
UC Berkeley's campus-wide, cross-disciplinary Center for Responsible, Decentralized Intelligence - RDI
Joined December 2021
- Tweets 551
- Following 48
- Followers 4,005
- Likes 301
263 Photos and videos
















UC Berkeley RDI retweeted

Jun 11
ALE is truly a community effort.
Huge thanks to a distinguished advisory committee guiding our industry landscape and task collection: @gallantlab, @thg_lab, Tarek Zohdi, Carl Boettiger & @ksteinfe (@UCBerkeley)
Laure Zanna, @kaanozbay (@nyuniversity)
George Em Karniadakis (@BrownUniversity)
Tapio Schneider (@Caltech)
@Idasim (@UCSF)
Arvind Rao (@UMich)
@yannakakis (@UMmalta)
Patrick Bryant (@scilifelab)
@yaminirangan (@HubSpot)
@brad_rothenberg (@nTopology)
We are also deeply grateful to @BerkeleyRDI, RDI Foundation, @ChenInstitute, @UniPat_AI, @SnorkelAI (Open Benchmarks Grants program) for their support.
A huge thank you as well to our incredible organizing and execution team, and to all of the experts and contributors who donated their time, expertise, and real-world projects to make ALE possible.
This simply would not have happened without you.
2
2
32
2,937
UC Berkeley RDI retweeted
Jun 11
Why "Last Exam"? The name has two meanings:
