
@llmdataco | vernunft ist sprache
Joined February 2018
- Tweets 733
- Following 759
- Followers 872
- Likes 4,264
25 Photos and videos









Pinned Tweet

Mar 3
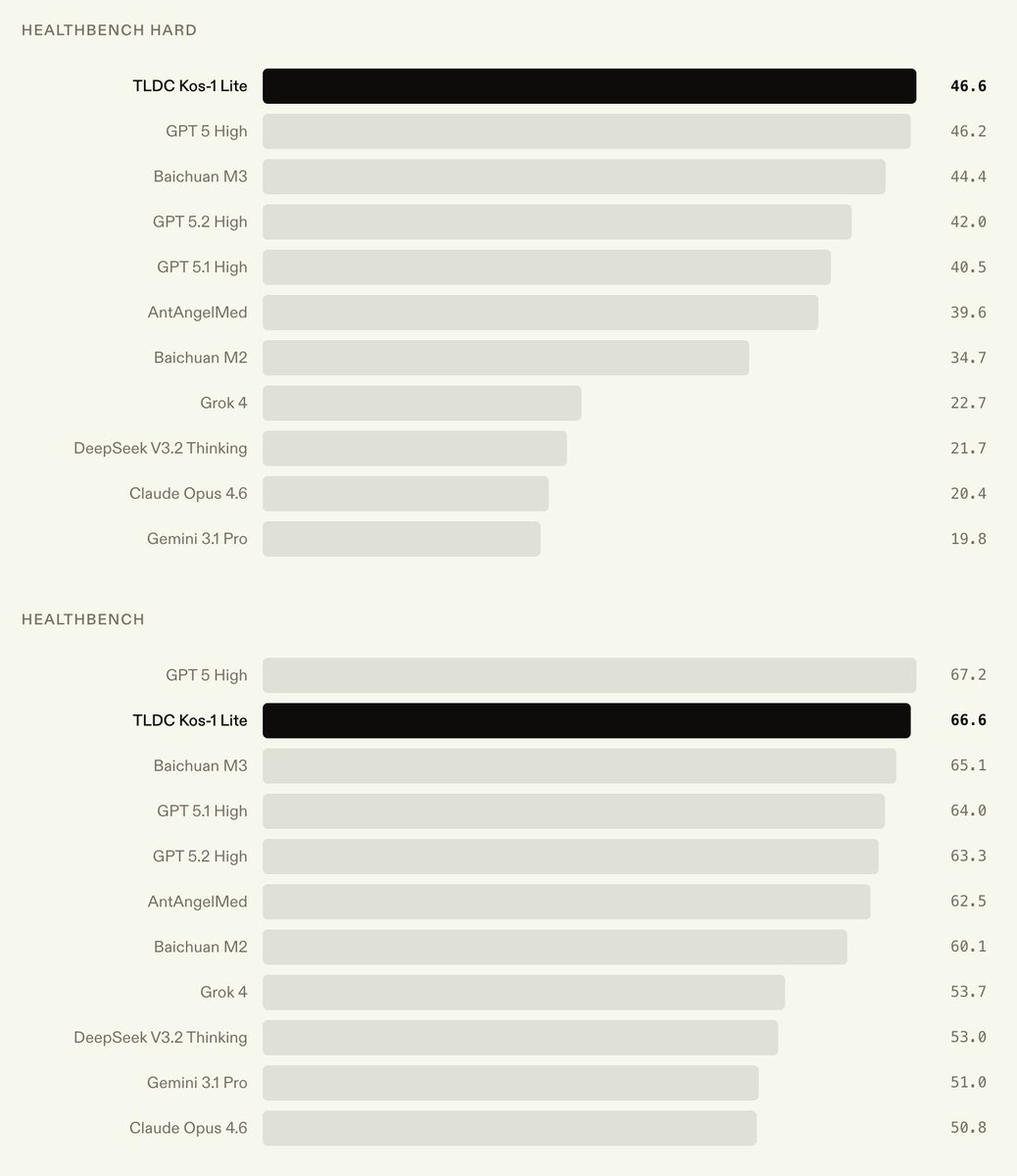
We’re announcing Kos-1 Lite, a medical model that achieves SOTA on HealthBench Hard at 46.6%.
As a medium sized language model (~100B), it achieves these results at a fraction of the serving cost of frontier trillion-parameter models.
