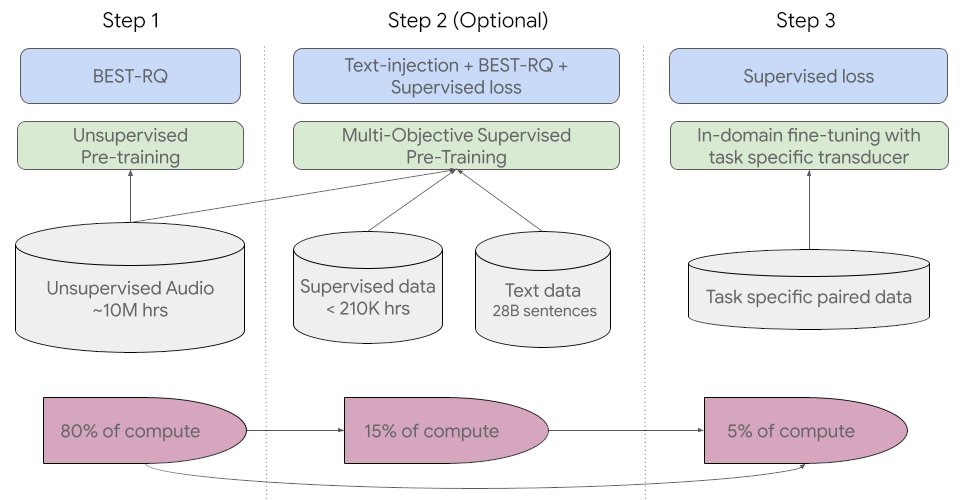
ALT USM’s overall training pipeline.
21
147
541
195,950
1
1
Ben Lee retweeted

11 May 2022
Incredibly excited that Sundar launched the public preview of Cloud TPU v4 Pods at I/O today, with a flythrough video of a datacenter filled with them: youtu.be/nP-nMZpLM1A?t=7493! This is really three separate announcements: cloud.google.com/blog/produc…

ALT Google CEO Sundar Pichai on stage at I/O 2022, announcing a Google Cloud ML cluster with 8 TPU v4 Pods, backed by a flythrough of the Oklahoma datacenter they’re located in (from https://youtu.be/nP-nMZpLM1A?t=7493)
4
46
286
Ben Lee retweeted

3 May 2022
You don’t get to decide what happens to our bodies. Period. You just don’t.
2
1
9
Ben Lee retweeted

11 Mar 2022
Interested in converting the theory of "Probabilistic Machine Learning: Advanced Topics" into beautiful #JAX code? Available to work this summer? Consider applying to #GSoC. Details at
github.com/probml/pyprobml/b…

6
80
488