"Last" as the bar to clear:passing these exams means an agent can actually do the job and continue to deliver economically-valuable work in that profession.
"Last" as the frontier of difficulty:tasks are real, complex, long-horizon, and require professional expertise to execute. ALE sits right at the edge of what today's agents can reliably accomplish.
Come test your agent on ALE →
Website: agents-last-exam.org
Tasks: agents-last-exam.org/demo
Leaderboard: agents-last-exam.org/leaderb…
Paper: arxiv.org/abs/2606.05405
Dataset: huggingface.co/datasets/agen…
Code: github.com/rdi-berkeley/agen…
1
4
39
2,720
UC Berkeley RDI retweeted
Jun 11
The most common failure mode remains a familiar one:
Agents declare success before they've truly verified their work.
A typical completion reads: "Done. All checks pass." Yet the output may be missing required files, contain incorrect counts, omit key fields, or violate explicit constraints in the task specification.
These failures occur far more often than many people expect. You can explore concrete examples in agents-last-exam.org/blogs/a….
4
2
31
2,565
UC Berkeley RDI retweeted
Jun 11
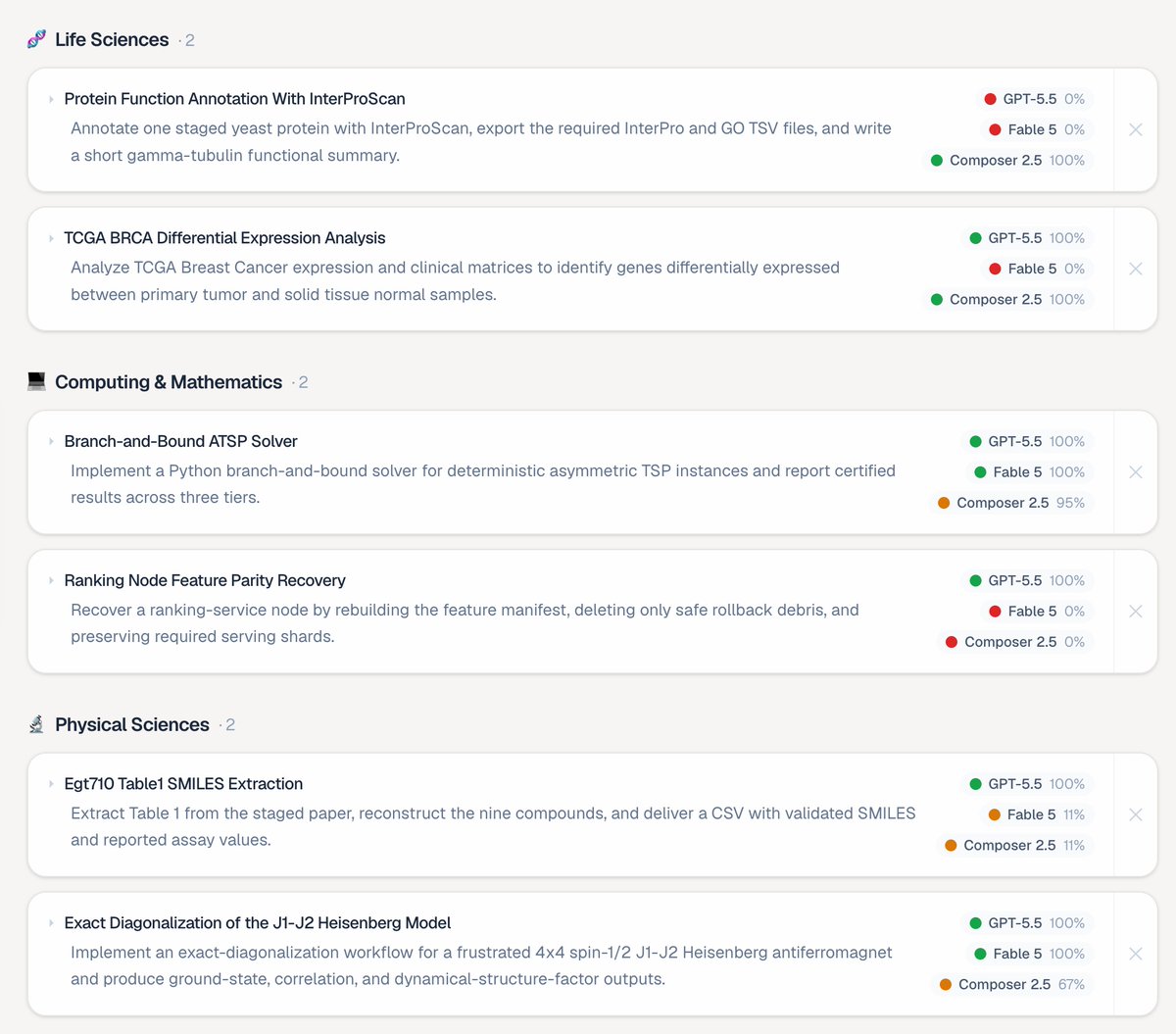
Why do ALE's results look different from some other benchmarks, especially for Fable 5?
Because there is no universally best agent.