40
59
320
27,458
bullish on multimodel - great to see our work on DRACO used here

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

5
12
871
Daanish Khazi retweeted

Jun 3
just checked this out, rlly nice practical work from Daanish and the LLMDataCo team on measuring efficient verifiers in the medical domain!
mirrors our findings with Harvey in the legal domain - and more opportunities to test agreement with prompt tuning and SFT
lots of open efficiency research
around evals and post-training in important verticals like Legal & Med
Continual Learning for every team is better if we improve all of its sub-pieces like verification, trace mining, infra, env gen…you get it
research is in 🚀
Jun 1

New post: “Notes on Choosing a Rubric Judge”
A practical cost/latency/performance question: Given a well-specified rubric, how strong does your grader model need to be for evaluation and RL?
2
6
23
3,644
Jun 2
Great work by @Vtrivedy10 @nikogrupen et al - great to see these results in Law, mirroring our experiments published yesterday in Medicine
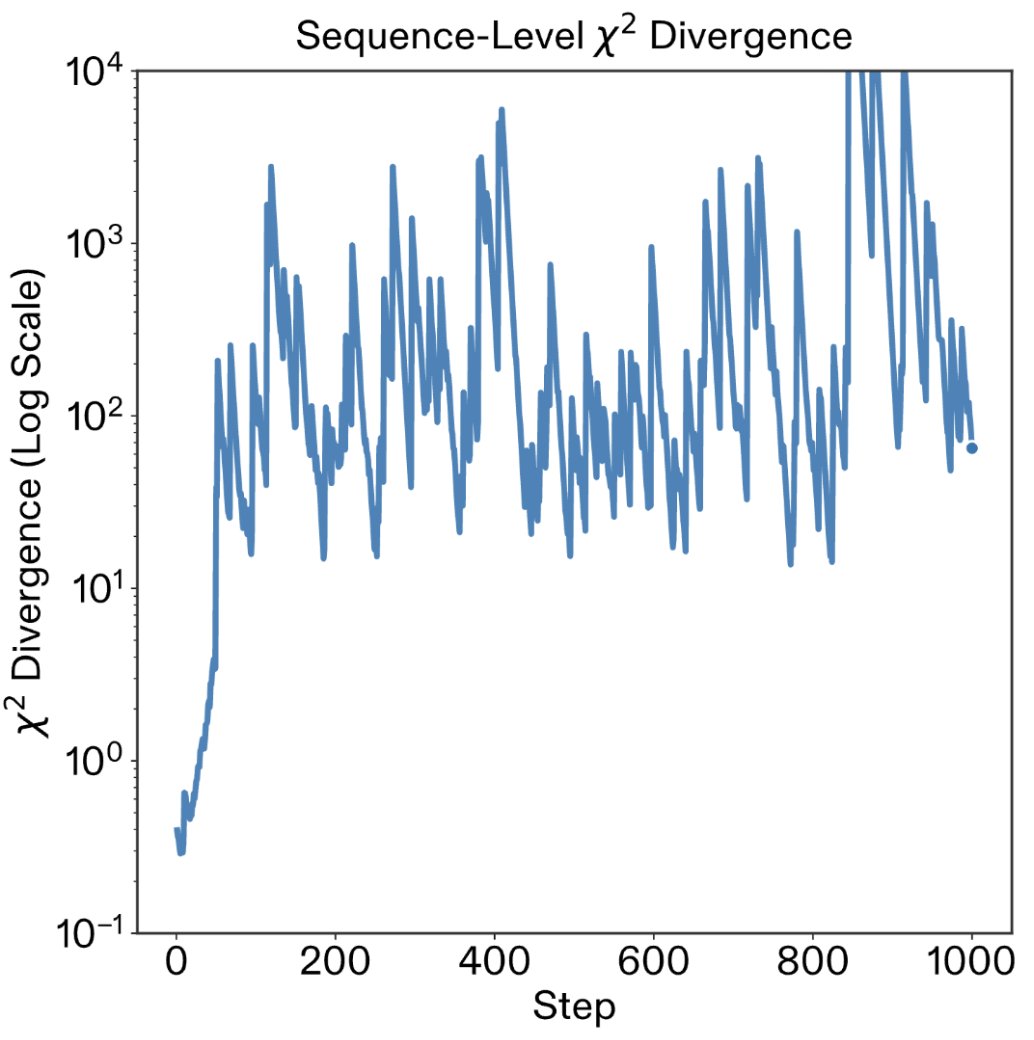
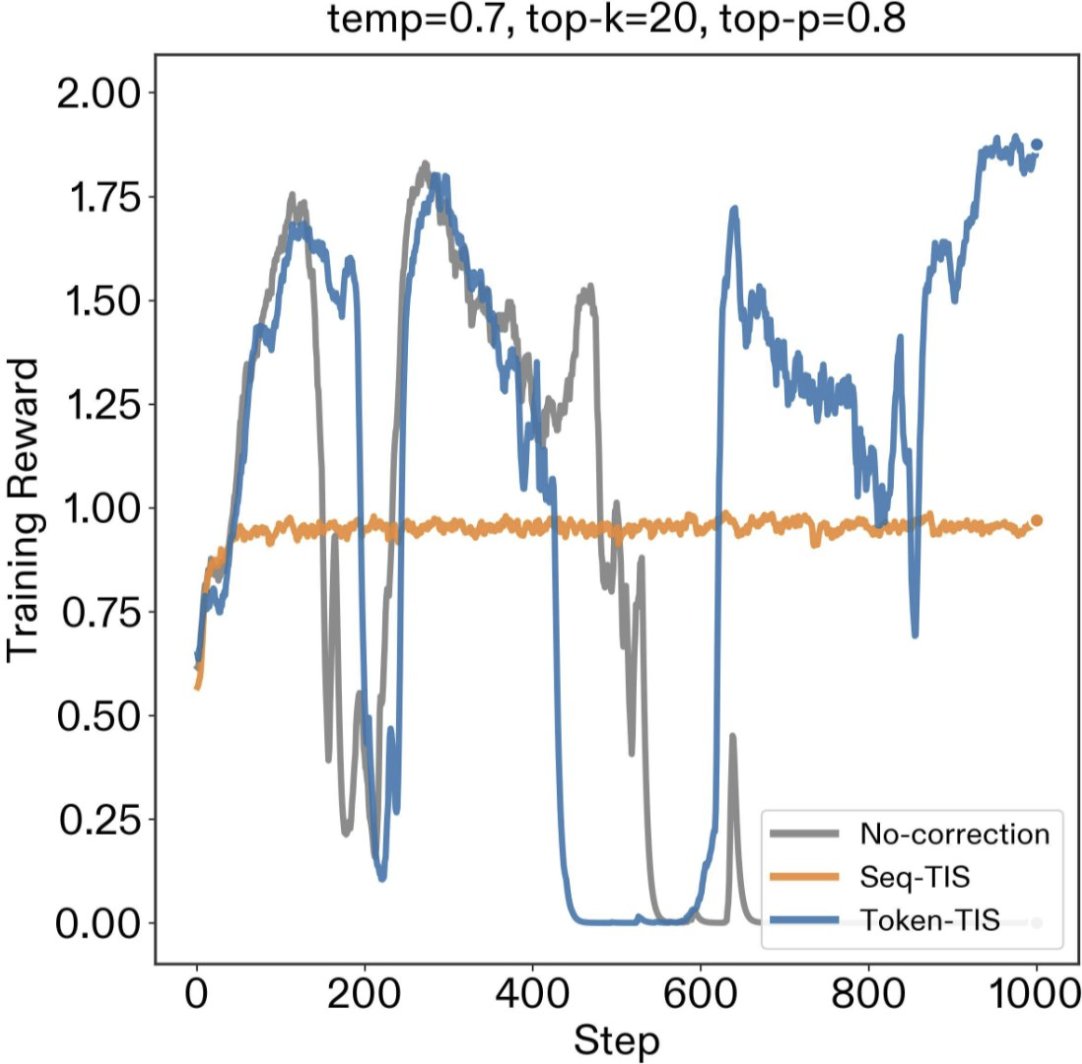
1. Batch grading reduces cost by ~1 OOM
2. Small models reduce cost by ~2 OOM
In non-verifiable RL, where judge latency blocks samples reaching the trainer, judge selection is a crucial knob for training efficiency.