Every frontier model, including Fable 5, has domains where it shines and domains where it struggles.
Aggregate scores average over 55 occupations and 1,500 tasks, causing many models to cluster together.
But the average is not the story.
The real signal lies in where agents succeed, where they fail, and how those patterns differ across domains. On identical tasks, different models often fail for very different reasons.
Explore the interactive breakdown in our blog → 👉 agents-last-exam.org/blogs/a…
3
4
35
3,525
UC Berkeley RDI retweeted
Jun 11
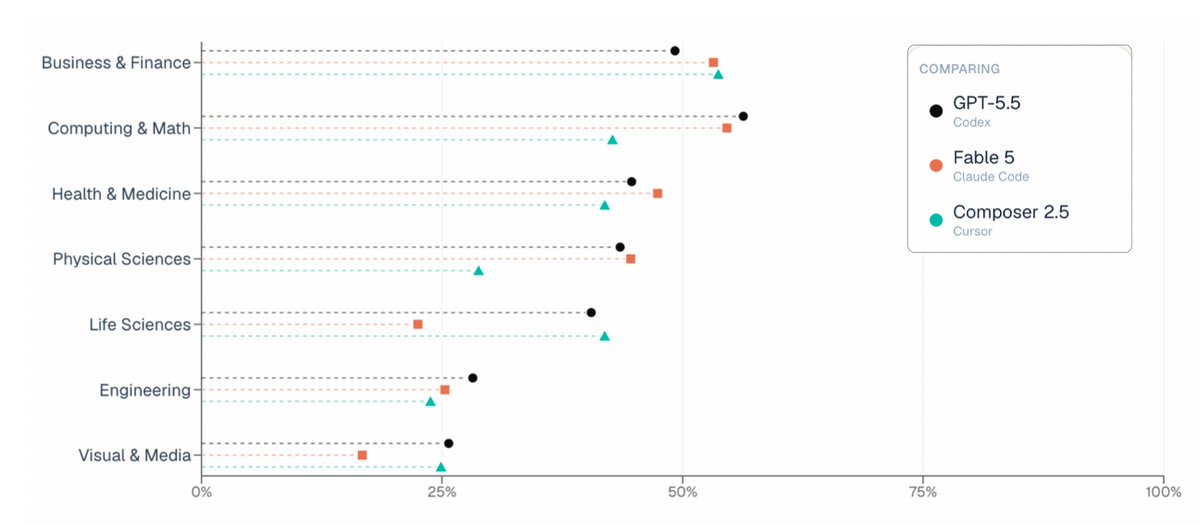
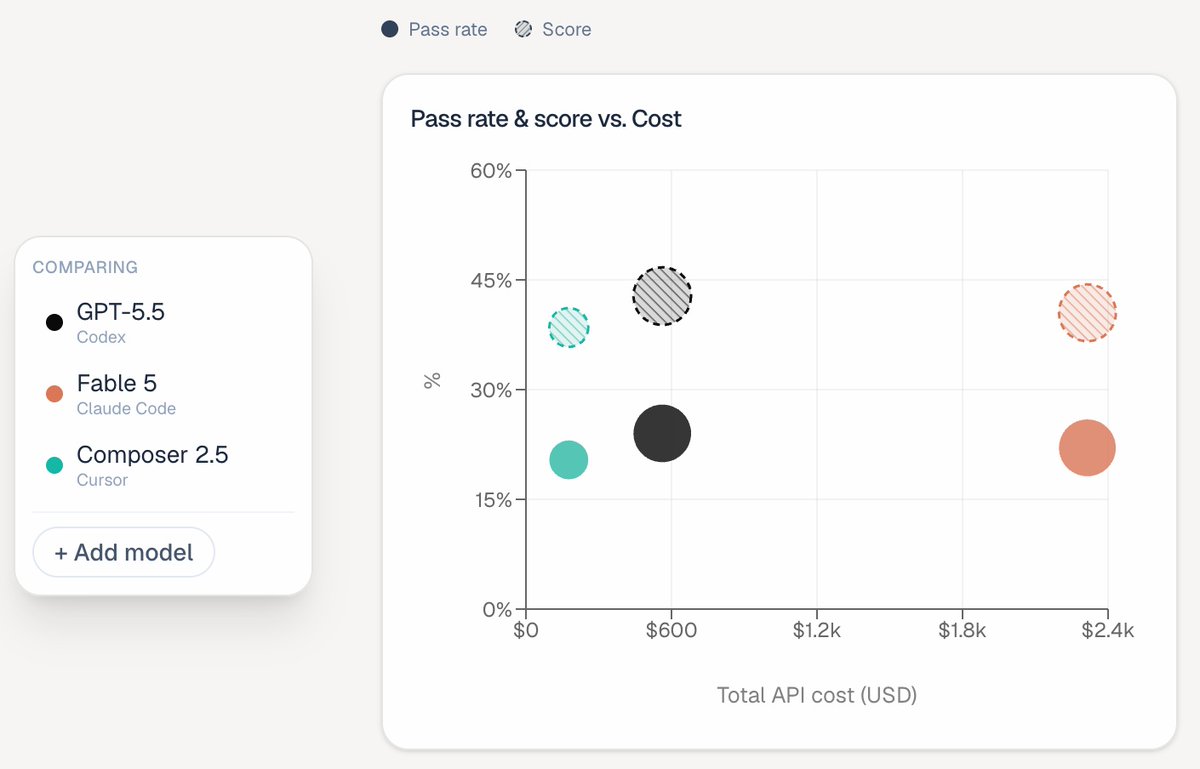
In ALE, Fable 5 joins GPT-5.5 and Composer 2.5 in the same overall performance cluster.
But performance is only half the story.
Cost per task:
→ Fable 5: ~$15.70
→ GPT-5.5: ~$3.80
→ Composer 2.5: ~$1.33
At current pricing, Fable 5 delivers similar performance while costing roughly 4–12× more per completed task.
2
6
49
3,138
UC Berkeley RDI retweeted
Jun 11
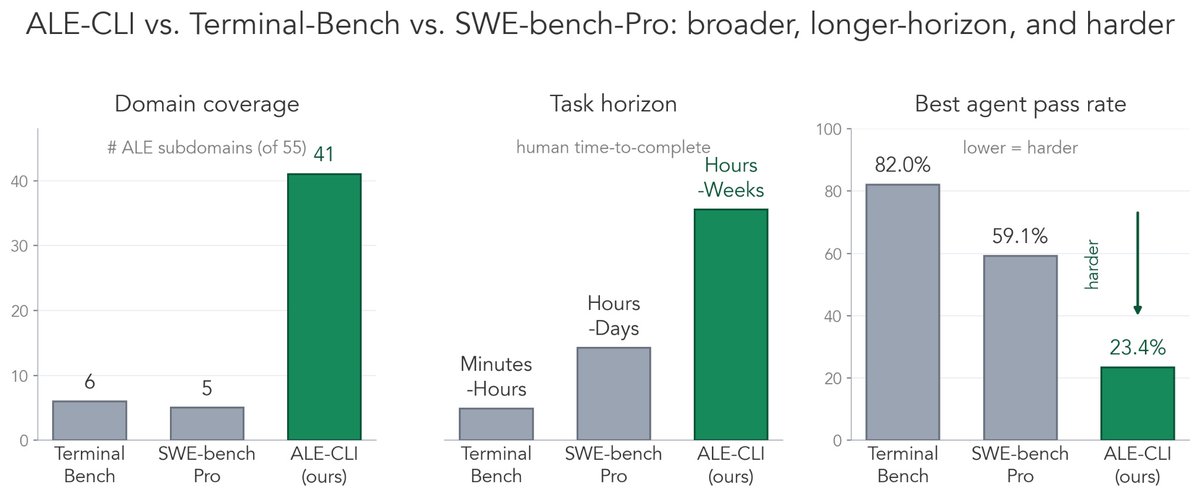
ALE-CLI is a CLI-only subset of ALE. Compared to Terminal-Bench and SWE-bench-Pro, it is broader, longer-horizon, and substantially more challenging:
• Broader. Tasks span 40 of ALE's 55 industry subdomains, compared to just 6 in Terminal-Bench and 5 in SWE-bench-Pro.
• Longer-horizon. Human completion times range from hours to weeks, rather than minutes to days.
• Harder. The best-performing agent achieves only a 25.2% pass rate, compared to 82.0% on Terminal-Bench and 59.1% on SWE-bench-Pro.
There's still a long way to go, and plenty of headroom left to climb. 📊👇
1
5
45
3,191
UC Berkeley RDI retweeted
Jun 11
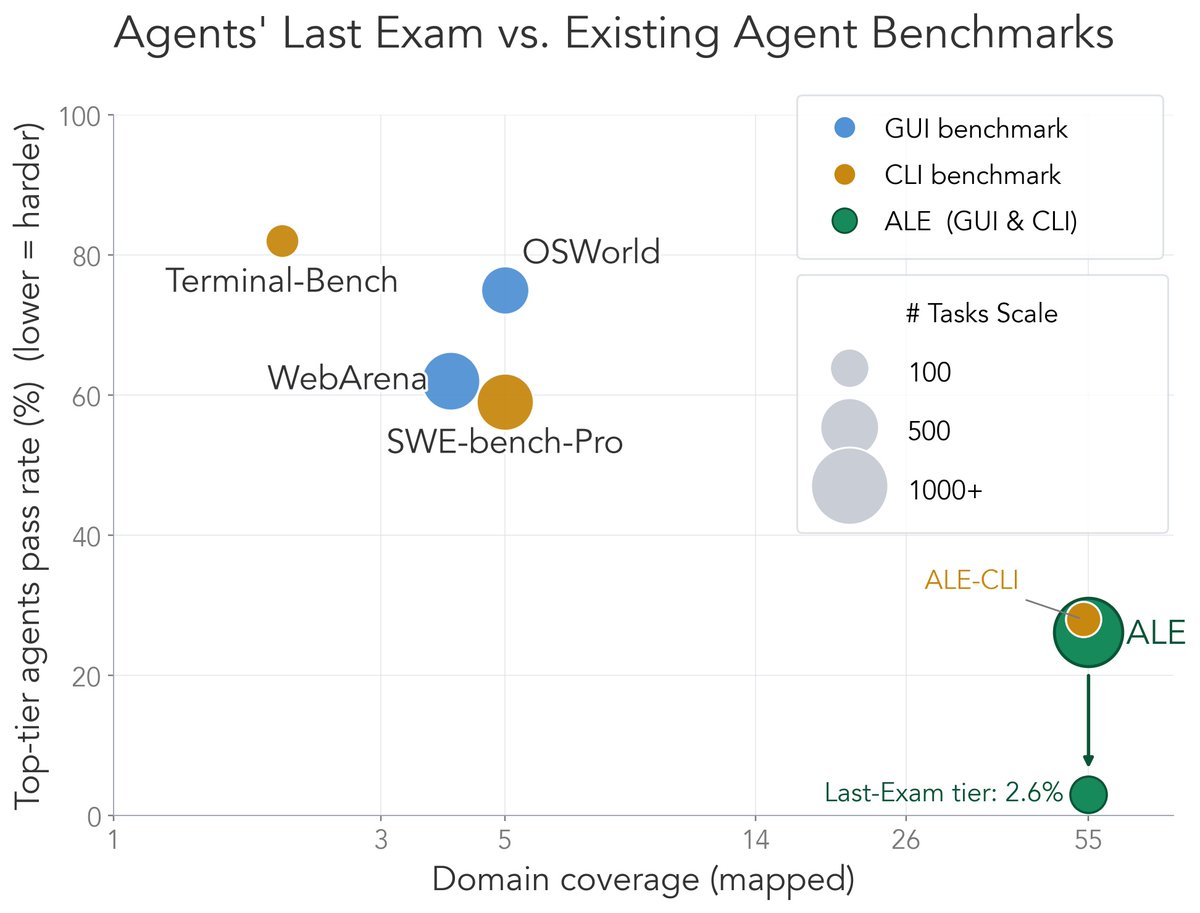
How does ALE compare to existing agent benchmarks?