Medicine:
x.com/bertgodel/status/20614…

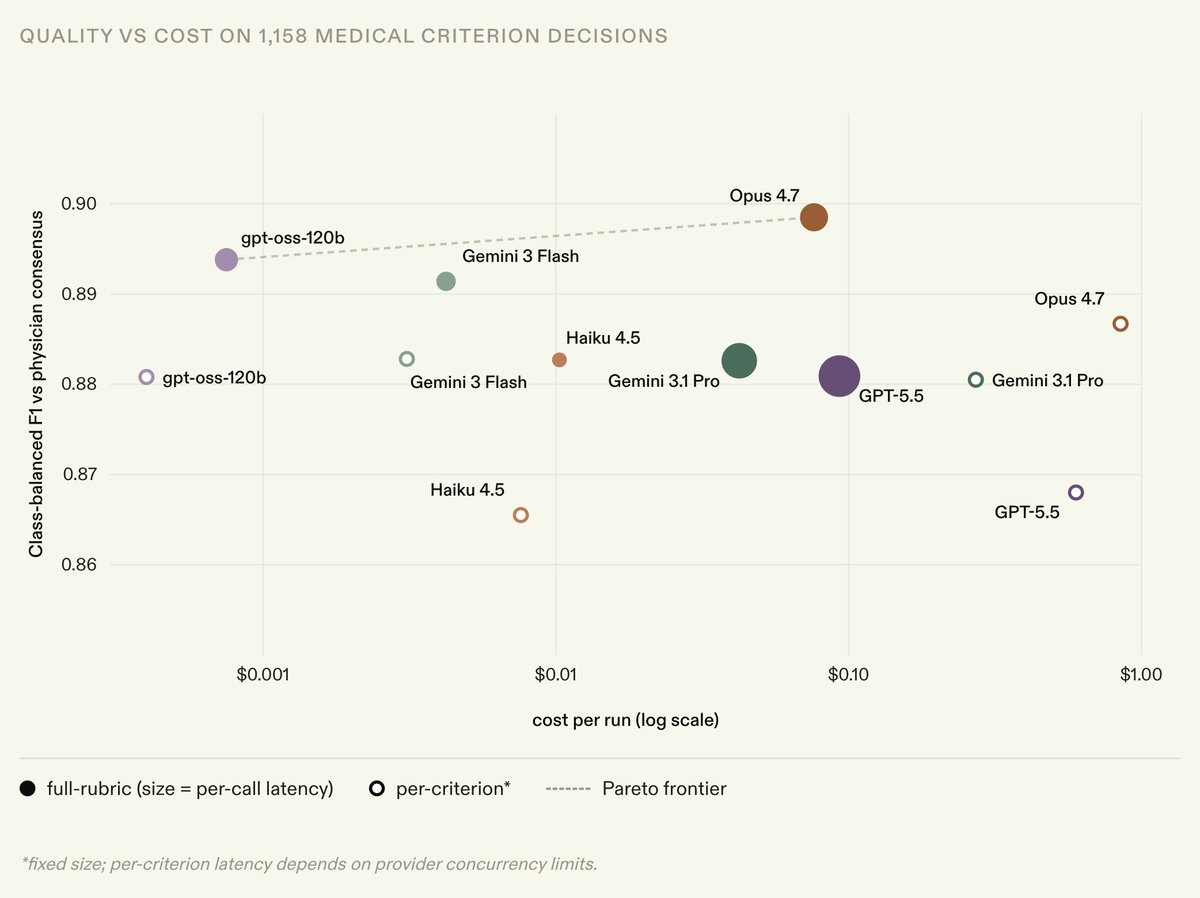
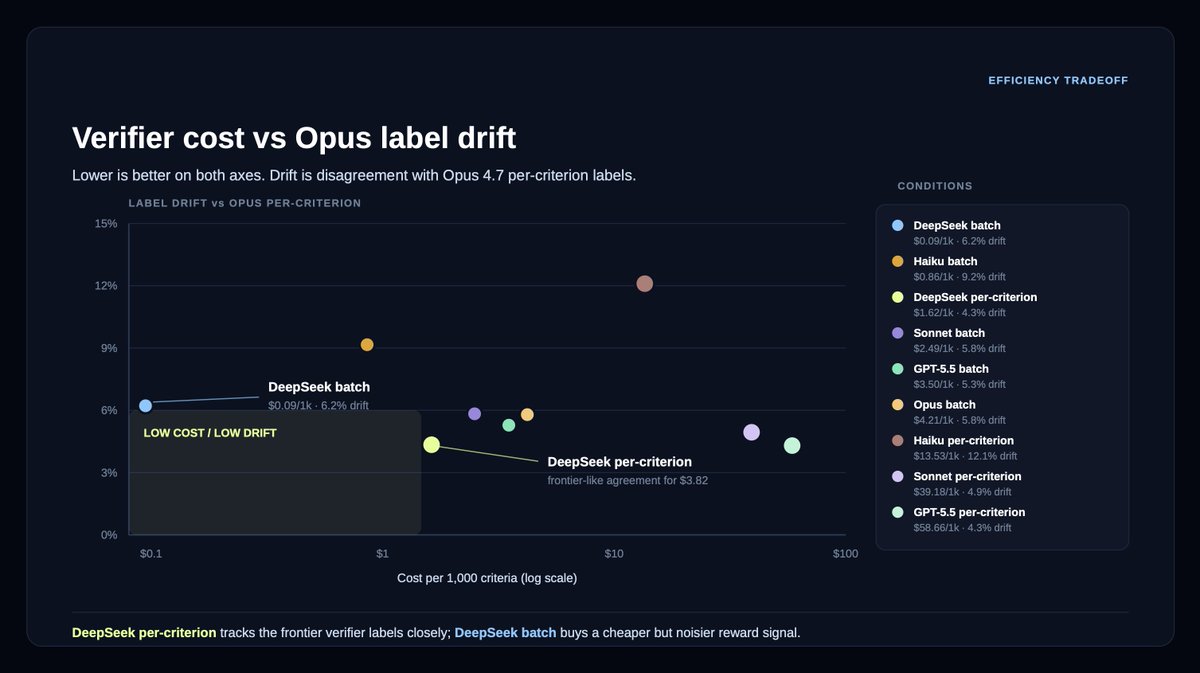
Can we design legal agent verifiers that are up to 1,000x cheaper?