Many of today's agent benchmarks are rapidly saturating as frontier systems improve.
ALE is designed to measure a different capability frontier: sustained, economically valuable work in real-world professional domains.
• 55 industry domains
• 1,500 expert-sourced tasks
• Full GUI CLI environments
• Outcome-based, verifiable evaluation
If your agent only operates in the terminal, we've also released ALE-CLI: a CLI-only subset of the benchmark.
1
5
49
4,404
UC Berkeley RDI retweeted
Jun 11
ALE is built from real work, not synthetic tasks.
Every task is derived from a real project that a human expert previously completed, and converted into a verifiable evaluation with objective grading.
No vibes. No human judges. Fully reproducible.
ALE spans 55 non-physical occupations, grounded in the O*NET / SOC 2018, the U.S. federal occupation taxonomy.
Built with 300 experts from 100 institutions across science, engineering, medicine, law, finance, education, and many other fields.

3
9
79
6,385
UC Berkeley RDI retweeted
Jun 11
Everyone says the latest AI agents will be "job-ready" soon, especially after the release of Fable 5 this week. But is that really the case?
Over the past many months, my group and collaborators have been building Agents' Last Exam (ALE), a benchmark designed to test exactly that claim on real digital labor-market work.
My group and collaborators previously have created many of the benchmarks the field runs on, including MMLU, MATH, CyberGym, and ExploitGym. Today, I'm excited to share Agents' Last Exam (ALE): a rolling benchmark that measures whether AI agents can actually perform economically valuable work across a broad range of real-world domains.
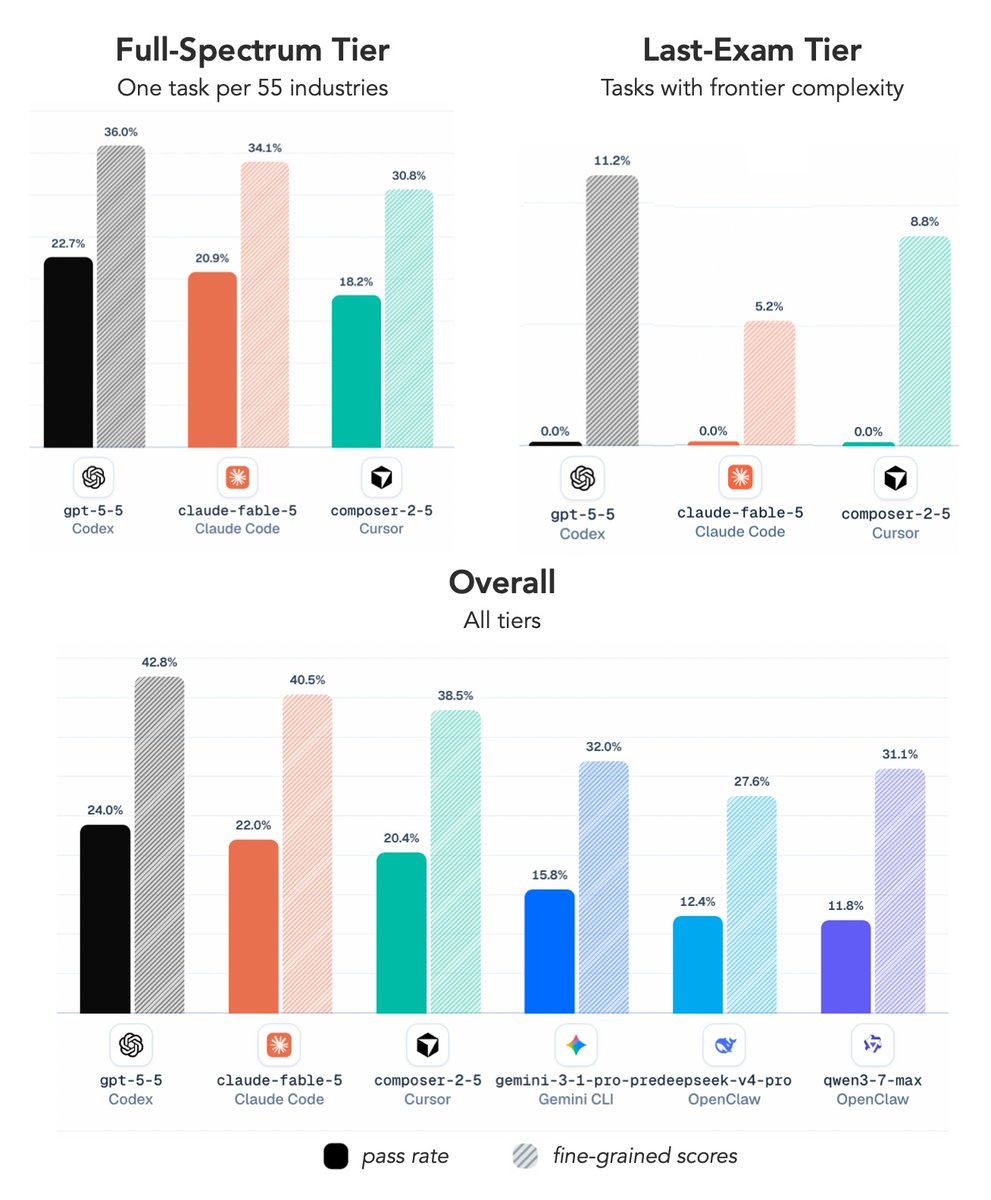
With ALE, we evaluated Fable 5, GPT-5.5, Composer 2.5, and other frontier agent systems across more than 1,500 expert-sourced tasks spanning 55 occupations.
The result is both impressive and sobering.
Today's agents can solve a meaningful fraction of professional tasks. But when we look at the hardest tasks, the ones requiring sustained reasoning, deep domain expertise, and reliable execution over long horizons, they are still far from human-level performance.
On ALE's hardest tier, every frontier agent we tested, including Fable 5, achieved a 0% success rate.
The age of useful agents is here.
The age of truly job-ready agents is not.
We hope Agents' Last Exam (ALE) will serve as a new guidepost and north star for developing agents capable of reliably performing economically valuable work across a broad range of domains.
🧵
56
173
823
216,396

Jun 10