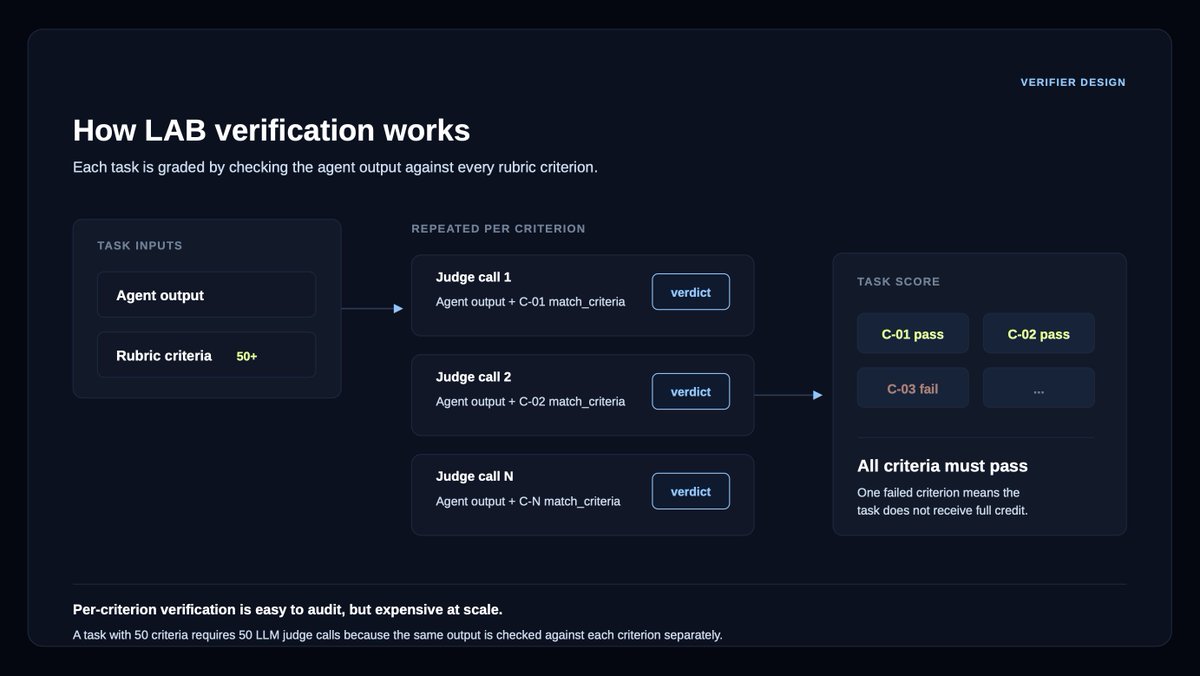
Verifiers are LLM judges that check an agent’s work against rubric criteria: they're used both in agent benchmarking and as reward signal in post-training.
But verifiers can be a bottleneck at scale.