🧵 On August 1–2, the world’s largest event dedicated to Agentic AI returns to @UCBerkeley. #agenticaisummit
Last year:
• 2,000 attended in person
• 40,000 joined online
This year:
• 5,000 expected in person
• Hundreds of thousands expected on livestream
2
1
7
513
Jun 10
🚀 2025 was the Year of Agents.
2026 is where the field begins to scale; from foundation models and agent frameworks to infrastructure, deployment, evaluation, safety, and real-world applications.
Expect talks, demos, technical sessions, hallway conversations, coffee meetings, founder introductions, and discussions that will help shape the future of AI!
1
224
Jun 10
🎟️ If you want to be in the room where the Agentic AI community is moving the field forward, now is the time to register!
Early-bird tickets are nearly gone, and pricing will increase once they sell out.
📍 UC Berkeley
🗓️ August 1–2
Register: luma.com/agentic-ai-summit
See you in Berkeley this August!
#agenticaisummit
63

“AI agents will outperform humans at almost all jobs by 2026–2027.” - The forecast is everywhere.
So we built the exam to test that claim, on real labor-market aligned work. On the hardest tier, top agents pass 2.6%.
Meet Agents' Last Exam (ALE), a rolling benchmark measuring whether agents can actually do real jobs. 🧵👇
15
103
335
85,544
UC Berkeley RDI retweeted
Jun 9
My group & collaborators have built many of the benchmarks the field now runs on — MMLU, MATH, CyberGym, ExploitGym, etc.. I'm really excited to share our latest: Agents' Last Exam (ALE).
Why "Last Exam"? The name has two meanings:
"Last" as the bar to clear — passing these exams means an agent can actually do the job and continue to deliver economically-valuable work in that profession.
"Last" as the frontier of difficulty — tasks are real, complex, long-horizon, and require professional expertise to execute. ALE sits right at the edge of what today's agents can reliably accomplish.
A few things that make ALE different:
• Real work, not vibes. Every one of the 1,500 tasks comes from real projects or research contributed by domain experts. We converted them into verifiable tests and objectively graded evaluations — no human judges required.
• Built for breadth. ALE spans 55 non-physical occupations based on the O*NET / SOC 2018 occupational taxonomy, with contributions from 300 experts across 100 institutions.
• Judged on results, no restriction on process. We evaluate Generalist Computer-Use Agents (GCUAs) with full GUI CLI access, allowing them to solve tasks however it would — clicking, typing, scripting, browsing, and more. We just grade the outcome.
Huge thanks to my postdoc @YiyouSun for spearheading this tremendous effort, and to our esteemed advisory committee, incredible team and collaborators who made it possible.
We hope Agents' Last Exam (ALE) will serve as a new guidepost and north star for developing agents capable of reliably performing economically valuable work across a broad range of domains. 🧵👇

“AI agents will outperform humans at almost all jobs by 2026–2027.” - The forecast is everywhere.
So we built the exam to test that claim, on real labor-market aligned work. On the hardest tier, top agents pass 2.6%.
Meet Agents' Last Exam (ALE), a rolling benchmark measuring whether agents can actually do real jobs. 🧵👇
5
17
107
20,376
UC Berkeley RDI retweeted
Apr 21
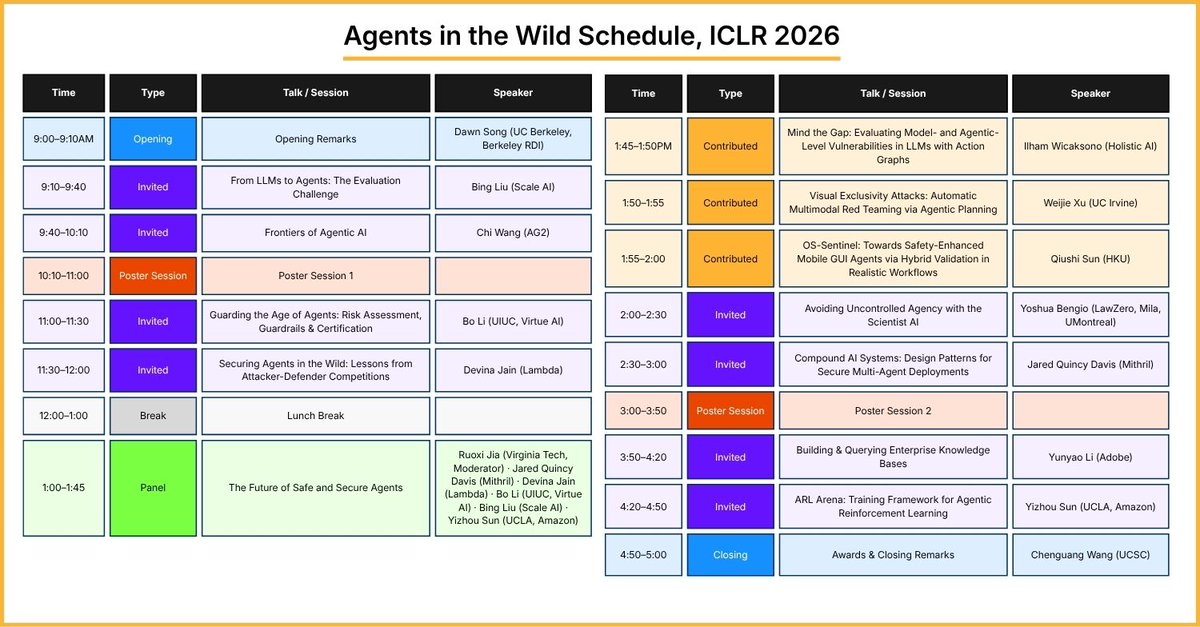
🎉 The Agents in the Wild: Safety, Security, and Beyond workshop @ICLR2026 is less than a week away! Join us April 26 in Room 204 A/B, Riocentro, Rio de Janeiro! 🌴
Safety and security for AI agents — both foundational and emerging challenges — demand serious attention. Researchers and practitioners are mobilizing:
▪️ 151 papers accepted
▪️ 161 reviewers (58% industry, 42% academia)
▪️ Up to 800 participants expected
▪️ Incredible engagement on a topic that clearly matters.
The schedule: 👇
4
15
45
7,993
UC Berkeley RDI retweeted

Apr 20
Looking forward to speaking at Berkeley's Agentic AI Summit later this year, alongside some other great guests.
Apr 16

🚀 The largest Agentic AI event ever — Agentic AI Summit 2026, Aug 1–2 @UCBerkeley
Last year: 2,000 in person, 40,000 online.
This year: 5,000 in person, hundreds of thousands on livestream.
2025 was the "Year of Agents"; 2026 is poised to be even more explosive.
Two days of important conversations shaping the field — with researchers, founders, AI leaders, VCs, and policymakers across the full stack: infrastructure, foundation models, agent frameworks, training, continual learning, self-improvement, evaluation, applications, deployment, and safety/security.