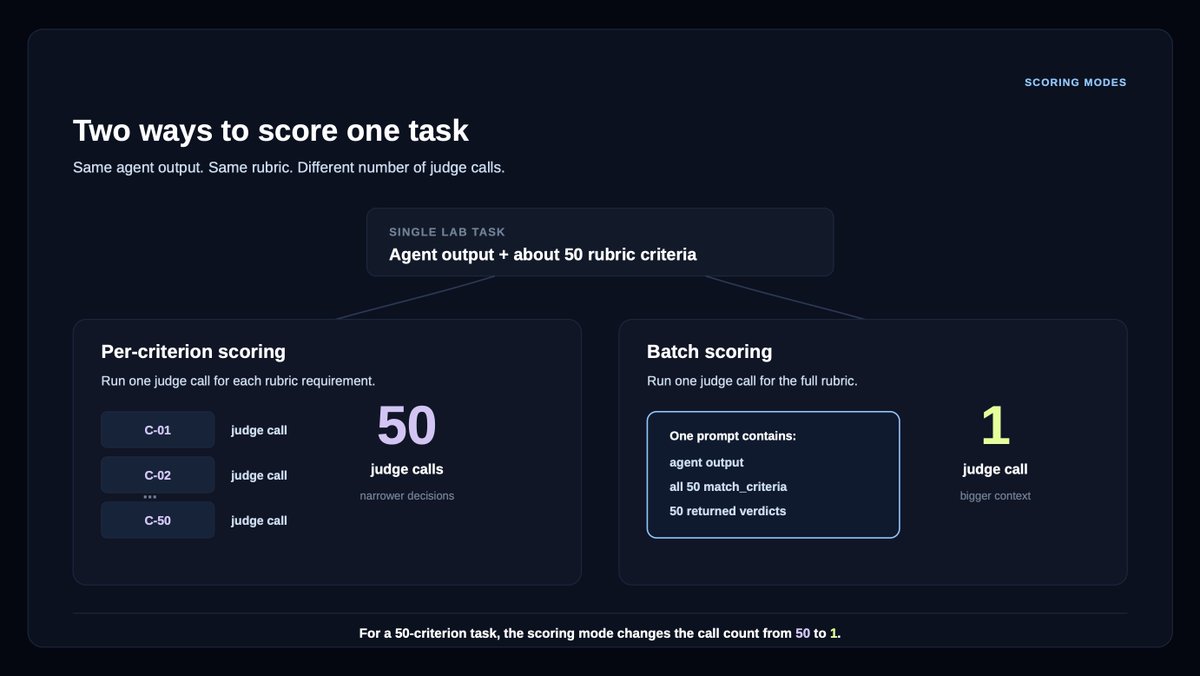
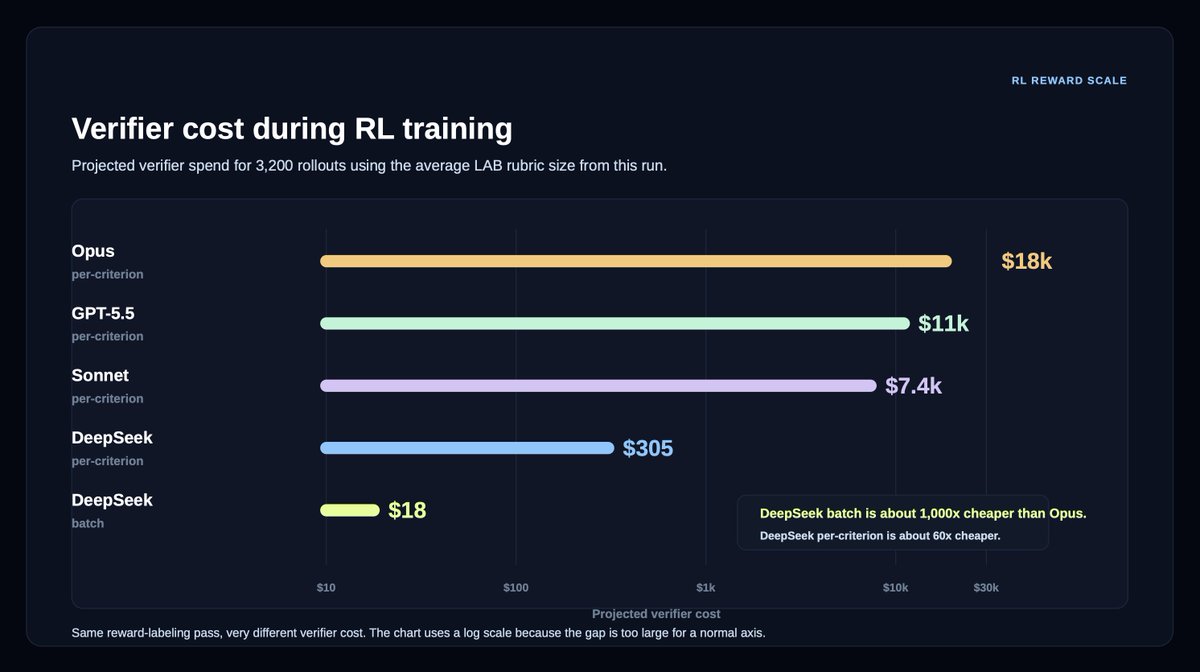
For example, our Legal Agent Benchmark (LAB), comprising 1,200 legal tasks across 24 different practice areas, requires grading an average of 50 rubric criteria per answer.