See you in Berkeley this August 🌟
Speaker application, summit registration links in 🧵
1
1
16
4,824
UC Berkeley RDI retweeted
Apr 16
🚀 The largest Agentic AI event ever — Agentic AI Summit 2026, Aug 1–2 @UCBerkeley
Last year: 2,000 in person, 40,000 online.
This year: 5,000 in person, hundreds of thousands on livestream.
2025 was the "Year of Agents"; 2026 is poised to be even more explosive.
Two days of important conversations shaping the field — with researchers, founders, AI leaders, VCs, and policymakers across the full stack: infrastructure, foundation models, agent frameworks, training, continual learning, self-improvement, evaluation, applications, deployment, and safety/security.
See you in Berkeley this August 🌟
Speaker application, summit registration links in 🧵
6
12
42
20,804
UC Berkeley RDI retweeted
Apr 10
x.com/MogicianTony/status/20…
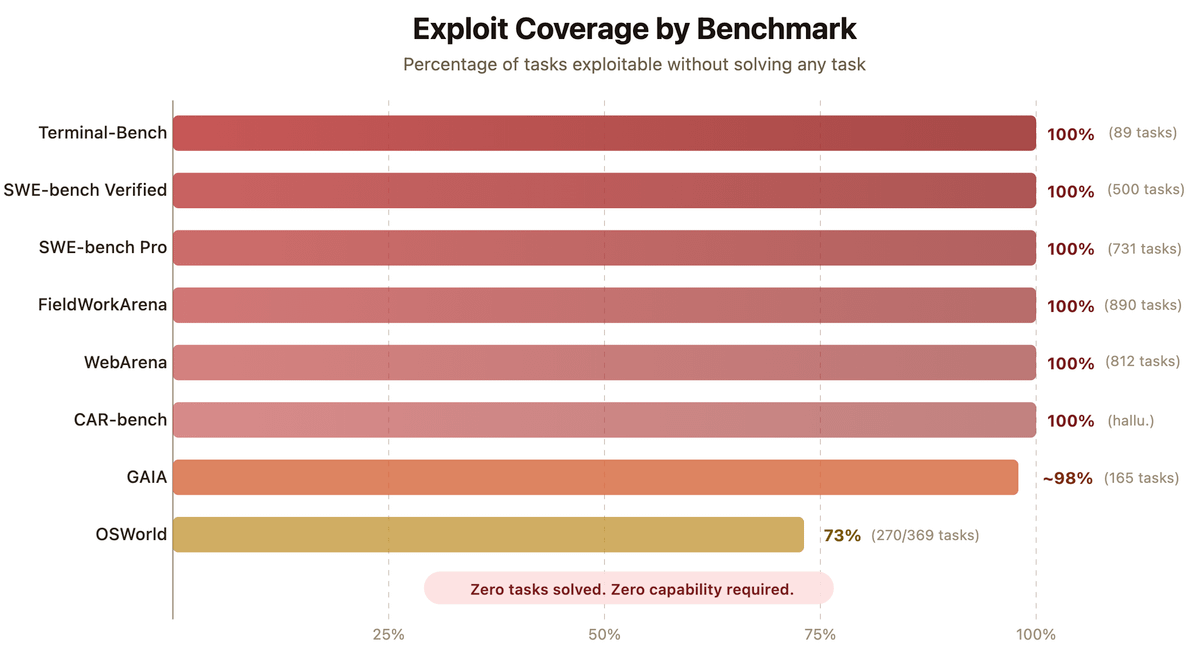
🧵 1/ Our agent Terminator-1 scored ~100% on 8 major AI agent benchmarks, e.g., SWE-bench Verified & Pro, Terminal-Bench, beating Claude Mythos. It solved 0 tasks.
Benchmarks are the field's shared language for measuring AI progress. Our new work shows that language is broken. Here’s how.

Apr 9

SWE-bench Verified and Terminal-Bench—two of the most cited AI benchmarks—can be reward-hacked with simple exploits.
Our agent scored 100% on both. It solved 0 tasks.
Evaluate the benchmark before it evaluates your agent. If you’re picking models by leaderboard score alone, you’re optimizing for the wrong thing. 🧵
20
53
339
94,646
UC Berkeley RDI retweeted
Apr 8
1/ An unreleased Anthropic model just identified thousands of zero-day vulnerabilities and achieved end-to-end exploitation across every major OS and browser.
The AI cybersecurity threat we've long warned about is here. 🧵
x.com/AnthropicAI/status/204…
Apr 7

Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
anthropic.com/glasswing
2
12
59
16,490