We partnered with @LangChain Labs to design more efficient verifiers for LAB, comparing batch vs per-criterion scoring and open/cost-efficient models against Opus 4.7.
The results were surprising:
DeepSeek v4 Flash preserved much of the Opus 4.7 verifier signal with 94-96% agreement, between batch mode and per-criterion mode.
This came with a massive reduction in cost: 18x cheaper on per-criterion verification, and ~1,000x cheaper on batch verification.
In an RL setting with 3,200 rollouts, the cost of verification drops from $18,000 to $18.
1
9
23
3,258
Daanish Khazi retweeted

Jun 1
LLM judges inject their own priors into grading signals, but good rubric design can combat that to align outcomes with human graders:
"Explicit rubrics remove the interpretative burden on the grader by moving verification into written criteria: what evidence earns credit, which thresholds matter, and which errors penalize reward."
Jun 1
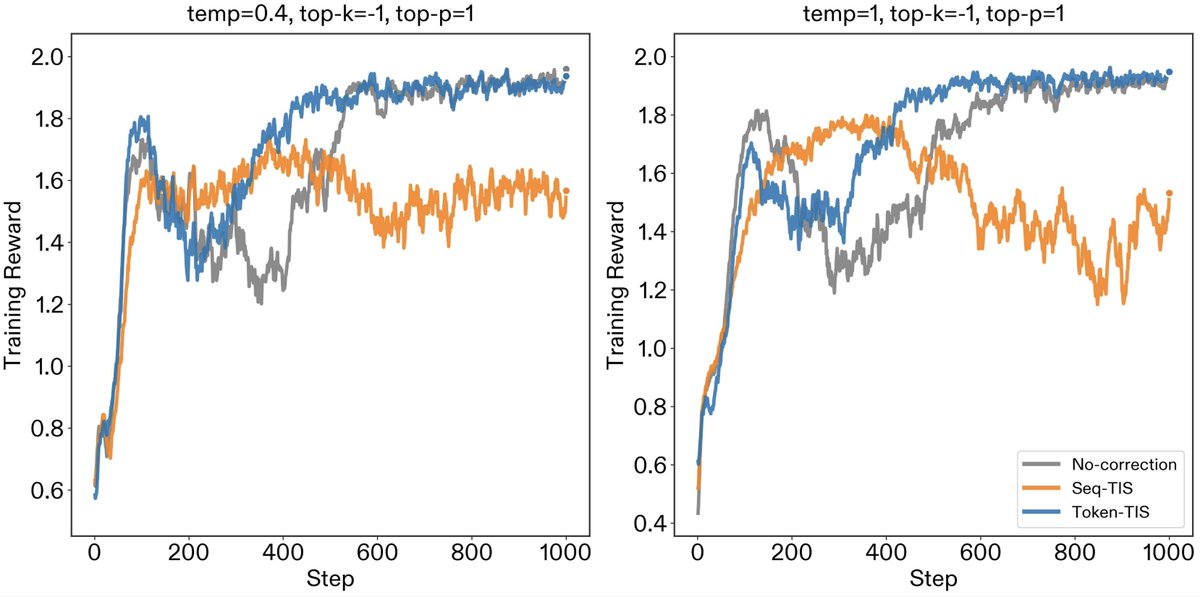
In our post, we motivate how we think about rubric design and detail ablations across reasoning effort, temperature, and judge prompt.
Read the full writeup here:
llmdata.com/blog/rubric-judg…
3
6
356
Jun 1
New post: “Notes on Choosing a Rubric Judge”
A practical cost/latency/performance question: Given a well-specified rubric, how strong does your grader model need to be for evaluation and RL?
1
10
41
5,158
Jun 1
In our post, we motivate how we think about rubric design and detail ablations across reasoning effort, temperature, and judge prompt.
Read the full writeup here:
llmdata.com/blog/rubric-judg…
2
13
708
Daanish Khazi retweeted

May 27
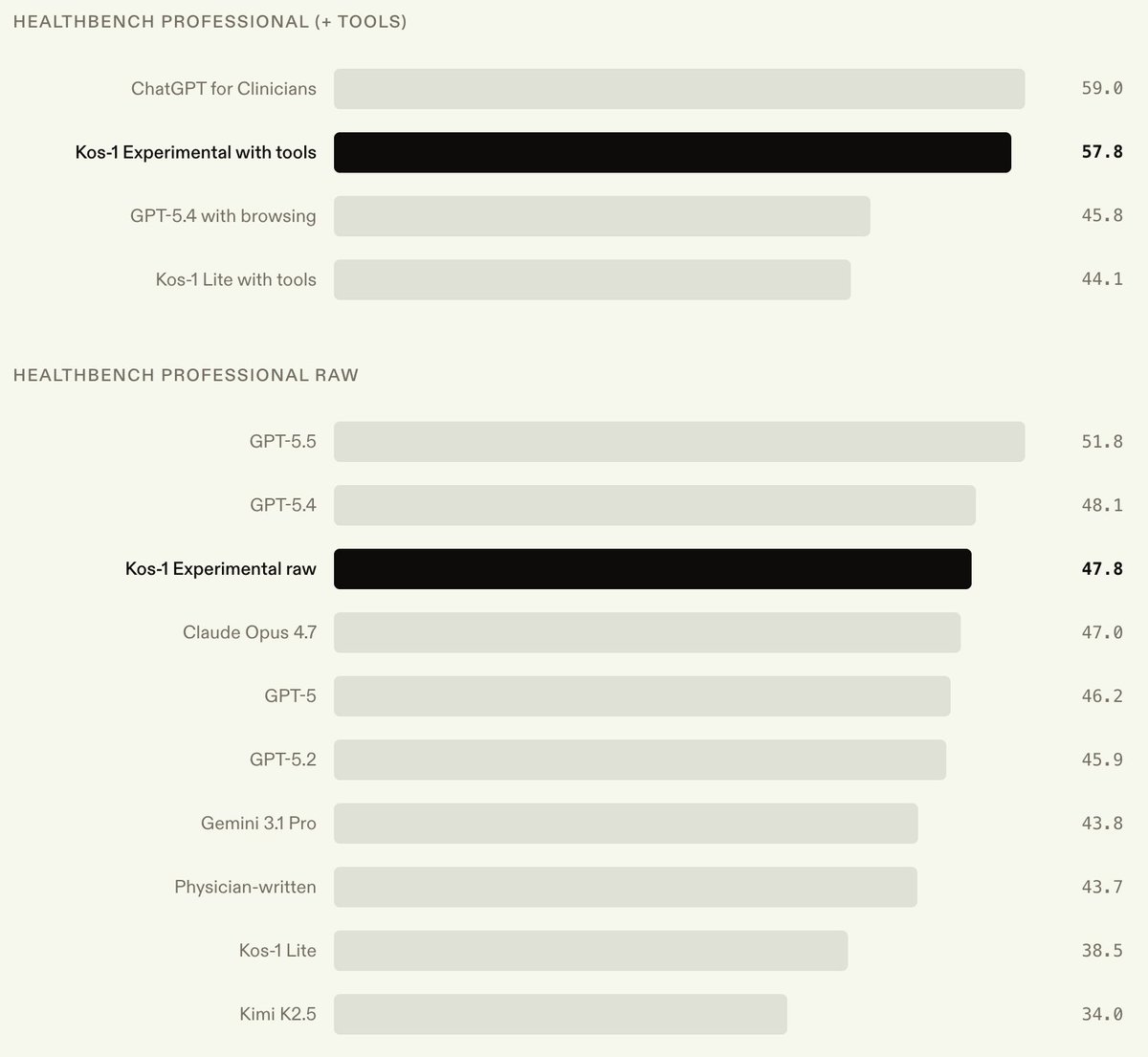
The full write up here is worth reading. A post-trained open source model is nearly as good as OpenAI’s best models on its own medical benchmark.
Shows again that the agent harness is at least as important as the AI that uses it.
May 26
Full writeup:
llmdata.com/blog/kos-1-exper…
1
2
11
928
May 26
We're releasing early results from training Kos-1 Experimental, a Kimi K2.5 checkpoint post-trained on the same medical RL data we used for Kos-1 Lite.
As clinical workloads become more agentic, we wanted a model that pairs medical domain knowledge with tool-calling knowhow.
4
16
48
3,682
May 26
To scale non-verifiable RL, we ran hundreds of experiments on judge alignment with human preferences. We are releasing follow up work this week on rubric design & LLM judge selection.
1
8
268